
AWS: CloudFormation 삭제 실패와 비용 환불기
AWS 실습에서 의도치 않은 요금이 발생하고, 환불을 받기까지의 경험을 기록한다. CloudFormation 스택 삭제가 silent하게 실패해서 5일간 비용이 새어나간 이야기, AWS Support에 지원 사례를 생성해 부분 환불을 받은 이야기, 그리고 이 경험에서 얻은 교훈을 정리해 본다.
TL;DR
- AWS EKS GitOps SaaS Workshop을 셀프 프로비저닝해서 실습한 후, CloudFormation 스택을 삭제했으나 silent하게 실패했다
- 삭제 실패를 모른 채 5.5일간 리소스가 방치되었고, 카드 결제 알림으로 뒤늦게 인지했다
- 수동 정리 +
FORCE_DELETE_STACK으로 스택 삭제를 완료했으나, DELETE_COMPLETE 이후에도 잔존 리소스가 남아 있었다 - AWS Support에 부분 환불(의도적 사용분은 본인 책임 인정)을 요청해, 4월 $186.43 카드 환불 + 5월 $110.87 크레딧, 총 $297.30 환불에 성공했다
- Budget, CloudWatch billing alarm, 리소스 sweep 스크립트, 비용 감사 도구 등 재발 방지 조치를 마련했다
배경
이전 포스트에 정리한 AWS 공식 워크숍 Building SaaS Applications on Amazon EKS using GitOps을 셀프 프로비저닝해서 실습했다. 스터디를 진행해 주신 AWS SA 분께서 감사하게도 워크숍 환경을 제공해 주셨는데, self-service도 가능하기에 제공 받은 워크숍 환경에서의 실습을 마친 뒤 직접 프로비저닝해봤다. 그게 화근이었다.
워크숍 가이드에는 self-service 시 비용이 청구될 수 있다는 안내 문구가 있었다. 그런데 이게 하루에 얼마 정도 될 것인지에 대해서는 전혀 생각하지 않았다. 나중에 확인해 보니, 이 워크숍이 프로비저닝하는 리소스 규모는 다음과 같았다.
| 리소스 | 상세 | 시간당 비용 |
|---|---|---|
| EKS 클러스터 | 컨트롤 플레인 | $0.10 |
| EC2 (노드그룹) | m5.large × 3~4 | $0.116 × 4 = $0.464 |
| NAT Gateway | 1개 | $0.045 + 데이터 처리비 |
| Load Balancer | NLB 2개 + Classic ELB 1개 | $0.03~0.05 × 3 |
| 기타 | EBS, CloudWatch, Route 53, KMS 등 | 소소하게 누적 |
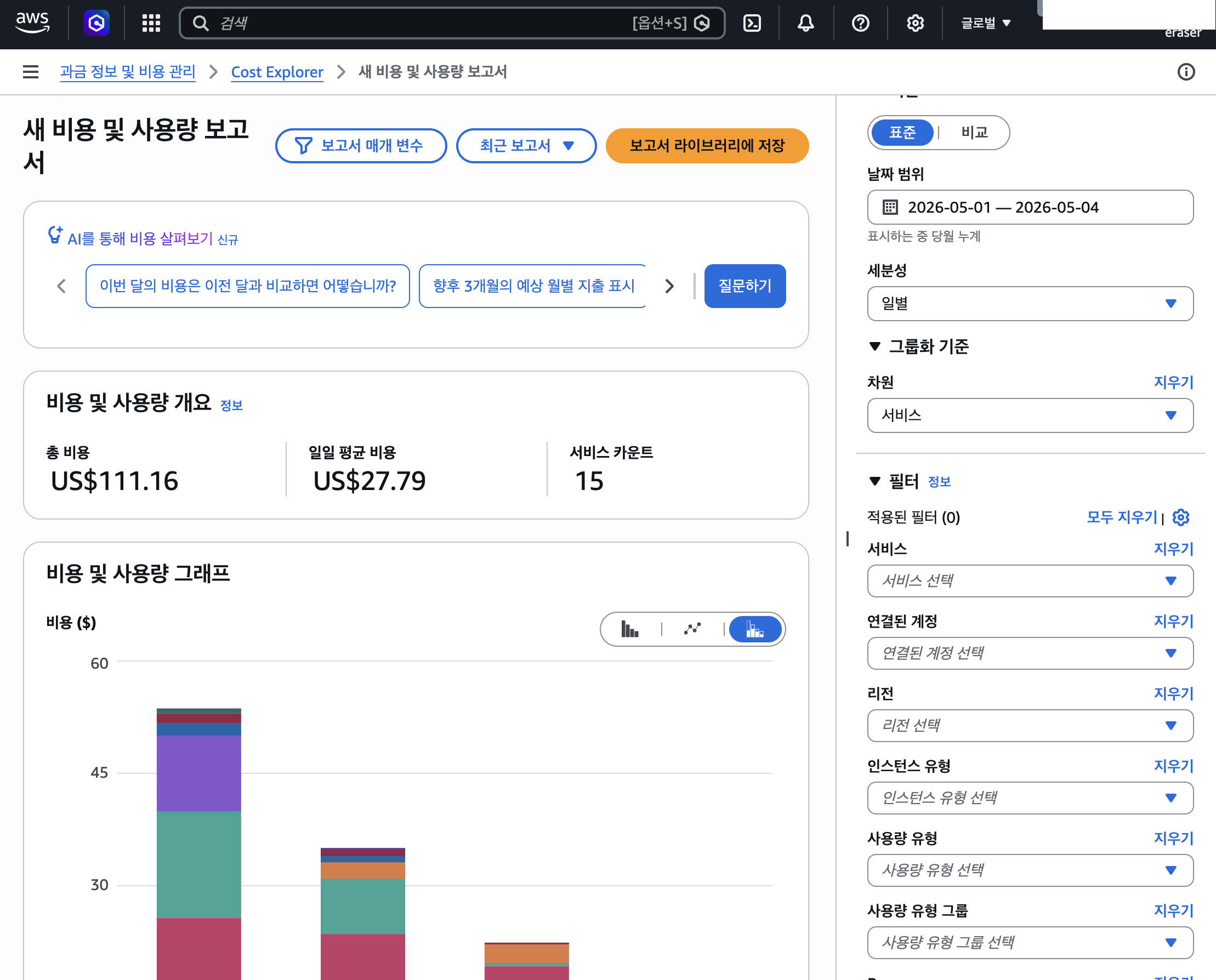
대략 하루 $40~50, 그러니까 한 달 방치하면 $1,200 이상이 나올 수 있는 규모였다. 실제로 삭제 실패 후 4일간의 Cost Explorer 청구 데이터가 $186.43(일 평균 약 $46.6)이었으니, 이 추정은 정확했다. 이 정도 비용이 발생할 수 있다는 인지가 있었다면, 삭제 후 결과를 확인하지 않고 넘어가는 안일한 대처는 하지 않았을 것이다.
타임라인
전체 흐름을 먼저 요약하면 다음과 같다.
- 4/24 : 스택 생성, 실습 시작
- 4/27 : 삭제 시도 후 출근 (Silent Failure)
- 5/2 오전 : 카드 결제 알림 수신
- 5/2 저녁 : 2차 삭제 실패, 수동 정리, DELETE_COMPLETE
- 5/2 밤 : 지원 사례 생성, Budget/CloudWatch 설정
- 5/4 : 잔존 리소스 추가 발견, 수동 삭제
- 5/6 : 환불 승인 (총 $297.30)
4/24: 스택 생성
eks-saas-gitops-vscode CloudFormation 스택을 생성하고 워크숍 실습을 시작했다. 스택은 VS Code 서버 환경을 포함한 EC2 인스턴스, EKS 클러스터, 네트워킹 리소스 등을 한꺼번에 프로비저닝한다.
다만 이 워크숍이 실제로 만드는 리소스는 CloudFormation 스택 안에만 있는 게 아니다. EKS 클러스터가 올라온 뒤 워크숍 스크립트와 Karpenter, Kubernetes Controller 등이 스택 밖에서 추가 리소스를 생성하는데, 이 다층 구조가 나중에 문제의 핵심이 된다.
4/27 09:44: 삭제 시도 → Silent Failure
실습을 마치고, CloudFormation 콘솔에서 스택 삭제를 요청한 뒤 출근했다. 당연히 삭제가 정상적으로 진행될 것이라고 생각했다.
그런데 스택은 DELETE_FAILED 상태로 silent하게 실패했다. 사유는 The following resource(s) failed to delete: [VPC]. VPC에 의존성을 가진 리소스(ENI, Load Balancer 등)가 정리되지 않아 VPC를 삭제할 수 없었던 것이다.
