
[EKS] EKS 업그레이드: Blue-Green Managed Node Group 마이그레이션
서종호(가시다)님의 AWS EKS Workshop Study(AEWS) 7주차 학습 내용을 기반으로 합니다.
TL;DR
- 이전 글에서 In-Place로
initial노드 그룹을 업그레이드했지만,blue-mng은cluster_version = "1.30"으로 고정되어 아직 1.30이다 - Blue-Green 전략: 새 노드 그룹(
green-mng, 1.31)을 생성한 뒤, 기존 노드 그룹(blue-mng, 1.30)을 삭제하여 파드를 마이그레이션 blue-mng에는 Orders 앱(MySQL 포함)이 taint/toleration으로 고정 배치되어 있는 Stateful 워크로드 시나리오다- PDB(
minAvailable: 1)가 설정된 상태에서 레플리카 1개로는 drain이 블로킹되므로, 마이그레이션 전에 레플리카를 2로 증가시켜야 한다 blue-mng삭제 시 EKS가 자동으로 cordon → drain → terminate를 수행하고, Orders 파드가green-mng노드로 재스케줄링된다
개요
이전 글에서 In-Place 롤링 업데이트로 initial 노드 그룹을 업그레이드했다. 하지만 blue-mng은 cluster_version = "1.30"으로 직접 고정되어 있어 mng_cluster_version 변경의 영향을 받지 않았다.
이 노드 그룹은 Stateful 워크로드(Orders + MySQL)가 taint/toleration으로 고정 배치되어 있고, 단일 가용 영역에 프로비저닝되어 있다. 이런 경우, 기존 노드 그룹을 그대로 업데이트하는 대신 새 노드 그룹을 생성하고 워크로드를 마이그레이션하는 Blue-Green 전략이 적합하다.
흐름은 다음과 같다.
Green MNG 생성 (1.31, 동일 label/taint)
↓
두 노드 그룹 공존 확인
↓
PDB 대응 (레플리카 증가)
↓
Blue MNG 삭제 (auto cordon → drain → terminate)
↓
파드가 Green MNG로 재스케줄링
↓
마이그레이션 완료
Blue MNG 현재 상태 확인
노드 확인
~$ kubectl get nodes -l type=OrdersMNG
NAME STATUS ROLES AGE VERSION
ip-10-0-6-74.us-west-2.compute.internal Ready <none> 2d6h v1.30.14-eks-40737a8
blue-mng 노드는 아직 v1.30이다.
Taint 확인
~$ kubectl get nodes -l type=OrdersMNG \
-o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
# 실행 결과
ip-10-0-6-74.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
dedicated=OrdersApp:NoSchedule taint이 적용되어 있다. toleration이 있는 Orders 파드만 이 노드에 스케줄링된다.
노드에서 실행 중인 파드
~$ kubectl describe node -l type=OrdersMNG
Non-terminated Pods 섹션을 보면, kube-system 파드와 함께 orders 앱 파드가 이 노드에서 실행 중인 것을 확인할 수 있다.
| 네임스페이스 | 파드 | 설명 |
|---|---|---|
| orders | orders-788b566b87-xxxxx | Orders API 서버 |
| orders | orders-mysql-5fd8b99db5-xxxxx | Orders MySQL |
| kube-system | aws-node, ebs-csi-node, efs-csi-node, kube-proxy | 시스템 데몬셋 |
실습: Blue-Green 마이그레이션
1단계: Green MNG 생성
base.tf에 green-mng을 추가한다. blue-mng과 동일한 label, taint, subnet 설정이지만, cluster_version을 명시하지 않아 eks_managed_node_group_defaults의 값(1.31)을 따른다.
green-mng = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
subnet_ids = [module.vpc.private_subnets[0]]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}

