
[EKS] EKS 업그레이드: 업그레이드 전략
서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 7주차 학습 내용을 기반으로 합니다.
TL;DR
- EKS 클러스터 업그레이드 전략은 크게 In-Place와 Blue-Green 두 가지로 나뉜다
- In-Place: 기존 클러스터에서 순차적으로 업그레이드. API 엔드포인트 유지, 인프라 오버헤드 낮음. 단, 한 번에 1 마이너 버전만 올릴 수 있고 롤백이 어렵다
- Blue-Green: 새 클러스터를 만들고 워크로드를 마이그레이션. 안전한 롤백, 여러 버전 건너뛰기 가능. 단, 이중 인프라 비용과 마이그레이션 복잡도가 높다
- Incremental In-Place: Version Skew를 활용해 Control Plane만 먼저 여러 단계 올리고, Data Plane은 최대 스큐에 도달했을 때 업그레이드하는 절충안
- 다운타임 허용 범위, 버전 간격, 리소스 제약, 팀 역량에 따라 전략을 선택하면 된다
왜 업그레이드 전략이 필요한가
체계적인 EKS 업그레이드 전략 없이 진행하면 다음과 같은 문제를 겪을 수 있다.
- 예상치 못한 다운타임: 계획 없이 업그레이드하면 서비스 가용성에 영향을 줄 수 있다
- 호환성 문제: 애플리케이션, 애드온, 도구의 호환성 검증 없이 진행하면 장애가 발생한다
- 롤백 어려움: 롤백 계획 없이 업그레이드를 시작하면, 문제 발생 시 복구가 복잡해진다
- 보안 취약점: 업그레이드를 미루면 알려진 보안 취약점에 노출된다
- 기능 누락: 새 Kubernetes 버전의 성능 개선과 새 기능을 활용하지 못한다
이 글에서는 In-Place와 Blue-Green, 두 가지 주요 전략을 비교하고 선택 기준을 정리한다.
In-Place 업그레이드 전략
In-Place 업그레이드는 기존 EKS 클러스터를 그대로 유지하면서, 새로운 Kubernetes 버전으로 업그레이드하는 방식이다. Control Plane과 Data Plane 컴포넌트를 같은 클러스터 내에서 순차적으로 업데이트한다.
업그레이드 절차
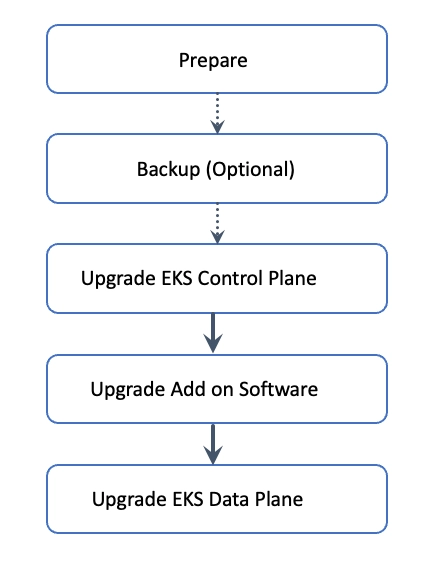
- 업그레이드 사전 준비 (Deprecated API 확인, 호환성 검증 등)
- 클러스터 백업 (선택사항이지만 권장)
- EKS Control Plane을 대상 Kubernetes 버전으로 업그레이드
- 애드온 및 커스텀 컨트롤러를 새 버전에 맞게 업데이트
- Data Plane(워커 노드)을 업그레이드하고, 애플리케이션 정상 동작을 검증
장점
- 기존 클러스터 리소스(VPC, 서브넷, 보안 그룹 등)를 그대로 유지한다
- 클러스터 API 엔드포인트가 변경되지 않으므로, 외부 연동 도구(CI/CD, 모니터링 등)를 수정할 필요가 없다
- 여러 클러스터를 동시에 운영할 필요가 없어 인프라 오버헤드가 낮다
- 상태 저장(Stateful) 워크로드의 데이터 마이그레이션이 불필요하다
단점
- 다운타임 최소화를 위한 세밀한 계획과 조율이 필요하다
- 한 번에 1 마이너 버전만 올릴 수 있다. 여러 버전 뒤처져 있으면 순차 업그레이드를 여러 번 반복해야 한다
- Control Plane이 한 번 업그레이드되면 롤백이 불가능하다
- 모든 컴포넌트와 의존성의 호환성을 철저히 검증해야 한다
Blue-Green 업그레이드 전략
Blue-Green 업그레이드는 대상 Kubernetes 버전으로 새 EKS 클러스터(Green)를 생성하고, 애플리케이션과 애드온을 배포한 뒤, 기존 클러스터(Blue)에서 트래픽을 점진적으로 전환하는 방식이다. 마이그레이션이 완료되면 기존 클러스터를 폐기한다.