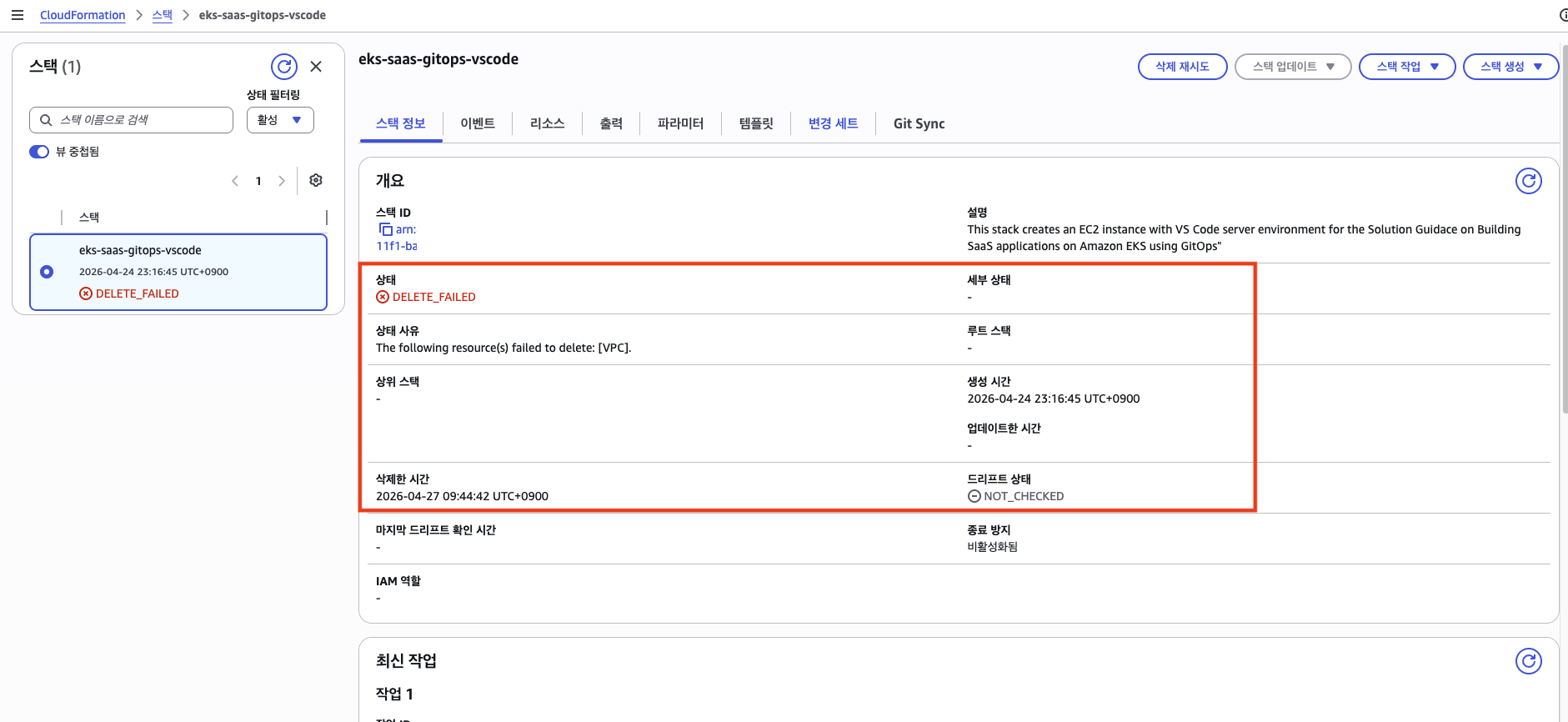
문제는 이 실패에 대해 아무런 알림이 없었다는 것이다. 이메일도, 콘솔 알림도, 어떤 능동적인 알림도 수신하지 못했다. 내가 알림을 설정하지 않았으니 당연한 일이긴 하지만, 결과적으로 삭제 실패 사실을 전혀 인지할 수 없었다.
5/2: 카드 결제 알림
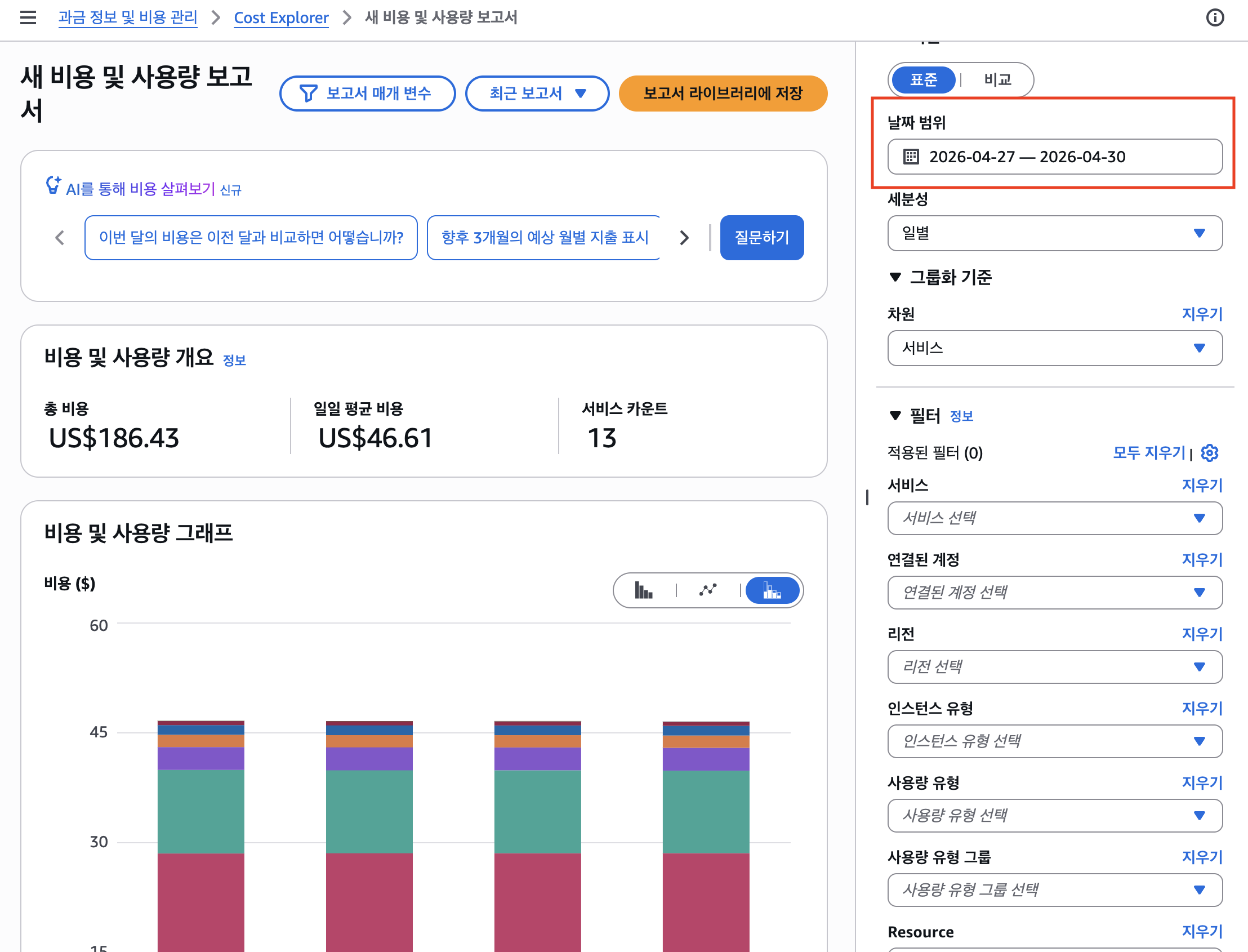
4/27부터 5/2까지 5.5일간, 삭제에 실패한 리소스들이 계속 실행되며 비용이 발생하고 있었다. 그러다 5/2에 카드 결제 알림을 수신하고 나서야 비로소 상황을 인지했다. 화들짝 놀라서 Cost Explorer를 확인해 보니, 4/27~4/30 기간에만 $186.43이 발생해 있었다.
5/2 19:41: 2차 삭제 시도 → 또 실패
즉시 CloudFormation 콘솔에서 스택 삭제를 다시 시도했다. 그런데 동일한 사유로 또 실패했다. DELETE_FAILED, The following resource(s) failed to delete: [VPC]. 한 번도 아닌 두 번 같은 이유로 실패한 것이다.
