
[GenAI] GenAI on K8s: 10.5 - GPU 스케일링·최적화와 NVIDIA NIM
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 10장의 학습 내용을 바탕으로 합니다
TL;DR
- DCGM 메트릭은 prometheus-adapter를 거쳐야 HPA가 읽을 수 있다: DCGM-Exporter → Prometheus → adapter → HPA
- GPU_UTIL 단일 지표만으로 스케일링하면 phantom utilization(허수)에 속거나, 실제로는 느린데 바쁜 상태를 놓친다 — throughput·latency custom metric 병행이 필수다
- NVIDIA NIM은 모델 + 런타임 + 최적화 엔진 + 표준 API를 한 컨테이너에 포장한 추론 마이크로서비스다
이전 글에서 MPS와 time-slicing을 통한 GPU 공유 기법을 다뤘다. 이번 글에서는 DCGM 메트릭을 활용한 GPU 워크로드 오토스케일링과 NVIDIA NIM을 정리하며 Ch10 이론 파트를 마무리한다. time-slicing 실습에서 DCGM 지표가 부하에 어떻게 반응하는지는 10.7 Step 7.5에서 실측한다.
GPU 메트릭 기반 스케일링
DCGM이 수집하는 GPU 메트릭(health·utilization·performance)을 기반으로 K8s 워크로드를 동적으로 스케일링할 수 있다.
파이프라인은 다음과 같다. 앞단은 10.2 — GPU Utilization과 DCGM에서 다룬 대로다.
DCGM (telemetry 수집) → dcgm-exporter (Prometheus 포맷 노출)
→ Prometheus (scrape) → prometheus-adapter (K8s metrics API 변환)
→ HPA / VPA (워크로드 스케일링)
telemetry = 시스템·하드웨어가 자동으로 수집·전송하는 측정 데이터. 10.2에서도 말했듯이, dcgm-exporter ↔ Prometheus 관계는 expose → scrape(pull)다. prometheus-adapter는 10.2 범위 밖이고, 이번 글에서 HPA 연동을 위해 새로 등장한다.
GPU 사용률 기반 HPA
GPU utilization이 임계치를 넘으면 replica를 늘리고(scale-out), 낮게 유지되면 줄인다(scale-in). DCGM 커스텀 메트릭 기반 HPA는 autoscaling/v2 스키마로 다음처럼 쓴다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: genai-training-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: genai-training
minReplicas: 1
maxReplicas: 10 # scale-out 상한
metrics:
- type: Pods # Pod별 GPU 메트릭의 평균
pods:
metric:
name: DCGM_FI_DEV_GPU_UTIL
target:
type: AverageValue # request 대비 %가 아니라 게이지 평균값
averageValue: "80" # GPU util 평균 80 초과 시 scale-out
behavior:
scaleDown:
stabilizationWindowSeconds: 600 # 낮은 사용률이 10분 지속돼야 scale-in
autoscaling/v2스키마 주의: 구v2beta1에서 쓰던metricName/targetAverageValue는 v2(GA)에서 제거됐다. v2는metric.name+target.{type, averageValue}구조를 쓴다. 또 DCGM GPU util은 특정 오브젝트 하나에 붙는 값이 아니라 Pod별 메트릭이므로type: Object(이건describedObject필수)보다type: Pods가 맞다.averageUtilization은 Pod의 resource request 대비 %라 커스텀 게이지엔 부적합해서AverageValue+averageValue(여기선 게이지 값 80)를 쓴다.
10.2에서도 말했듯이, DCGM ≠ dcgm-exporter다. 전자(DCGM)는 NVML로 GPU 지표를 측정하고, 후자(dcgm-exporter)는 그 결과를 Prometheus 텍스트로 노출할 뿐이다 — 10.2는 여기까지(관측·Grafana)가 범위였다.
HPA까지 가려면 10.2에서 다루지 않은 역할이 하나 더 있다: prometheus-adapter. exporter ≠ prometheus-adapter — 이름만 비슷할 뿐, exporter는 GPU → Prometheus 방향, adapter는 Prometheus → K8s 방향이다.