업그레이드 절차
- 원하는 Kubernetes 버전으로 새 EKS 클러스터(Green)를 생성
- 새 클러스터에 애플리케이션, 애드온, 설정을 배포
- 새 클러스터가 정상 동작하는지 철저히 검증
- DNS 업데이트, 로드 밸런서 설정, 서비스 메시 등을 이용해 트래픽을 점진적으로 전환
- 새 클러스터가 트래픽을 정상 처리하는지 모니터링
- 모든 트래픽 전환이 완료되면 기존 클러스터를 폐기
장점
- 새 클러스터를 충분히 검증한 후 트래픽을 전환하므로, 안전하고 통제된 업그레이드가 가능하다
- 여러 Kubernetes 버전을 한 번에 건너뛸 수 있다 (예: 1.28 → 1.32)
- 문제 발생 시 트래픽을 기존 클러스터로 다시 전환하면 되므로, 롤백이 간단하다
- 업그레이드 과정에서 기존 클러스터가 계속 트래픽을 처리하므로 다운타임이 최소화된다
단점
- 두 클러스터를 동시에 운영해야 하므로 추가 인프라 비용이 발생한다
- 클러스터 간 트래픽 전환 관리가 복잡하다
- API 엔드포인트와 OIDC가 변경되므로, CI/CD 파이프라인, 모니터링 시스템, 접근 제어 등을 모두 업데이트해야 한다
- 상태 저장 워크로드의 데이터 마이그레이션과 동기화가 필요하다
상태 저장 워크로드 고려사항
Blue-Green 업그레이드에서 상태 저장 워크로드는 특별한 주의가 필요하다.
- Velero 같은 도구를 이용해 Persistent Volume 데이터를 마이그레이션한다
- 클러스터 간 데이터 동기화를 유지하여, 롤백 시에도 데이터 일관성을 보장해야 한다
- 새 클러스터의 StorageClass가 기존 클러스터와 호환되는지 확인한다
- 애플리케이션 소유자와 협의하여, 데이터 마이그레이션 관련 특수 요구사항을 파악한다
In-Place vs Blue-Green 비교
한눈에 비교
| 항목 | In-Place | Blue-Green |
|---|---|---|
| 버전 건너뛰기 | 불가 (1 마이너씩) | 가능 (여러 버전 한 번에) |
| API 엔드포인트 | 유지 | 변경됨 |
| 롤백 | CP 불가, DP 제한적 | 트래픽 전환으로 간단 |
| 인프라 비용 | 낮음 | 이중 클러스터 운영 비용 |
| Stateful 워크로드 | 마이그레이션 불필요 | 데이터 마이그레이션 필요 |
| 복잡도 | 순차 업그레이드 관리 | 트래픽 전환, 연동 업데이트 |
전략 선택 시 고려사항
- 다운타임 허용 범위: 서비스의 다운타임 허용 수준에 따라 선택
- 업그레이드 복잡도: 애플리케이션 아키텍처, 의존성, 상태 저장 컴포넌트의 복잡도 평가
- Kubernetes 버전 간격: 현재 버전과 목표 버전 간 간격이 클수록 Blue-Green이 유리
- 리소스 제약: 이중 클러스터 운영을 위한 인프라 리소스와 예산 확인
- 팀 역량: 멀티 클러스터 관리 및 트래픽 전환 경험 평가
Incremental In-Place 전략
여러 버전 뒤처져 있지만, Blue-Green의 비용이나 복잡도를 감당하기 어려운 경우, Kubernetes의 Version Skew 지원을 활용한 Incremental In-Place 전략을 고려할 수 있다.
업그레이드 절차
- EKS Control Plane을 다음 마이너 버전으로 업그레이드한다. Kubernetes는 Control Plane이 워커 노드보다 최대 2 마이너 버전 앞설 수 있도록 허용한다
- 최대 스큐에 도달할 때까지 워커 노드는 기존 버전을 유지한다
- 예: CP 1.30 / DP 1.30 시작 → CP를 1.31, 1.32로 올려도 DP는 1.30 유지 가능
- Control Plane이 최대 스큐를 초과하는 버전에 도달하면(예: CP 1.33, DP 1.30), 워커 노드를 스큐 범위 내 버전(예: 1.31 또는 1.32)으로 업그레이드
- 1~3을 반복하여 목표 버전에 도달
적합한 경우
- 여러 버전 뒤처져 있어 점진적으로 따라잡아야 할 때
- 복잡한 상태 저장 워크로드가 있어 노드 업그레이드를 자주 하기 어려울 때
- Control Plane의 새 기능과 버그 수정을 먼저 적용하면서, 워커 노드의 변경은 최소화하고 싶을 때
유의사항
- 일부 새 Kubernetes 기능이나 성능 개선은 워커 노드도 업그레이드해야 완전히 활용할 수 있다
- 여러 버전을 건너뛴 후 워커 노드를 업그레이드할 때는, 철저한 호환성 검증이 필수다
- 가능한 한 Control Plane과 워커 노드의 버전 차이를 최소화하는 것이 권장된다
정리
EKS 클러스터 업그레이드 전략을 선택할 때의 핵심은 다음과 같다.
- 마이너 버전 업그레이드 + 낮은 다운타임 허용: In-Place
- 큰 버전 차이 + 높은 Stateful 복잡도 + 안전한 롤백 필요: Blue-Green
- 큰 버전 차이 + 비용 제약: Incremental In-Place
어떤 전략을 선택하든, 다음 사항은 공통으로 중요하다.
- 사전에 철저한 호환성 검증과 테스트를 수행한다
- 모니터링/로깅 체계를 갖추고, 명확한 롤백 계획을 수립한다
- IaC 도구(Terraform 등)와 GitOps를 활용해 자동화하고 일관성을 유지한다
- 이전 업그레이드의 교훈을 반영해 전략을 지속적으로 개선한다
다음 글에서는 실제 업그레이드를 진행하기 전에 확인해야 할 준비사항을 살펴본다.
참고 링크
- Amazon EKS Cluster Upgrades Best Practices
- Kubernetes Version Skew Policy
- EKS Upgrade Workshop - Choosing an Upgrade Strategy

댓글남기기