
[GenAI] GenAI on K8s: 11.1 - GenAIOps 개요와 GenAI 파이프라인 5단계
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 11장의 학습 내용을 바탕으로 합니다
10장에서 GPU 자원 할당·활용·공유를 다뤘다. 11장은 그 위에 운영(Ops) 레이어를 올린다 — GenAI 모델의 전체 라이프사이클을 자동화·관리·최적화하는 GenAIOps다.
이번 글에서는 파이프라인 5단계와 모니터링·drift 감지 기초를 정리하고, K8s 위 도구(Kubeflow·MLflow·Argo·Ray)는 11.2부터 순차적으로 다룬다.
TL;DR
- GenAIOps = MLOps의 확장. foundation model·LLM·diffusion model의 거대 규모, 분산 학습, 프롬프트·RAG 관리, 출력 비결정성을 추가로 다룬다
- GenAI 파이프라인은 data management → experimentation → model adaptation → serving → monitoring 5단계가 피드백 루프로 연결된다
- serving은 real-time·batch 두 모드, monitoring은 drift·bias·guardrail을 추적해 재학습을 트리거한다
- 정확도 하락 시 data drift(입력 분포 변화)와 concept drift(입력↔출력 관계 변화)를 구분해야 대응이 달라진다
GenAIOps란
GenAIOps(Generative AI Operations)는 생성형 AI 모델의 라이프사이클 전체 — data → experimentation → adaptation → serving → monitoring — 을 자동화·관리·최적화하기 위한 도구·관행·워크플로우 묶음이다.
기존 MLOps가 분류·회귀 모델의 학습·배포·모니터링을 다뤘다면, GenAIOps는 다음을 추가로 직면한다.
| GenAI 고유 과제 | 운영 영향 |
|---|---|
| 거대 foundation model | 분산 학습·GPU 스케일링 필수 |
| 프롬프트·RAG 관리 | 실험 추적 대상이 코드만이 아님 |
| 출력 비결정성 | 품질 평가·guardrail·human review 필요 |
| 멀티모달·LLM 평가 | accuracy만으로는 부족 — 별도 eval 프레임워크 |
지금은 파이프라인 단계와 drift 분류만 알면 충분하다. Kubeflow·MLflow·Ray 같은 구체 도구는 후속 글에서 각각 다룬다.
GenAI 파이프라인 5단계
GenAI 애플리케이션을 빌드·배포·유지보수하는 end-to-end 여정이다. 다섯 단계가 피드백 루프로 연결된다.
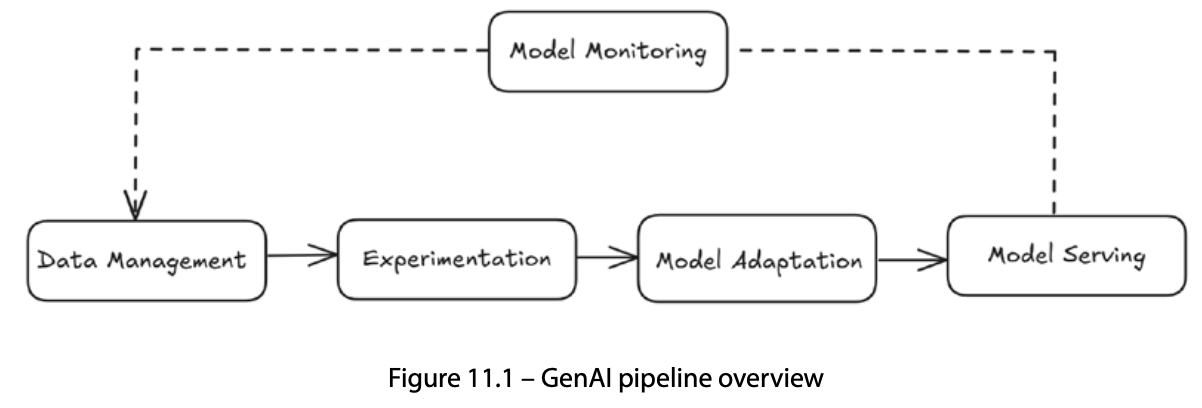
| 단계 | 핵심 활동 | K8s 위 대표 도구 |
|---|---|---|
| Data Management | 데이터 수집·정제·feature engineering | Apache Spark on K8s, Ray Data, Flink |
| Experimentation | 모델 선택·프로토타이핑·EDA | JupyterHub, Kubeflow Notebooks, MLflow |
| Model Adaptation | fine-tuning · distillation · prompt engineering | Kubeflow Training Operator, Ray Train |
| Model Serving | real-time / batch inference | KServe, Ray Serve, Seldon Core |
| Model Monitoring | 성능·drift·bias 추적, 재학습 트리거 | Prometheus/Grafana + custom drift detector |
Data Management
raw data를 수집·정제·구조화하여 고품질 실험을 위한 토대를 만든다.