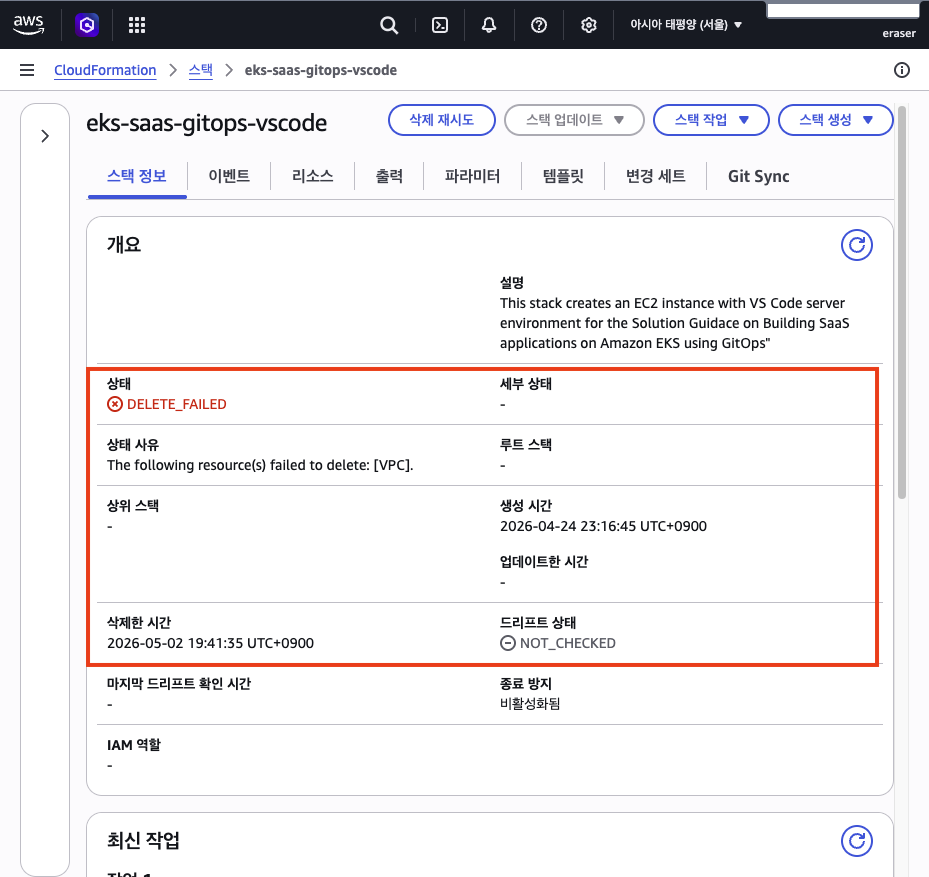
이 시점에서 CloudFormation이 VPC 의존성을 자체적으로 해결하지 못한다는 것을 깨달았다. AWS re:Post의 DELETE_FAILED 관련 Knowledge Center 문서를 보면, 스택 외부에서 생성된 리소스(예: 스택의 보안 그룹에 연결된 외부 ENI)가 의존성을 잡고 있으면 CloudFormation이 삭제하지 못한다고 설명되어 있다. 댓글에도 “왜 CloudFormation은 이렇게 끔찍한 서비스인가”, “고객 대신 missing role을 생성해 주면 좋겠다” 같은 비슷한 좌절을 겪은 사람들의 목소리가 달려 있었다.
5/2 20:00~: 수동 정리
Claude의 도움을 받아 VPC 삭제를 막고 있는 dangling 리소스를 직접 정리했다. AWS CLI로 진단해 보니 다음 리소스들이 살아 있었다.
- EKS 클러스터:
eks-saas-gitops(노드그룹baseline-infra, m5.large × 4) - Network Load Balancer 2개 (ArgoWorkflows, Kubecost용)
- Classic Load Balancer 1개
- NAT Gateway 1개
- ENI(Elastic Network Interface) 22개 이상
이 리소스들을 의존성 순서대로 삭제했다.
- Load Balancer 3개: EC2 콘솔에서 직접 삭제
- NAT Gateway:
aws ec2 delete-nat-gateway명령으로 삭제 - EKS 노드그룹 → 클러스터: 노드그룹 삭제 완료 후 클러스터 삭제
- 잔여 ENI: 위 리소스 삭제 후 자동 release된 ENI 확인
5/2 20:58: FORCE_DELETE_STACK → DELETE_COMPLETE
수동 정리 후 FORCE_DELETE_STACK 옵션으로 CloudFormation 스택 삭제를 재시도했다.
aws cloudformation delete-stack \
--stack-name eks-saas-gitops-vscode \
--deletion-mode FORCE_DELETE_STACK \
--region ap-northeast-2
이번에는 DELETE_IN_PROGRESS 상태로 정상 진입했고, 최종적으로 DELETE_COMPLETE가 확인되었다.
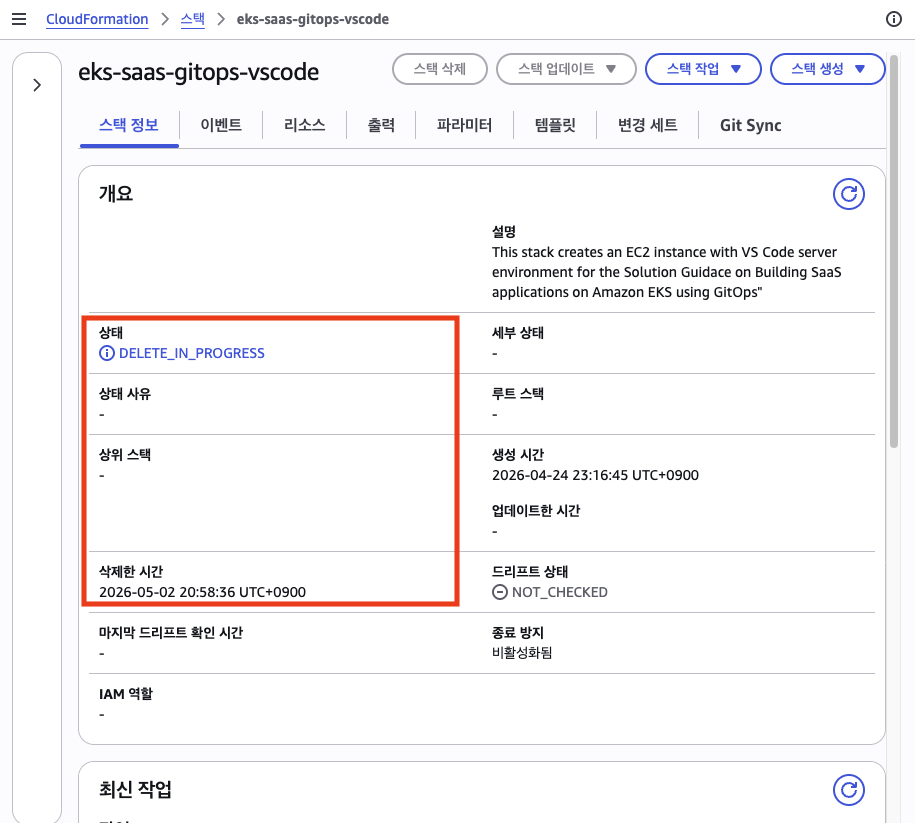
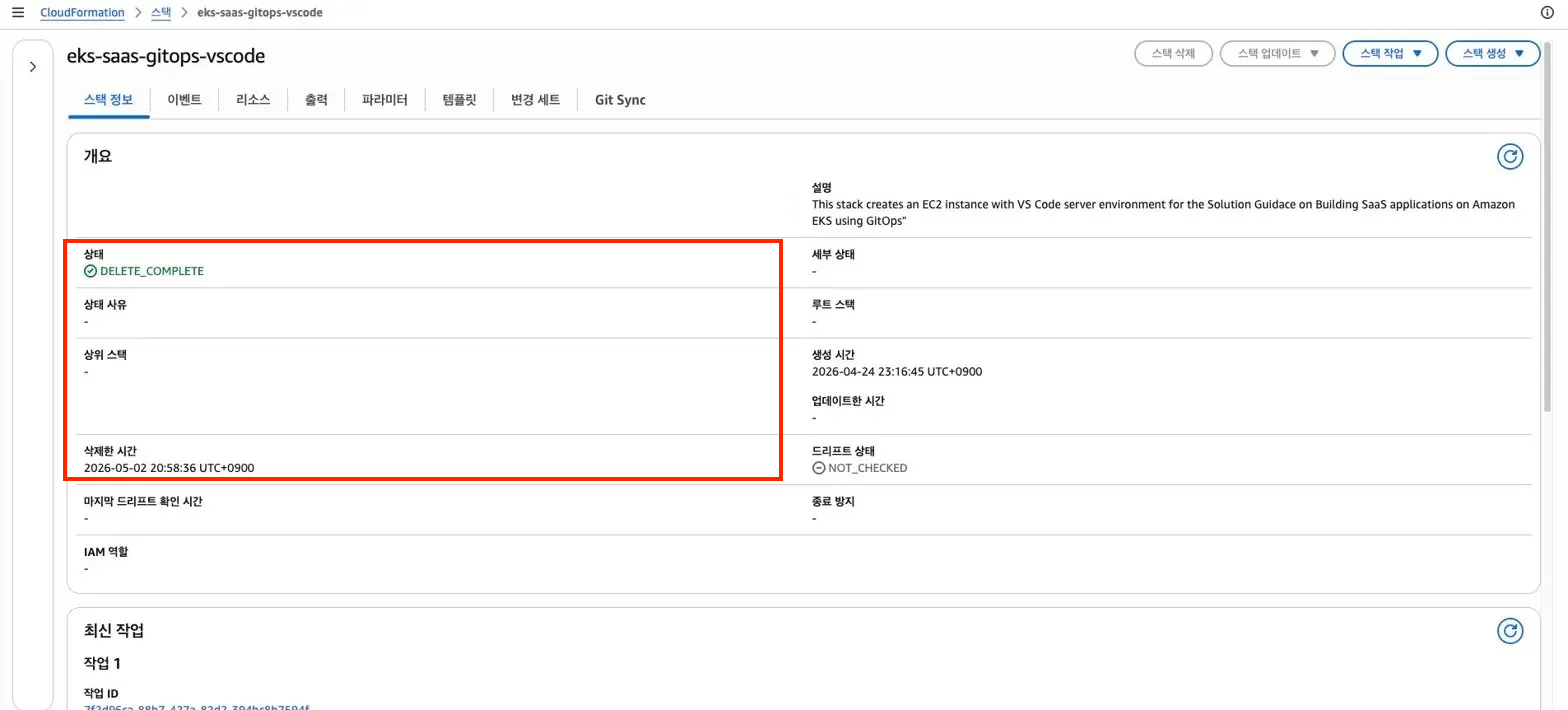
5/4: DELETE_COMPLETE 이후에도 잔존 리소스 발견
안심하고 있었는데, 이틀 뒤에 다시 리소스 sweep을 돌려보니 EC2 인스턴스 2대가 아직 running 상태로 남아 있었다. CloudFormation 스택이 DELETE_COMPLETE가 되었는데도 말이다.