전체 체인: DCGM → HPA
위 HPA manifest의 metric.name: DCGM_FI_DEV_GPU_UTIL이 실제로 어디서 오는지, hop마다 정리하면 다음과 같다.
| hop | 컴포넌트 | 하는 일 | 출력 |
|---|---|---|---|
| 1 | DCGM | NVML로 GPU 하드웨어에서 utilization·VRAM·온도 등 원시 지표 수집 | DCGM 필드 ID (예: DCGM_FI_DEV_GPU_UTIL) |
| 2 | dcgm-exporter | DCGM에 질의 → Prometheus exposition format으로 렌더링 → :9400/metrics 노출. PodResources API로 Pod/namespace 라벨 부착 |
/metrics 텍스트 (Prometheus scrape 대상) |
| 3 | Prometheus | exporter를 주기적으로 scrape(pull) → TSDB에 시계열 저장. PromQL로 조회 가능 | DCGM_FI_DEV_GPU_UTIL{...} 시계열 |
| 4 | prometheus-adapter | PromQL 규칙(ConfigMap)에 따라 Prometheus를 조회 → K8s custom/external metrics API로 번역·노출 | custom.metrics.k8s.io/v1beta1 등 API 응답 |
| 5 | HPA | metrics API에서 DCGM_FI_DEV_GPU_UTIL 값을 읽어 target(80%)과 비교 → Deployment replica 증감 |
scale-out / scale-in |
1~3hop은 10.2의 관측 파이프라인과 동일하다. Grafana까지는 3hop에서 끝나지만, HPA는 K8s 네이티브 metrics API만 이해한다. Prometheus TSDB나 exporter /metrics URL은 HPA가 접근할 수 없으므로, 4hop adapter가 Prometheus 세계 ↔ K8s 세계 사이의 번역기 역할을 한다. adapter의 PromQL→metricName 매핑은 ConfigMap(rules)으로 정의하며, 여기서 DCGM_FI_DEV_GPU_UTIL이 HPA가 요청할 수 있는 이름으로 등록된다.
DCGM 주요 메트릭
| 메트릭 | 의미 |
|---|---|
| DCGM_FI_DEV_GPU_UTIL | GPU 사용률 (%) |
| DCGM_FI_DEV_FB_USED | framebuffer(VRAM) 사용량 |
| DCGM_FI_DEV_MEM_COPY_UTIL | 메모리 인터페이스(read/write) 가동 시간 비율(%) — 대역폭(GB/s) 대비 %가 아님 |
| DCGM_FI_DEV_POWER_USAGE | 전력 소비 |
| DCGM_FI_DEV_GPU_TEMP | GPU 온도 |
| DCGM_FI_DEV_XID_ERRORS | XID 에러 |
GPU health 기반 리스케줄·드레인
DCGM은 error handling·health monitoring 정책도 지원한다. 메모리 에러·과열 감지 → K8s가 해당 노드를 제거하고, 워크로드를 healthier 노드로 이동시킨다.
GPU 기반 스케일링의 어려움
| 어려움 | 내용 |
|---|---|
| 지표 ↔ 성능 불일치 | utilization이 실제 application 성능과 직접 연관 없을 수 있다 |
| 공유 GPU 왜곡 | time-slicing/MIG 환경은 DCGM 메트릭이 공유 기준 → 보정 필요 |
| 모니터링 오버헤드 | 대규모 클러스터에서 GPU 메트릭 상시 수집은 부담이다 |
| health 미반영 위험 | error rate·온도를 포함해야 faulty 하드웨어를 회피할 수 있다 |
GPU_UTIL을 곧이곧대로 믿으면 안 되는 두 경우.
(1) phantom utilization: GPU에 프로세스도 메모리도 없는데 GPU_UTIL이 100%인 현상이다. 비정상 종료 후 orphaned CUDA context가 원인이다.
시그니처:
- GPU-Util 100%
- Memory 0
- 프로세스 없음
- SM activity 100%인데 memory activity 0%
위험: 스케줄러·오토스케일러가 “이 GPU는 바쁘다”고 오인한다. 교훈: GPU_UTIL 단독 판단 금지.
관련 글: Phantom GPU Utilization 사례 분석
(2) util이 진짜 높은데 application 성능은 낮은 경우: 핵심 성능 지표는 throughput / latency다.
- memory-bound 추론: SM이 HBM 대기에 “바쁨”으로 잡힌다. 실제로는 데이터를 기다리는 중이다
- 작은 batch launch 오버헤드: 커널마다 준비 비용이 든다. 택배 비유로 말하면, 한 건씩 보내면 건당 포장·운송 비용이 커서 총 처리량이 떨어지는 것과 같다
- 공유 GPU(time-slicing) 경합: 종합 util은 높으나 개별 워크로드의 latency는 길어진다
- p99 latency·throughput은 util에 안 잡힌다: GPU가 100% 바빠도 사용자 체감 응답 시간이 느리면 의미가 없다
→ util 단일 지표 스케일링은 두 경우 모두 문제다. custom metric 병행이 필요하다.