- 소스: 내부 DB, third-party API, 스트리밍(Kafka 등), data lake, public dataset
- Feature engineering: raw 데이터를 의미 있는 feature로 변환(cleaning, normalization, structuring) → 결과를 offline feature store에 저장해 재사용
- K8s 패턴: 컨테이너화된 워크로드로 분산 전처리
- Spark on K8s — TB 단위 데이터를 worker Pod에 분산
- Data on EKS (DoEKS) — EKS 위 Spark·데이터 분석 운영 blueprint
Experimentation
비즈니스 유스케이스에 맞는 foundation model(FM) / LLM을 선택하고, 어떻게 adapt할지 아키텍처를 결정하는 단계다.
- 프로토타이핑, 가설 테스트, EDA, baseline 모델 생성
- 여러 모델·설정을 반복 비교
- 재현성(reproducibility)이 핵심 — 실험 데이터·노트북·코드·결과를 버전 관리해야 비교·롤백 가능
- 노트북·데이터 저장: S3 등 확장 스토리지. 버킷 versioning·tag로 학습 데이터 set 구분
- 도구: Jupyter Notebook(개별), JupyterHub(공유), Kubeflow Notebooks(K8s 통합) — JupyterHub는 Ch5·10.6에서 이미 배포했다
Model Adaptation
선택한 FM을 실제 유스케이스에 맞게 정렬(align)한다. 일반적인 언어·이미지 이해는 유지하면서 도메인 특화 뉘앙스를 학습한다.
| 접근 | 동작 |
|---|---|
| Transfer learning | 대부분 레이어 freeze, 일부만 도메인 데이터로 재학습 |
| Full fine-tuning | end-to-end 재학습 (자원·시간 비용 큼) |
| Prompt engineering | 모델은 그대로, 입력 프롬프트로만 행동 유도 |
| PEFT (LoRA, QLoRA 등) | 작은 adapter만 학습 — Ch4 QLoRA 참조 |
분산 학습·HPO·스케일 가능한 fine-tuning은 K8s 위 Kubeflow Training Operator, Ray Train, Argo Workflows step으로 오케스트레이션한다 — 11.2, 11.5에서 상세.
Model Serving
학습 완료된 artifact를 inference로 노출한다.
| 모드 | 특성 | K8s 패턴 |
|---|---|---|
| Real-time inference | low-latency, REST/gRPC endpoint | LB + HPA + canary/A/B. KServe, Ray Serve, Seldon Core |
| Batch inference | 주기적 dataset → 대규모 추론 → S3 sink | CronJob / Argo Workflows step |
Real-time inference와 batch inference는 K8s 패턴이 다르지만, 운영 관점에서는 공통으로 latency, throughput, error rate를 모니터링하고 로깅해야 한다. GPU 서빙 자원은 10장에서 다룬 extended resource·공유 기법과 맞물린다.
Model Monitoring
피드백 루프를 닫는 단계다. 성능 저하·데이터 분포 변화를 감지해 재학습·fine-tune을 트리거한다.
- KPI를 real-time 추적, alert/dashboard로 가시화
- 성능 저하·분포 변화 감지 → 재학습 / fine-tune → 모델이 새 패턴에 adapt
- raw metric을 넘어 bias detection, guardrail 준수, fairness/compliance 점검
- MLOps 인프라와 통합 → automated rollback, canary deployment
- 주기적 ground truth review와 dataset 갱신
위 항목들은 모델 품질·거버넌스 층위에 해당한다. “raw metric을 넘어”는 accuracy·latency 같은 기본 KPI를 넘어 bias·guardrail·fairness를 본다는 뜻이지, GPU 하드웨어 메트릭을 가리키지는 않는다. GenAI 서빙 모니터링은 아래처럼 층위가 나뉜다.
| 층위 | 무엇을 보는가 | 이 글·시리즈에서의 위치 |
|---|---|---|
| 서빙 KPI | latency, throughput, error rate | Model Serving(위) |
| 모델 품질·거버넌스 | bias detection, guardrail, fairness/compliance | 위 bullet |
| 인프라 GPU | DCGM, GPU_UTIL, VRAM | 10.2 |
| drift/bias 운영 | drift 감지·자동화, bias 검증 워크플로 | 11.6 |
서빙 인프라의 GPU 메트릭 관측 파이프라인(DCGM → Prometheus)은 10.2에서 다뤘다. drift 대응 자동화·bias 검증은 11.6에서 이어진다.