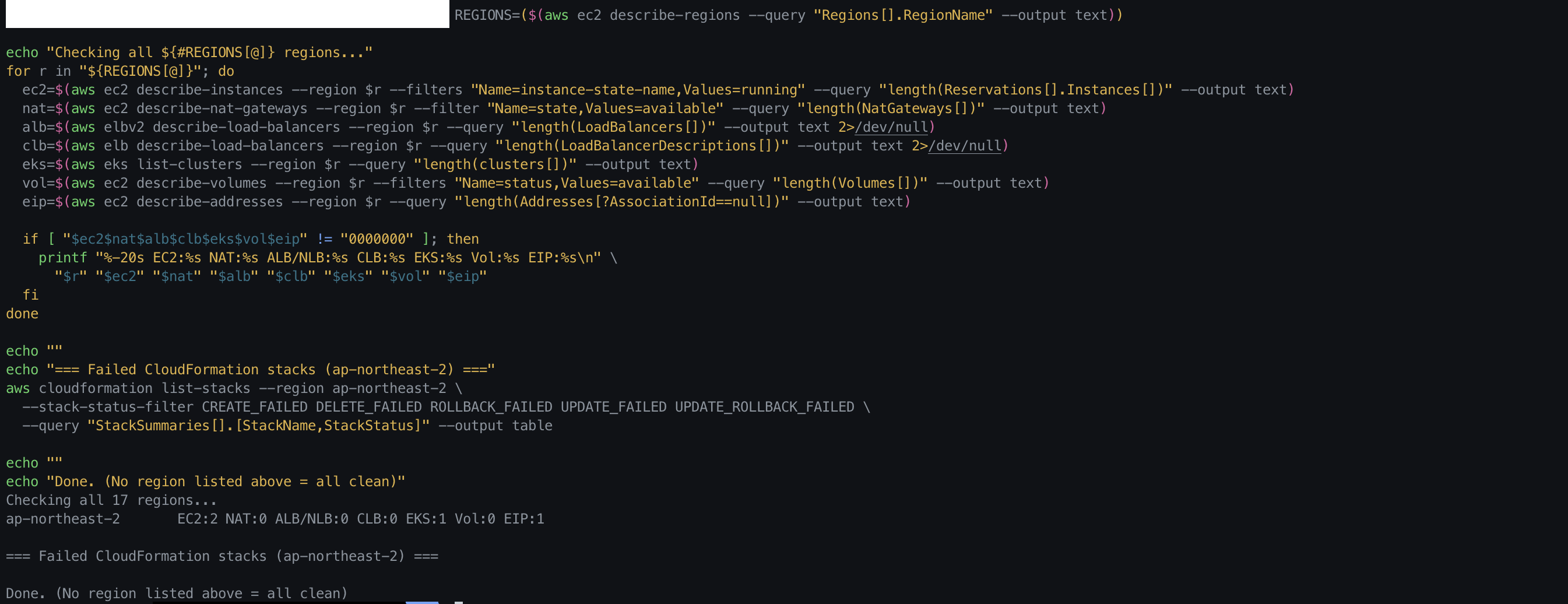
정체를 확인해 보니 다음과 같았다.
| 인스턴스 | 타입 | 정체 |
|---|---|---|
eks-saas-gitops-gitea |
m5.large | 워크숍의 Gitea(self-hosted Git) 서버. CloudFormation 외부에서 별도 생성됨 |
karpenter-node |
c5a.xlarge | Karpenter(EKS 노드 자동 스케일러)가 자체적으로 생성한 노드 |
여기에 더해 미부착 EBS 볼륨 2개(32GB gp2)와 미연결 Elastic IP 1개도 남아 있었다. 모두 즉시 삭제했다.
왜 이런 일이 발생했는지를 이해하려면, 워크숍이 만드는 리소스의 다층 구조를 알아야 한다.
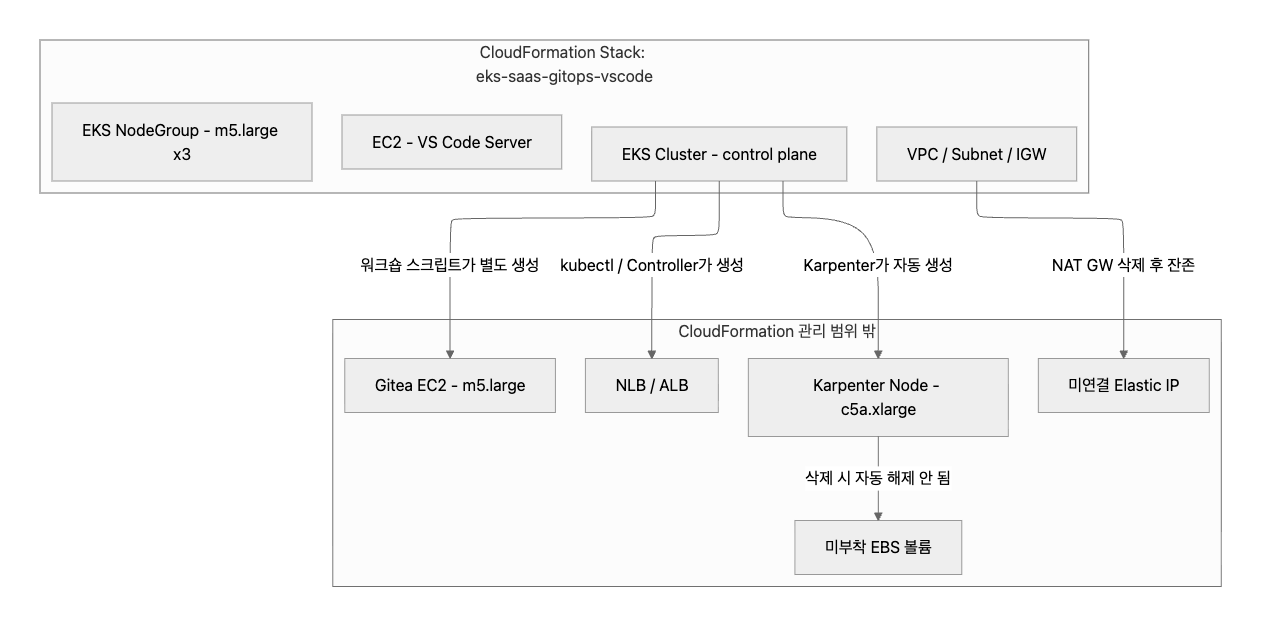
CloudFormation 스택을 삭제하면 위쪽 박스 안의 리소스만 정리된다. 아래쪽 박스의 리소스는 CloudFormation이 존재 자체를 모르기 때문에, 스택이 DELETE_COMPLETE가 되어도 그대로 남아서 비용을 발생시킨다.
CloudFormation
DELETE_COMPLETE≠ 모든 리소스가 삭제됨
이것이 이 경험에서 얻은 핵심 교훈이다.
AWS Support 지원 사례 생성
리소스 정리와 병행하여 AWS Support Center에 지원 사례를 생성했다.
사례 생성 과정
환불 요청은 AWS Support Center에서 지원 사례를 생성하는 것으로 시작한다.
“사례 생성”을 누르면 기존의 폼 UI 대신 Amazon Q 기반 채팅 페이지(“Support 상호 작용 - 신규”)로 리디렉트되었다.
처음 보면 당황할 수 있는데, AWS가 최근 도입한 정상적인 새 UI다. 채팅 박스에 문제를 설명하면 Amazon Q가 먼저 해결을 시도하고, 자체적으로 해결할 수 없다고 판단하면 하단에 “케이스 생성” 버튼이 나타난다. 명시적으로 “케이스를 생성해 달라”고 요청하는 것도 방법인데, 나는 그렇게 했다.
“케이스 생성”을 누르면 케이스 생성 폼이 열린다. 계정 및 결제(Account and billing) 관련 케이스는 Basic Support plan에서도 무료로 생성할 수 있다.
- Type: Account and billing
- Service: Billing → Dispute a charge
- Severity: General question
메시지 전략: 부분 환불
환불 요청 메시지에서 가장 중요하게 생각한 것은 부분 환불 접근법이었다.
전체 기간에 대한 환불을 요청하는 것이 아니라, 의도적으로 사용한 기간의 비용은 본인이 책임진다고 먼저 명시했다. 구체적으로 다음과 같이 기간을 분리했다.