blue-mng과의 차이점은 cluster_version = "1.30" 줄이 없다는 것뿐이다. 나머지 설정(label, taint, subnet, 인스턴스 타입)은 동일하다.
~$ cd ~/environment/terraform
~$ terraform plan && terraform apply -auto-approve
2단계: 두 노드 그룹 공존 확인
Green MNG 생성 후, EKS 콘솔에서 노드 그룹 상태를 확인해 보자.
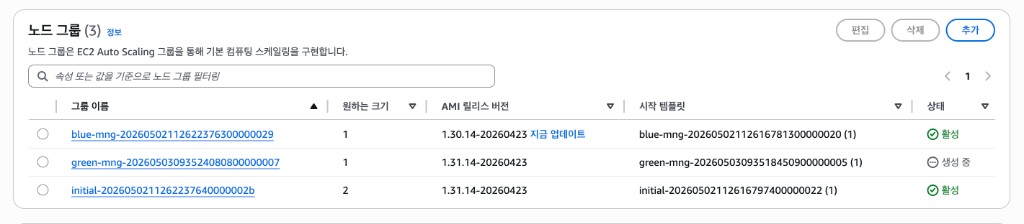
blue-mng이 여전히 1.30인 것은 의도된 동작이다. blue-mng은 Terraform에서 cluster_version = "1.30"으로 직접 고정되어 있으므로, Control Plane이나 다른 노드 그룹의 버전 변경과 무관하게 1.30을 유지한다. 이것이 바로 Blue-Green 마이그레이션이 필요한 이유다.
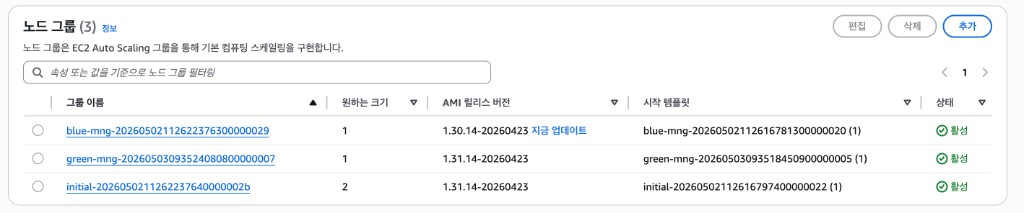
type=OrdersMNG 레이블을 가진 노드가 2개로 늘어난 것을 확인한다.
~$ kubectl get nodes -l type=OrdersMNG -o wide
| 노드 | 버전 | 노드 그룹 |
|---|---|---|
| ip-10-0-6-74 | v1.30.14 | blue-mng |
| ip-10-0-7-225 | v1.31.14 | green-mng |
Taint도 동일하게 적용되어 있는지 확인한다.
~$ kubectl get nodes -l type=OrdersMNG \
-o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
# 실행 결과
ip-10-0-6-74.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
ip-10-0-7-225.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"OrdersApp"}
두 노드 모두 동일한 label과 taint을 가지고 있으므로, Orders 파드가 어느 쪽으로든 스케줄링될 수 있는 상태다.
3단계: PDB 대응 — 레플리카 증가
업그레이드 준비 포스트에서 설정한 PDB(minAvailable: 1)가 있는 상태에서, Orders Deployment의 레플리카가 1이면 drain 시 파드 축출이 블로킹된다. 새 파드가 다른 노드에 뜨기 전까지 기존 파드를 제거할 수 없기 때문이다.
이를 해결하기 위해 레플리카를 2로 증가시킨다.
~$ cd ~/environment/eks-gitops-repo/
~$ sed -i 's/replicas: 1/replicas: 2/' apps/orders/deployment.yaml
~$ git add apps/orders/deployment.yaml
~$ git commit -m "Increase orders replicas 2"
~$ git push
ArgoCD로 동기화하여 클러스터에 반영한다.
~$ argocd app sync orders
이제 Orders 파드가 2개로 늘어나면서, 하나가 green-mng 노드에 스케줄링된다. 이 상태에서 blue-mng 노드를 drain해도 PDB 조건(minAvailable: 1)을 만족하므로 축출이 진행된다.
4단계: Blue MNG 삭제
base.tf에서 blue-mng 블록을 제거하고 Terraform을 적용한다.

~$ cd ~/environment/terraform/
~$ terraform plan && terraform apply -auto-approve
이 작업은 약 10~15분 소요된다.
EKS가 자동으로 blue-mng 노드에 대해 다음을 수행한다.
- Cordon: 새 파드가 스케줄링되지 않도록 차단
- Drain: 실행 중인 파드를 축출 (PDB를 존중)
- Terminate: Auto Scaling Group에서 노드 종료
K8s 이벤트로 과정을 모니터링할 수 있다.
~$ kubectl get events --sort-by='.metadata.creationTimestamp'
5단계: 마이그레이션 결과 확인
Orders 파드가 green-mng 노드로 이동했는지 확인한다.
~$ kubectl get pods -n orders -o wide
Green MNG 노드에서 Orders 파드가 실행 중인 것을 확인할 수 있다.
~$ kubectl get node -l type=OrdersMNG
NAME STATUS ROLES AGE VERSION
ip-10-0-2-147.us-west-2.compute.internal Ready <none> 27m v1.31.14-eks-ecaa3a6
이제 type=OrdersMNG 레이블을 가진 노드는 green-mng의 v1.31 노드 하나뿐이다.

노드 그룹 목록에서도 blue-mng이 제거된 것을 확인할 수 있다.
~$ aws eks list-nodegroups --cluster-name eksworkshop-eksctl
{
"nodegroups": [
"green-mng-xxxxxxxxxxxxxxxxxxxx",
"initial-xxxxxxxxxxxxxxxxxxxx"
]
}
핵심 포인트
PDB와 레플리카의 관계
이 실습에서 가장 중요한 포인트는 PDB와 레플리카 수의 관계다.
| 레플리카 | PDB(minAvailable: 1) | Drain 가능 여부 |
|---|---|---|
| 1 | 축출하면 가용 파드 0 → PDB 위반 | 블로킹 |
| 2 | 하나를 축출해도 가용 파드 1 → PDB 충족 | 진행 |
Stateful 워크로드의 Blue-Green 마이그레이션에서는, 새 노드 그룹이 준비된 후 레플리카를 충분히 늘려서 PDB 조건을 만족시킨 다음 기존 노드 그룹을 삭제해야 한다.
왜 Blue-Green인가
blue-mng은 다음과 같은 특성을 가져, In-Place보다 Blue-Green이 적합했다.
cluster_version = "1.30"으로 버전이 직접 고정되어 있어 기본값 변경의 영향을 받지 않음- Stateful 워크로드(MySQL)가 배치되어 있어, 롤링 업데이트보다 새 노드를 먼저 준비하고 마이그레이션하는 것이 안전
- 단일 AZ에 프로비저닝되어 있어, 동일 AZ에 Green 노드를 생성하면 PV 접근에도 문제가 없음
정리
Blue-Green Managed Node Group 마이그레이션을 완료했다. 현재까지의 노드 업그레이드 상황을 정리하면 다음과 같다.
| 노드 유형 | 노드 그룹 | 전략 | 상태 |
|---|---|---|---|
| Managed Node Group | initial |
In-Place | 1.31 완료 |
| Managed Node Group | blue-mng → green-mng |
Blue-Green | 1.31 완료 (이 글) |
| Karpenter | default NodePool | - | 다음 글 |
| Self-managed / Fargate | default-selfmng, fp-profile | - | 다음 글 |

댓글남기기