Drift 감지 기초
배포된 모델의 정확도가 점진적으로 떨어질 때, 입력이 바뀐 건지 입력↔출력 관계가 바뀐 건지를 구분해야 대응이 달라진다.
| 종류 | 무엇이 변하나 | 통계적 표현 | 예시 |
|---|---|---|---|
| Data drift (covariate shift) | 입력 분포 P(X) | 학습 때 본 입력과 다른 입력 | 챗봇 학습은 영어 위주인데 운영 중 한국어 비중 급증 |
| Concept drift | 관계 P(Y|X) | 같은 X에 정답 Y가 바뀜 | “안전한 답변” 정책 변경으로 같은 질문의 적절한 답이 달라짐 |
| Label drift | 출력 분포 P(Y) | 클래스 비중 변화 | 신규 캠페인으로 사기 거래 비중이 평소 1% → 5%로 증가 |
종류를 구분했으면 다음은 어디를 관측할지다. data drift는 입력·예측 분포 쪽 신호로 빠르게 의심할 수 있고, concept drift는 ground truth 비교가 정공법이다. label drift는 출력 분포 자체를 추적한다. 실무 모니터링 파이프라인은 아래 신호를 조합해 쓴다.
| 신호 | 무엇을 보는가 |
|---|---|
| 입력 통계 모니터링 | feature별 분포 비교 (KS test, PSI, Wasserstein distance) |
| 임베딩 거리 | 학습셋 임베딩 중심으로부터의 거리 분포 |
| Prediction confidence | softmax·logit 분포 변화 — confidence 하락 시 shift 의심 |
| Ground truth 비교 | 실제 정답 수집 후 accuracy/loss 재계산 — concept drift 정공법 |
data drift는 입력 모니터링만으로 분~시간 단위로 빠르게 감지 가능하다. concept drift는 ground truth 수집 지연 때문에 검출이 늦다. 둘 다 정확도 하락으로 나타날 수 있어 분류가 운영 방향을 가른다.
- data drift → 재학습 / 도메인 adaptation
- concept drift → 라벨링 기준 재정의 + 데이터 재수집부터
통계적 측정(KL divergence, chi-square, KS test)과 자동 재학습 파이프라인은 11.6에서 다룬다.
K8s 위 GenAIOps 도구 — 한눈에
K8s는 워크플로우 오케스트레이션·분산 학습·실험 추적에 확장성과 유연성을 제공한다. 주요 플랫폼은 K8s를 자원 추상화 계층으로 활용한다.
| 도구 | 주된 책임 | K8s 의존도 |
|---|---|---|
| Kubeflow | end-to-end ML (notebooks, pipelines, training, serving, HPO) | K8s-native (CRD·controller) |
| MLflow | 실험 추적 + 모델 레지스트리 + 패키징 | K8s 없이도 동작, 배포 시 HA·확장 이점 |
| Argo Workflows | 범용 K8s-native workflow engine (DAG) | K8s-native (CRD) |
| Ray (KubeRay) | 분산 Python (학습·tuning·serving·data) | KubeRay operator로 통합 |
각 도구의 책임 경계·비교는 11.2 ~ 11.6에서 순차 정리한다.
정리
| 영역 | 핵심 포인트 |
|---|---|
| GenAIOps | MLOps + GenAI 고유 과제 (거대 모델, 프롬프트·RAG, 비결정적 출력) |
| 5단계 | data → experiment → adapt → serve → monitor 피드백 루프 |
| Serving | real-time (low-latency endpoint) vs batch (주기적 대량 추론) |
| Drift | data drift(입력) vs concept drift(관계) — 대응 전략이 다름 |
| K8s 도구 | Kubeflow / MLflow / Argo / Ray — 역할이 겹치지 않게 조합 |

댓글남기기