운영자 책임 — time-slicing 환경에서 사용률만 보고 scale-out하면 VRAM OOM이 발생할 수 있다.
베스트 프랙티스
- DCGM built-in 정책 활용
- GPU 지표 + application 지표를 결합한 custom Prometheus 메트릭 사용
- NVIDIA GPU Operator 연동으로 GPU 스택 일괄 관리
- scaling threshold를 정기적으로 테스트·튜닝
NVIDIA NIM
NIM(NVIDIA Inference Microservices)은 NVIDIA AI Enterprise의 구성요소로, NVIDIA가 AI 모델을 “바로 배포 가능한 추론 마이크로서비스 컨테이너”로 포장한 것이다. TensorRT-LLM, vLLM, SGLang, Triton 같은 최적화된 inference engine 위에 구축되며, runtime에 GPU를 탐지해 (model × GPU) 조합에 맞는 최적 엔진/프로파일을 자동으로 선택한다.
컨테이너 구성
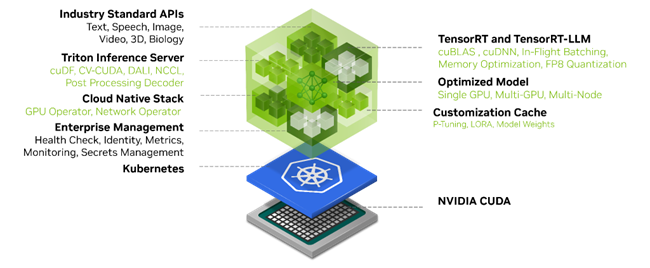
위 그림은 NIM 컨테이너를 아래에서 위로 쌓은 레이어 스택이다. 맨 아래 CUDA runtime/driver 위에 TensorRT-LLM 같은 최적화 엔진과 모델 weights·engine cache가 올라가고, Triton Inference Server가 서빙 계층을 담당한다. 그 위 Enterprise/K8s 연동 레이어를 거쳐 REST/gRPC API로 노출된다. 즉 “모델 파일 + 추론 엔진 + 서빙 런타임 + 표준 API”를 한 이미지에 넣어, Ch10 실습의 transformers.generate 단순 서빙과 달리 프로덕션급 추론 스택을 바로 쓸 수 있게 하는 구조다.
위 스택 그림(Triton 서빙 계층 중심)은 초기 NIM 아키텍처 기준이다. 최신 LLM NIM은 “한 컨테이너에 한 백엔드(vLLM/TensorRT-LLM/SGLang)”로 단순화되는 추세이고, 노출 API도 LLM NIM은 OpenAI 호환 REST가 표준이다. 그림은 개념 이해용으로 보고, 세부 구성은 버전에 따라 달라질 수 있다.
| 계층 | 구성 |
|---|---|
| 노출 (API) | 표준 REST/gRPC API |
| 관리 (Enterprise/K8s) | AI Enterprise 런타임, K8s 연동 |
| 서빙 (Triton) | Triton Inference Server |
| 최적화 (엔진 + 모델) | TensorRT-LLM + 모델 weights + engine cache |
| 기반 (CUDA) | CUDA runtime + driver |
용도
AI 앱 배포를 단순화한다. RAG 기반 챗봇, simulation 파이프라인 등에 활용할 수 있다.
AI Enterprise / 개발 vs 운영. 개발 단계에서는 Developer Program 무료 체험이 가능하다. 운영 환경에서는 AI Enterprise 라이선스가 필요하다. MIG/MPS/time-slicing이 “GPU를 어떻게 나눠 쓰나”의 인프라 레이어라면, NIM은 “모델을 어떻게 서빙하나”의 애플리케이션 레이어다.
공식 링크:
정리
| 영역 | 핵심 포인트 |
|---|---|
| 스케일링 파이프라인 | DCGM-Exporter → Prometheus → adapter → HPA |
| GPU_UTIL 주의 | phantom utilization(허수) + “바쁜데 느린” 상태 → custom metric 병행 |
| 스케일링 어려움 | 지표 불일치, 공유 GPU 왜곡, 모니터링 오버헤드, health 미반영 |
| NVIDIA NIM | 모델 + 엔진 + API 캡슐화 → 추론 마이크로서비스 컨테이너 |
참고 링크
- Kubernetes for Generative AI Solutions — GitHub
- NVIDIA DCGM Documentation
- NVIDIA NIM Microservices
- Prometheus Adapter for Kubernetes Metrics APIs
- Phantom GPU Utilization 사례 분석
- EKS GPU 트러블슈팅 개요
- EC2 Service Quota 증설

댓글남기기