- 본인 책임 (환불 미요청): 4/24 23:16(스택 생성) ~ 4/27 09:44(1차 삭제 시도) → 워크숍 의도적 사용
- 환불 요청: 4/27 09:44(1차 삭제 시도) ~ 5/2(정리 완료) → CloudFormation silent 삭제 실패로 인한 의도치 않은 비용
이런 접근이 환불 가능성을 높인다고 판단한 이유는 다음과 같다.
- 합리성: “내가 쓴 건 내가 낸다, 시스템 한계로 발생한 건 봐달라”는 입장은 거절할 명분이 적다
- 신뢰도: 전액 환불 요청보다 부분 환불 요청이 support engineer에게 합리적인 인상을 준다
- 프레이밍: “환불 받으려는 요구”가 아닌 “공정한 조정 요청”으로 보인다
메시지는 영문으로 작성했다. AWS Support의 환불 케이스는 글로벌 billing 팀이 처리하는 경우가 많아 영문이 처리가 빠르다는 이야기를 들은 적이 있어서였다.
그런데 사례 생성 시 응답 언어를 한국어로 선택해 둔 것을 몰랐고, 1차 응답이 한국어로 왔다. 이후 양식 회신도 한국어로 작성해서 진행했는데, 처리 속도에 차이를 느끼지는 못했다. 첫 메시지 작성부터 환불 승인까지 총 4일(영업일 기준 3일)이 걸렸으니, 한국어로 진행해도 충분히 빠르다.
첨부 파일은 최대 3장까지만 가능해서, 핵심 증거 3장을 선정했다.
- 2차 삭제 시도 후
DELETE_FAILED스크린샷 (반복 실패의 객관적 증거) - 최종
DELETE_COMPLETE스크린샷 (정리 완료 증명) - Cost Explorer 일별 비용 그래프 (피해 규모 증명)
폼 하단에는 “선택 사항”으로 표시된 추가 입력 필드(Service Name, Total Charge Amount, Reason for contacting us, Actions to stop this charge 등)가 있는데, 이것도 빠짐없이 작성했다. 생성한 케이스를 분류하고 검토할 때 이 필드들이 구조화된 데이터로 쓰이므로, 본문에 잘 써놨더라도 폼이 비어 있으면 우선순위가 떨어질 수 있다는 말을 들었기 때문이다.

대화 요약
지원 사례의 대화는 크게 세 단계로 진행되었다.
1차 AWS 응답: 표준 비용 조정 폼 요청
AWS 고객지원팀에서 공동 책임 모델을 안내하면서, 비용 조정 신청을 위한 양식을 채워달라고 회신했다. 이때 회신에 다음과 같은 문구가 포함되어 있었다.
원칙적으로 AWS는 공동 책임 모델에 따라 계정 내에서 발생한 모든 비용에 대한 책임은 고객님께 있습니다. 그러나 AWS 서비스가 아직 익숙하지 않으신 고객님들의 상황을 고려하여, 예외적으로 1회에 한해 비용 조정을 지원해 드리고 있습니다.
즉, AWS의 비용 조정은 원칙적으로 1회성 예외 조치다. “요청하면 언제든 환불된다”고 오해해서는 안 된다. 같은 계정에서 같은 사유로 반복 요청하면 거절될 가능성이 높다.
요청 항목은 다음과 같았다.
[1]비용 조정을 요청하는 기간 / 서비스 / 금액 (세전/USD)[2]비용 발생 시점으로부터 접수까지 시간이 소요된 사유[3]관련 문서 확인, 요금 구조 검토 동의, 리소스 종료 프로세스 생성 여부
본인 회신: 4월 + 5월 세전 금액, 지연 사유, 동의 사항 작성
4월분($186.43)과 5월분($110.87)을 서비스별로 분리해서 작성하고, 삭제 실패 사실을 인지하지 못한 경위를 설명했다. 특히 5/4에 추가로 발견한 잔존 리소스(EKS 클러스터, Gitea EC2, Karpenter 노드)에 대한 내용도 포함했다. 이는 단순 사용자 부주의가 아닌, 워크숍의 cleanup 절차가 CloudFormation의 관리 범위를 넘어서는 리소스를 충분히 안내하지 못한 구조적 문제임을 보여주는 증거였다.
Cost Explorer 스크린샷도 추가 첨부했다.
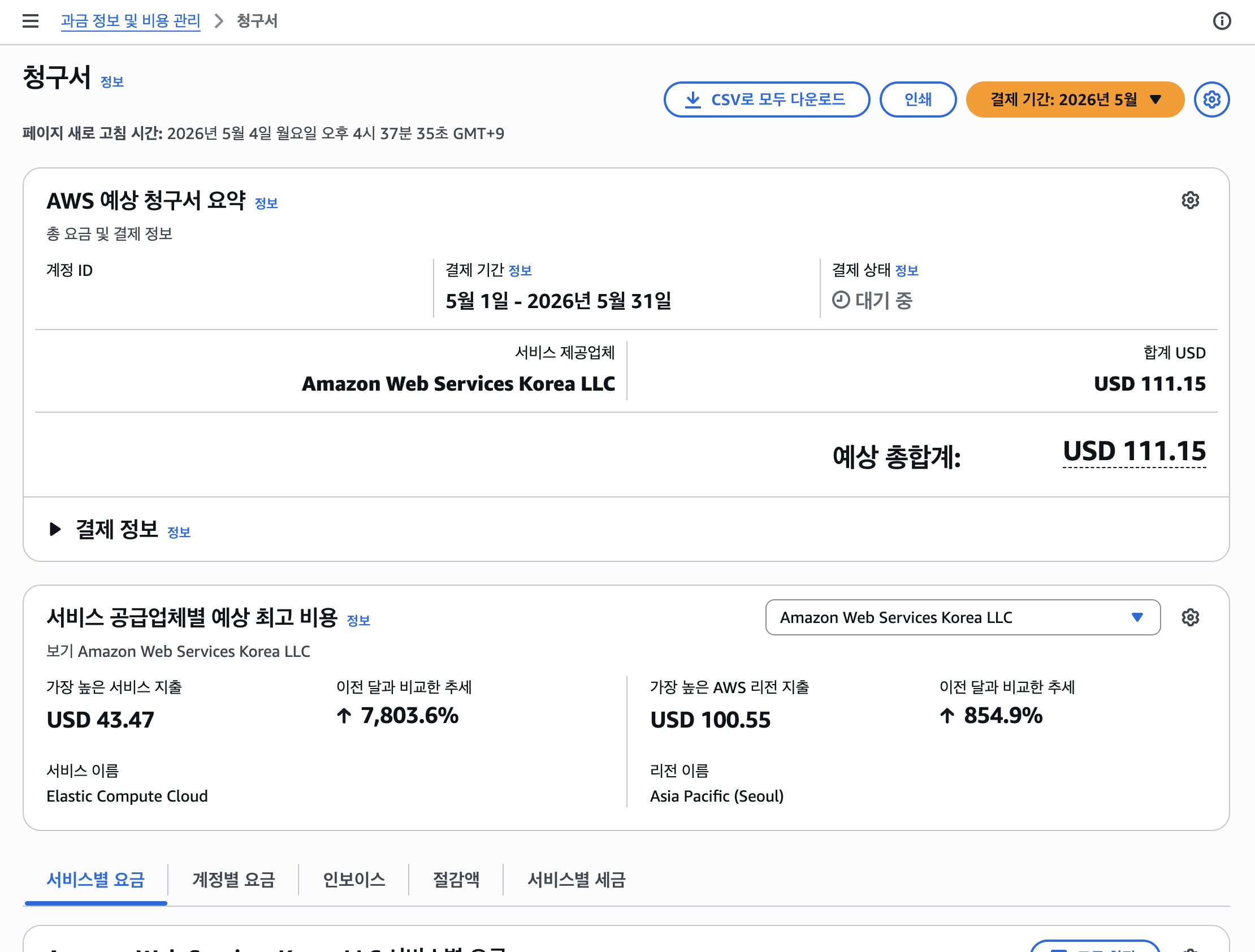
최종 결과: 환불 승인
회신을 보낸 후 이틀 정도 조마조마하게 기다렸다. 부분 환불이라는 접근이 맞았는지, 혹시 거절되면 어떻게 해야 하나, 별별 생각이 다 들었다. 그러다 5/6에 최종 응답을 받았다.
AWS 계정 ID : XXXXXXXXXXXX
* 2026년 4월 : $ 186.43 - 카드 환불
* 2026년 5월 : $ 110.87 - 크레딧 발급
4월분 $186.43은 카드 환불로, 5월분 $110.87은 5월 말 비용 정산 시 자동 차감되는 크레딧으로 처리되었다. 총 $297.30 환불에 성공했다.
개인적인 감상을 덧붙이면, AWS Support의 대응이 생각보다 빠르고 친절해서 놀랐다. 첫 메시지부터 최종 환불 승인까지 4일(영업일 3일)이었고, 회신 톤도 기계적이지 않고 상황을 이해하려는 느낌이었다. 환불 요청을 망설이고 있다면, 일단 사례를 생성해 보는 것을 권한다.
환불 팁
이번 경험을 통해 정리한, AWS에 비용 환불을 요청할 때의 팁이다.
리소스부터 완전히 정리하라
환불 메시지를 보내기 전에, 비용을 발생시키는 리소스를 먼저 100% 정리해야 한다. 리소스가 살아 있는 상태에서 환불을 요청하면, “리소스 정리부터 하세요”라는 회신이 오면서 처리가 늘어질 수 있다. 리소스 정리 완료 → Cost Explorer에서 비용 0 수렴 확인 → 그 다음에 메시지를 보내는 것이 순서다.
전액 환불보다 부분 환불을 고민하라
환불을 요청할 때 흔히 하는 실수는 발생한 비용 전액을 환불해 달라고 요청하는 것이다. 의도하지 않은 비용이니 다 돌려달라는 게 직관적으로 자연스럽긴 하다.
그런데 support engineer 입장에서 보면, 전액 환불 요청은 검토 부담이 크다. “이 사람의 책임이 정말 0%인가?”를 판단해야 하고, 결재를 올리기도 부담스럽다. 결과적으로 거절되거나, 일부만 승인되거나, 검토가 길어질 수 있다.
부분 환불 요청은 그 부담을 덜어준다. “내가 의도적으로 사용한 부분은 내가 낸다, 시스템 한계나 silent failure로 발생한 부분만 봐달라”는 입장은 다음과 같은 효과가 있다.
- 합리성: 책임 영역을 사용자가 먼저 분리해 주니, support engineer는 그 분리가 타당한지만 검토하면 된다
- 신뢰도: 자기 책임을 인정하는 태도 자체가 신뢰를 만든다
- 결재 용이성: “이 사람은 X 시점부터 Y 시점까지의 비용을 요청했고, 그 기간은 명백히 silent failure 구간이다”는 명료한 케이스가 된다
내 경우 4/24~4/27 09:44는 워크숍을 의도적으로 사용한 기간이었고, 그 부분의 비용은 환불 요청에서 제외했다. 그 결과 환불 요청 금액의 거의 100%가 승인되었다.
다만 부분 환불이 항상 정답은 아니다. 다음 경우에는 전액 환불을 시도해도 된다.
- AWS 시스템 자체 장애로 비용이 발생한 경우 (예: 서비스 결함으로 의도하지 않은 자원이 생성됨)
- 본인이 어떤 행위도 하지 않은 상태에서 비용이 발생한 경우
- 명백한 청구 오류
반대로, 본인의 부주의가 명백한 경우(예: 대용량 인스턴스를 잘못 띄워두고 잊은 경우)에는 부분 환불도 받기 어려울 수 있다. “내 책임은 어디까지이고, 시스템/구조의 한계는 어디부터인지”를 객관적으로 분리할 수 있을 때 부분 환불 전략이 효과적이다.
구체적 증거를 첨부하라
말로 설명하는 것과 스크린샷으로 보여주는 것은 신뢰도가 다르다. 다음 증거들이 효과적이다.
DELETE_FAILED스크린샷 (삭제 시도 시각 + 실패 사유가 담긴 것)- Cost Explorer 일별 비용 그래프 (피해 규모의 객관적 증거)
- 최종 정리 완료 스크린샷 (현재 비용이 더 이상 발생하지 않음을 증명)
- CLI sweep 결과 (전 리전에 잔존 리소스가 없음을 증명)
첨부 파일은 3장까지만 가능하므로, 핵심 증거를 잘 골라야 한다.
재발 방지 조치를 먼저 실행하고 명시하라
“다시는 이런 일이 없게 하겠다”는 말만으로는 부족하다. Budget 설정, CloudWatch billing alarm 설정 등 구체적인 조치를 이미 실행한 상태에서, 그 사실을 메시지에 명시하면 진정성이 전달된다. 메시지에 “configured”라고 적었으면 실제로 설정이 되어 있어야 한다. Support engineer가 가끔 verify하기도 한다.
공동 책임 모델을 인식하라
AWS는 공동 책임 모델(Shared Responsibility Model)을 강조한다. 계정 내에서 발생한 모든 비용에 대한 책임은 원칙적으로 사용자에게 있다. 이걸 모른 척하고 전적으로 AWS 탓으로 돌리면 역효과가 난다. 내 책임을 인정하되, 구조적 한계도 함께 지적하는 것이 설득력 있는 접근이다.
또한, AWS의 비용 조정은 “예외적으로 1회에 한해” 지원하는 것이라고 명시되어 있다. 한 번 환불받았다고 해서 다음에도 같은 결과를 기대할 수는 없다. 이 기회를 최대한 잘 활용해야 하고, 무엇보다 두 번째 기회가 필요 없도록 재발 방지에 힘써야 한다.
빠르게 대처하라
비용 발생을 인지한 시점부터 리소스 정리 → 증거 확보 → 지원 사례 생성까지의 속도가 빠를수록 좋다. “인지 즉시 모든 조치를 취했고, 당일 케이스를 접수했다”는 사실이 성실한 인상을 준다.
대응 조치
이 사건 이후 다시는 같은 일이 일어나지 않도록 여러 조치를 마련했다.
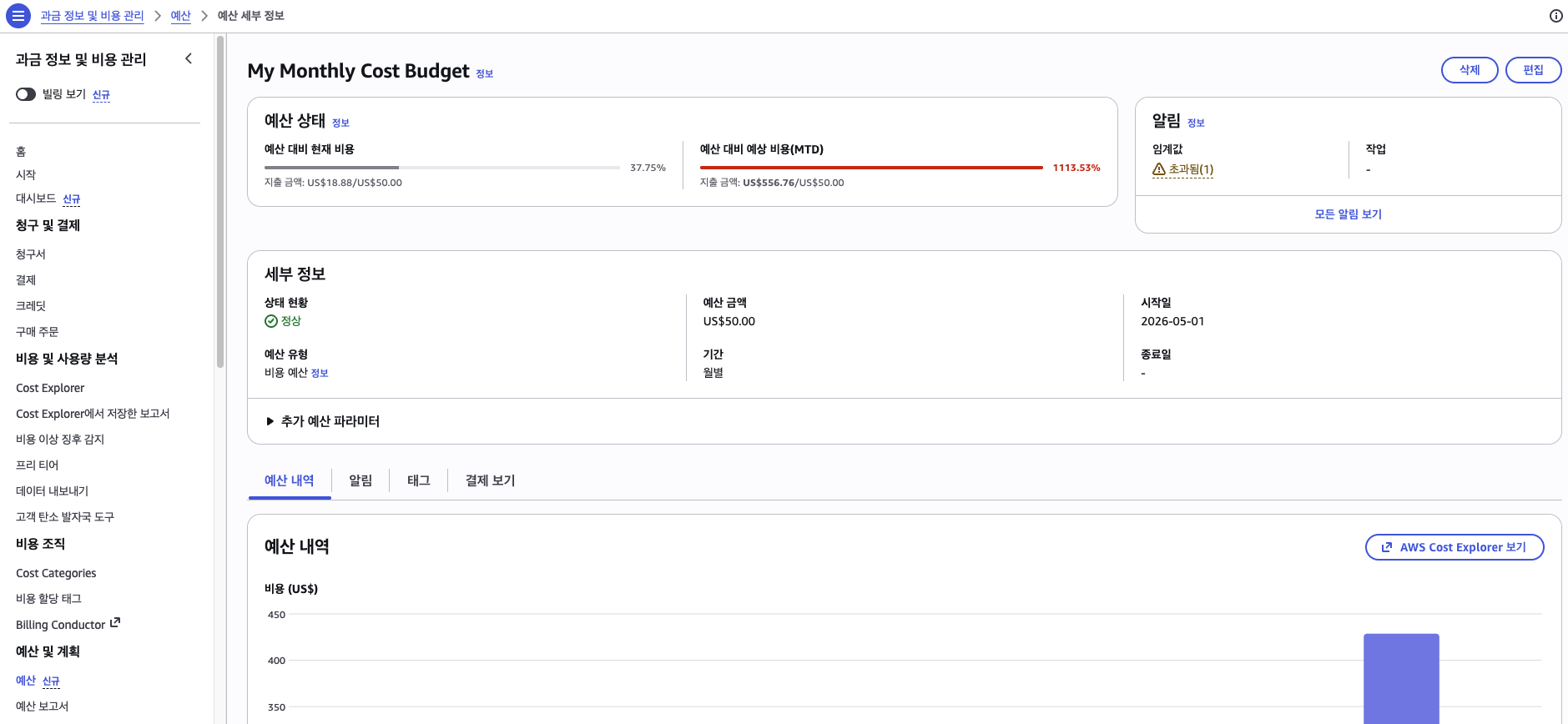
AWS Budgets
AWS Budgets에서 월별 비용 임계값을 $50으로 설정하고, 이메일 알림을 활성화했다. 설정 직후의 화면을 보면, 이번 사고로 인해 예산 대비 예상 비용이 이미 1113%를 넘어 버린 상태였다. 마음이 아팠지만, 이런 상태를 사후가 아니라 사전에 잡아내는 것이 이 알림의 목적이다.
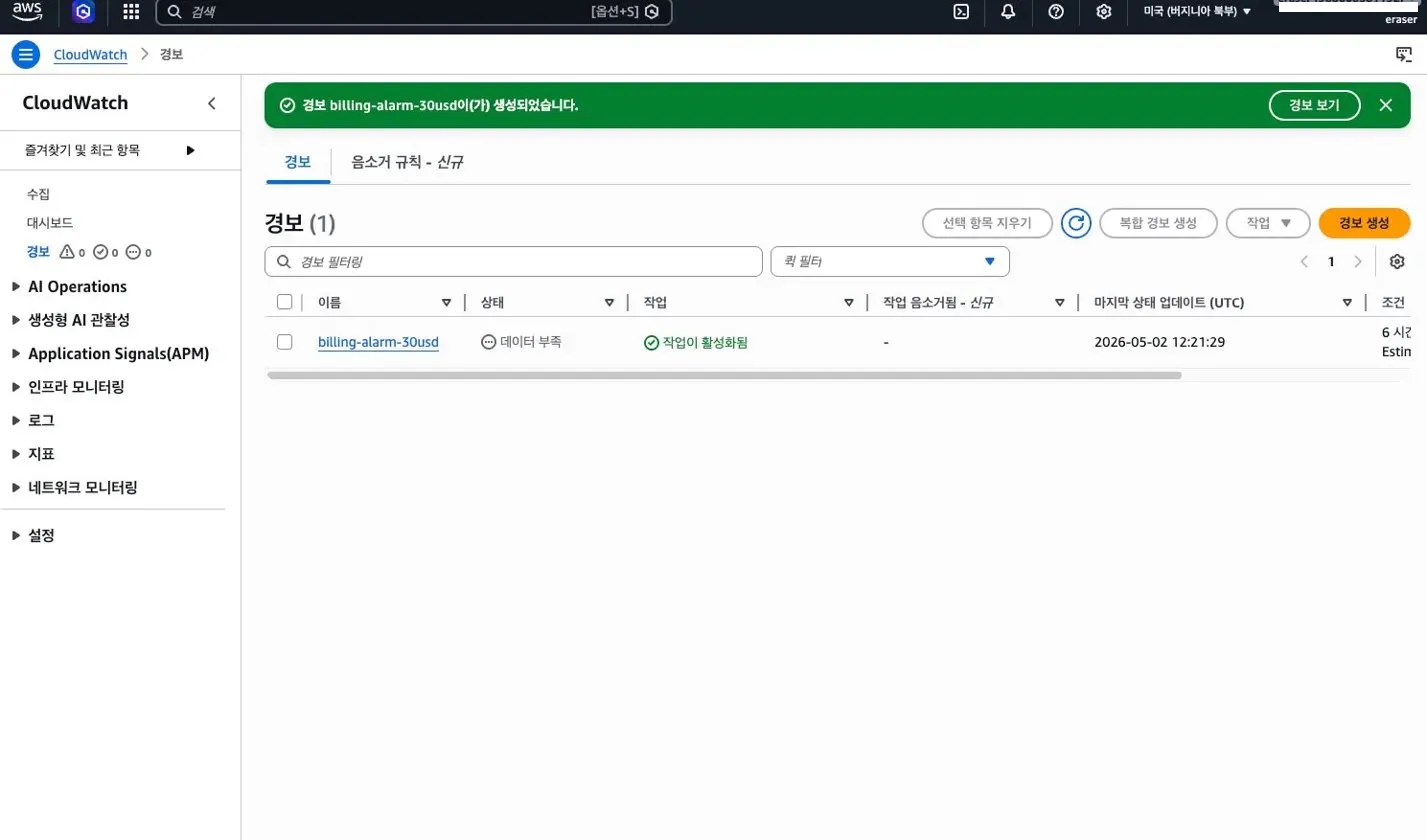
CloudWatch Billing Alarm
CloudWatch에서 billing alarm을 설정했다. 빌링 메트릭(EstimatedCharges)은 us-east-1(버지니아 북부) 리전에서만 사용할 수 있다는 점에 주의해야 한다. $30 임계값으로 알람을 생성하고, SNS를 통해 이메일 알림을 구독했다.
AWS Budgets와 CloudWatch 알람의 차이를 정리하면 다음과 같다.
| 항목 | AWS Budgets | CloudWatch Billing Alarm |
|---|---|---|
| 평가 주기 | 하루 약 3회 | 6시간마다 |
| 데이터 지연 | 8~24시간 | 상대적으로 낮음 |
| 액션 | 이메일 | SNS(이메일, SMS, Lambda, Slack 등) |
두 개를 같이 설정하면 안전망이 두 겹이 된다.
전 리전 리소스 Sweep 스크립트
CloudFormation DELETE_COMPLETE 이후에도 잔존 리소스가 남아 있었던 경험을 바탕으로, 모든 리전의 비용 발생 가능 리소스를 한 번에 확인하는 sweep 스크립트를 작성했다.
REGIONS=($(aws ec2 describe-regions --query "Regions[].RegionName" --output text))
echo "Checking all ${#REGIONS[@]} regions..."
for r in "${REGIONS[@]}"; do
ec2=$(aws ec2 describe-instances --region $r --filters "Name=instance-state-name,Values=running" --query "length(Reservations[].Instances[])" --output text)
nat=$(aws ec2 describe-nat-gateways --region $r --filter "Name=state,Values=available" --query "length(NatGateways[])" --output text)
alb=$(aws elbv2 describe-load-balancers --region $r --query "length(LoadBalancers[])" --output text 2>/dev/null)
clb=$(aws elb describe-load-balancers --region $r --query "length(LoadBalancerDescriptions[])" --output text 2>/dev/null)
eks=$(aws eks list-clusters --region $r --query "length(clusters[])" --output text)
vol=$(aws ec2 describe-volumes --region $r --filters "Name=status,Values=available" --query "length(Volumes[])" --output text)
eip=$(aws ec2 describe-addresses --region $r --query "length(Addresses[?AssociationId==null])" --output text)
if [ "$ec2$nat$alb$clb$eks$vol$eip" != "0000000" ]; then
printf "%-20s EC2:%s NAT:%s ALB/NLB:%s CLB:%s EKS:%s Vol:%s EIP:%s\n" \
"$r" "$ec2" "$nat" "$alb" "$clb" "$eks" "$vol" "$eip"
fi
done
echo ""
echo "=== Failed CloudFormation stacks (ap-northeast-2) ==="
aws cloudformation list-stacks --region ap-northeast-2 \
--stack-status-filter CREATE_FAILED DELETE_FAILED ROLLBACK_FAILED UPDATE_FAILED UPDATE_ROLLBACK_FAILED \
--query "StackSummaries[].[StackName,StackStatus]" --output table
echo ""
echo "Done. (No region listed above = all clean)"
출력에 아무 리전도 나오지 않으면 모든 리전이 깨끗한 것이다. 실습 후에는 반드시 이 스크립트를 돌려서 확인하기로 했다.
Claude Code AWS 비용 감사 Skill
이번 사건을 계기로, IaC로 리소스를 띄우기 전에 예상 비용을 사전에 확인하고, 현재 계정의 활성 리소스 비용을 감사하는 Claude Code skill을 만들었다. aws-cost-estimation 리포지토리에 공개되어 있다. 엄밀한 비용 산출 도구라기보다는, 리소스를 띄우거나 정리할 때 스스로 한 번 돌려보고 자각하기 위한 개인 용도의 간이 도구다.
AWS 비용 감사 결과
계정: XXXXXXXXXXXX (ap-northeast-2 / 서울)
┌─────────────┬────────────┐
│ 항목 │ 값 │
├─────────────┼────────────┤
│ 활성 리소스 0개 │
├─────────────┼────────────┤
│ 일일 추정 │ $0.00 / ₩0 │
├─────────────┼────────────┤
│ 누적 추정 │ $0.00 / ₩0 │
└─────────────┴────────────┘
서울 리전에 떠있는 비용 발생 리소스가 없습니다. 정리할 항목 없음.
실습 환경을 프로비저닝하기 전에 “이게 얼마 드는지”를 먼저 확인하는 습관을 들이고자 한다.
교훈
Silent Failure의 무서움
이번 사건의 본질은 Silent Failure다. CloudFormation 스택 삭제가 실패했는데, 그 사실이 어떤 능동적인 채널로도 전달되지 않았다. 콘솔에 들어가서 직접 확인하지 않는 한 알 수 없었다.
Silent Failure는 비단 CloudFormation만의 문제가 아니다. 시스템을 운영하다 보면, “실패했는데 아무도 모르는” 상황은 언제든 일어날 수 있다. 알림이 없으면 문제가 없는 것이 아니라, 문제를 모르고 있는 것일 뿐이다.
이번 사건 이후 “동작이 성공했는지 반드시 확인하라”는 원칙이 몸에 새겨졌다. 삭제 버튼을 눌렀으면 DELETE_COMPLETE까지 확인하고, 배포를 했으면 health check가 통과했는지 확인하고, 자동화를 걸어뒀으면 알림이 제대로 오는지 확인하라.
사용자 입장에서만 그런 게 아니라, 시스템을 만드는 쪽에서도 silent failure는 중요한 설계 이슈다. 얼마 전 NCCL communicator의 lazy init 디버깅을 하면서도 느낀 것인데, 실패가 발생한 시점과 그 실패가 표면화되는 시점이 분리되면 원인 추적이 극도로 어려워진다. CloudFormation이 삭제 실패를 능동적으로 알려주지 않은 것이나, lazy init 환경에서 NCCL 호환성 에러가 학습 중에야 터지는 것이나, 근본적으로는 같은 구조의 문제다. fail-fast 원칙의 부재가 사용자에게 전가하는 비용은 생각보다 크다.
DELETE_COMPLETE는 끝이 아니다
CloudFormation DELETE_COMPLETE가 떠도 모든 리소스가 삭제된 것이 아닐 수 있다. 이번 사례에서 실제로 DELETE_COMPLETE 이후에도 남아 있었던 리소스를 정리하면 다음과 같다.
| 잔존 리소스 | 생성 주체 | CloudFormation이 모르는 이유 |
|---|---|---|
EKS 클러스터 (eks-saas-gitops) |
워크숍 스크립트 | CloudFormation 외부에서 별도 생성 |
Gitea EC2 (eks-saas-gitops-gitea) |
워크숍 스크립트 | CloudFormation 외부에서 별도 생성 |
| Karpenter 노드 (c5a.xlarge) | Karpenter 컨트롤러 | EKS 내부에서 자체적으로 프로비저닝 |
| 미부착 EBS 볼륨 2개 | 위 인스턴스들 | 인스턴스 삭제 시 자동 삭제되지 않은 볼륨 |
| 미연결 Elastic IP | NAT Gateway | NAT Gateway 삭제 후 해제되지 않은 EIP |
EKS 워크숍처럼 복잡한 실습 환경은, CloudFormation 스택 하나로 모든 것을 관리하지 않는 경우가 많다. 스택 삭제 후에도 반드시 전 리전 sweep을 돌려야 한다.
실습/워크숍 종료 후 체크리스트
- CloudFormation 스택
DELETE_COMPLETE확인- EKS 클러스터 모든 리전
list-clusters확인- EC2 running 인스턴스 모든 리전 확인
- NAT Gateway
available상태 확인- Load Balancer (ALB/NLB/Classic) 확인
- 미부착 EBS Volume 확인
- 미연결 Elastic IP 확인
- Cost Explorer에서 24시간 후 비용 0 수렴 확인
“비용이 중요하다”를 피부로 체감했다
비용이 중요하다는 것은 누구나 안다. 그런데 내 피부로 체감하는 것은 전혀 다른 차원의 경험이다.
카드 결제 알림을 받았을 때의 그 충격은 잊히지 않는다. “삭제했는데 왜?”라는 당혹감, “하루에 100달러씩 새고 있었다고?”라는 경악. 비용 관리가 중요하다, 중요하다 하면서도, 실제로 내 지갑에서 돈이 빠져나가기 전까지는 그 중요성이 피부에 와닿지 않았던 것이다.
실습 환경을 띄우기 전에 비용이 얼마나 발생할 수 있는지 확인하는 습관, 삭제 후 결과를 반드시 확인하는 습관, 그리고 Budget과 알람을 설정하는 습관. 이 세 가지가 이번 사건에서 얻은 가장 실질적인 변화다.
회사에서도
개인 계정에서 겪은 일이지만, 회사 업무에도 시사점이 있다. 개발/테스트용으로 띄운 리소스를 정리하지 않아 비용이 새는 것은 조직에서도 흔히 발생하는 문제다. 이번 경험을 계기로, 회사에서도 리소스 정리에 더 힘써야겠다는 생각을 했다.
특히 EKS 워크숍처럼 복잡한 실습 환경을 프로비저닝하는 경우, cleanup 절차를 문서화하고 검증하는 것이 중요하다. “CloudFormation 스택 삭제 = 모든 리소스 삭제”가 아닐 수 있다는 것은, 개인이든 조직이든 반드시 인지하고 있어야 할 사실이다.
여담: 정말로 비용이 0이 되었는가
모든 정리를 마친 뒤, 5/5에 Cost Explorer를 다시 확인했다.
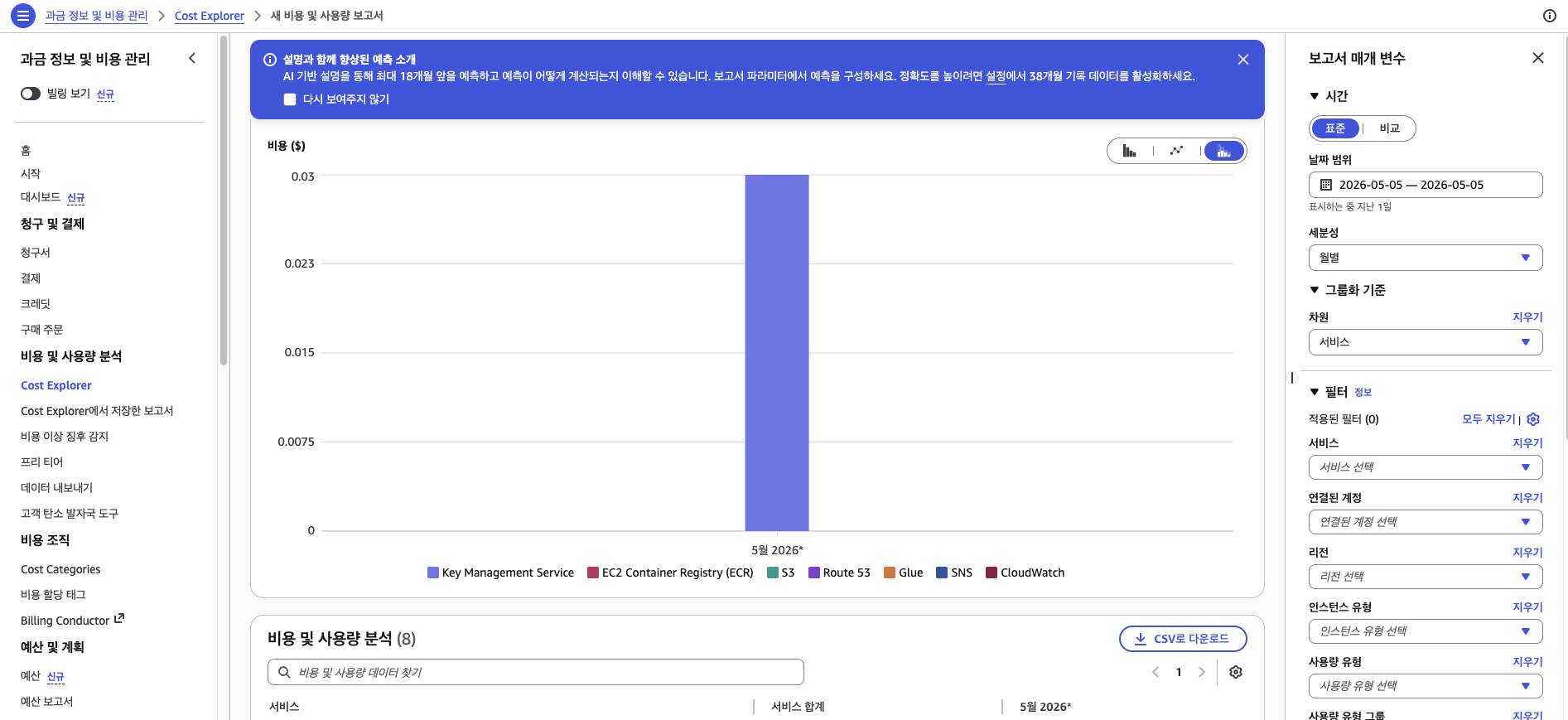
비용이 완전히 0은 아니었다. Key Management Service, ECR, S3, Route 53, CloudWatch 등에서 합계 $0.03 정도가 찍혀 있었다. 이 중 가장 눈에 띄는 Key Management Service(KMS)는, EKS 클러스터가 Kubernetes Secrets의 envelope encryption을 위해 자동으로 생성하는 KMS 키 때문이다. 클러스터를 삭제해도 KMS 키는 별도로 삭제 예약(ScheduleKeyDeletion)을 하지 않으면 남아 있는다. 나머지 서비스들도 워크숍이 남긴 미세한 잔여 비용이다. 하루 $40~50이 새던 것에 비하면 사실상 0에 수렴한 셈이니, 이 정도면 정리가 끝났다고 볼 수 있었다.
돌이켜 보면, 이 사건을 겪으면서 가장 의외였던 것은 AWS Support의 응대 품질이다. 앞서도 언급했지만 다시 한 번 강조하고 싶다. 거대 클라우드 업체라 형식적인 대응을 예상했는데, 실제로는 상황을 꼼꼼히 확인하고 합리적으로 처리해 주었다. 비용 문제로 고민하고 있다면, 주저하지 말고 지원 사례를 열어보길 바란다.
참고 링크
- AWS 공동 책임 모델
- Delete AWS CloudFormation stacks that are stuck in DELETE_FAILED status
- aws-cost-estimation (Claude Code skill)

댓글남기기