
[GenAI] GenAI on K8s: 4.3 - Fine-tuning (QLoRA)
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 4장의 학습 내용을 바탕으로 합니다
이전 글에서 RAG를 통해 LLM 외부에서 prompt를 풍부하게 만드는 패턴을 다뤘다. 이번 글에서는 반대 방향의 접근인 Fine-tuning — 모델 가중치 자체에 도메인 지식을 새기는 방법을 다룬다.
TL;DR
- Fine-tuning은 모델 가중치에 도메인 지식을 내재화하는 기법이다. hallucination 감소, 응답 일관성 향상, 추론 비용 절감 등 5가지 효과가 있다
- PEFT(Parameter-Efficient Fine-Tuning)는 전체 가중치 대신 소수의 파라미터만 학습한다. LoRA는 원 가중치 옆에 저랭크 행렬 A·B를 붙여 학습하며, 추론 시 merge하면 오버헤드가 0이다
- QLoRA = 4-bit 양자화(Quantization) + LoRA. T4 16GB 한 장으로 8B 모델 fine-tune이 가능하다
- Colab T4에서 Llama-3-8B를 37쌍 합성 데이터로 QLoRA fine-tune한 결과, base 모델의 hallucination이 사라지고 도메인 사실을 정확히 인용했다. 총 비용 약 $0.004, 학습 시간 17분 30초
- RAG와 Fine-tuning은 경쟁이 아니라 상호 보완이다. 데이터 최신성이 중요하면 RAG, 도메인 jargon과 사실 정확도가 중요하면 Fine-tuning, 둘 다 필요하면 하이브리드
Fine-tuning
Fine-tuning(파인튜닝)은 사전학습된 LLM의 가중치를 도메인 데이터로 추가 학습시키는 기법이다. 이전 글의 RAG가 추론 시점에 외부 context를 prompt에 주입하는 방식이었다면, Fine-tuning은 학습 시점에 도메인 지식을 모델의 가중치 자체에 반영한다. 차이가 발생하는 지점은 명확하다: RAG는 prompt가 길어지고(입력 변경), Fine-tuning은 모델 파라미터가 바뀐다(모델 변경). 같은 질문에 대해 RAG는 매번 검색 비용이 들지만, Fine-tuning은 한 번 학습하면 짧은 prompt로 바로 응답할 수 있다.
- Hallucination 감소: 도메인 사실이 가중치에 새겨져, next-token 확률에서 사실 토큰이 우선순위를 갖는다
- 응답 consistency 향상: 학습 데이터의 표현·포맷 패턴이 가중치에 내재화되어, 같은 질문에 일관된 형식으로 응답한다
- Proprietary data 보호: 가중치에 학습하므로 추론 시 외부 데이터 전송이 없다 (RAG는 매 query마다 docs를 prompt에 전송)
- Query당 추론 비용 절감: 짧은 prompt로 응답 가능하다 (RAG는 검색 docs를 prompt에 붙이므로 입력 토큰이 늘어남)
- 모델 behavior 제어: 학습 데이터의 톤·포맷·도메인 용어가 그대로 응답에 반영된다
Trade-off도 있다:
- Computationally expensive: GPU + 학습 시간 필요
- 고품질 데이터셋 큐레이션: 쓰레기가 들어가면 쓰레기가 나온다
- 도메인 변화 시 re-fine-tune: RAG는 벡터 DB만 갱신하면 되지만, fine-tuning은 모델을 다시 학습시켜야 한다
PEFT: Adapter vs LoRA
Fine-tuning의 가장 단순한 접근은 모델의 모든 가중치를 도메인 데이터로 다시 학습시키는 것이다(full fine-tuning). 그러나 이 방식은 메모리 비용이 막대하다. 8B 모델 기준으로 가중치만 FP32로 32GB, 여기에 gradient와 optimizer state(Adam 기준 가중치의 2배)까지 합하면 100GB 이상의 GPU 메모리가 필요하다. A100 80GB 한 장으로도 부족한 수준이다.
이 문제를 해결하기 위해 등장한 것이 PEFT(Parameter-Efficient Fine-Tuning, 파라미터 효율적 파인튜닝)다. 전체 가중치를 건드리는 대신, 소수의 추가 파라미터만 학습하여 full fine-tuning에 근접한 성능을 얻는 기법이다. 대표적으로 Adapter와 LoRA 두 가지가 있다.
| Adapter-based | LoRA | |
|---|---|---|
| 추가 모듈 위치 | 레이어 사이 (직렬 삽입) | 가중치 옆 (병렬 add) |
| 학습되는 것 | 새로 넣은 작은 MLP (adapter) | 두 작은 행렬 A, B |
| 원 가중치 | frozen | frozen |
| 추론 latency | ↑ (forward 경로에 추가 단계) | 동일 (merge 시 W’ = W + B·A로 0 overhead) |
구조 비교
두 방식의 핵심 차이는 새로 학습하는 모듈이 원 가중치 W에 대해 직렬로 붙느냐, 병렬로 붙느냐다.
Adapter는 원 가중치 W의 출력 뒤에 작은 MLP를 직렬로 끼워 넣는다. input → W·x → adapter → 다음 레이어 순서로 forward가 흐른다. W는 frozen이고 adapter만 학습된다. 문제는 추론 시에도 이 adapter를 거쳐야 하므로 forward 경로가 길어져 latency가 증가한다는 것이다.
LoRA는 원 가중치 W 옆에 두 개의 작은 행렬 A, B를 병렬로 붙인다. input이 W·x 경로와 A·x → B·(A·x) 경로로 동시에 흐르고, 두 결과를 합산한다. W는 역시 frozen이고 A, B만 학습된다. 결정적 장점은 학습이 끝난 뒤 W’ = W + B·A로 merge하면 원래 모델과 완전히 동일한 구조가 되어, 추론 오버헤드가 0이라는 점이다.
Adapter (직렬, 추가 forward):
input → [W]·x → [adapter (작은 MLP)] → 다음 레이어
↑ ↑
frozen learnable
LoRA (병렬, 합산):
input ─┬─→ [W]·x ──────────────┐
│ ↑ │
│ frozen │
└─→ [A]·x → [B]·(A·x) ──┴─→ (W + B·A)·x → 다음 레이어
↑ ↑
learnable learnable
LoRA 핵심 원리
LoRA(Low-Rank Adaptation)의 핵심 아이디어는 간단하다. 원 가중치 W(예: 4096×4096)를 통째로 업데이트하는 대신, 변화량 ΔW를 저랭크(low-rank)로 근사하는 것이다.
full fine-tuning에서는 W 자체를 W + ΔW로 갱신하므로, ΔW도 W와 같은 크기(4096×4096 = ~1,680만 개)의 파라미터를 학습해야 한다. LoRA는 이 ΔW를 두 개의 작은 행렬 B·A로 분해한다. A는 입력 차원을 작은 rank r로 압축하고, B는 다시 원래 차원으로 복원한다.
원래 layer forward: y = W·x (W shape: 4096×4096, frozen)
LoRA 적용 후: y = W·x + B·A·x (W 여전히 frozen)
└─ A shape: 4096 × r (r=32, 입력 → 저차원)
└─ B shape: r × 4096 (저차원 → 출력)
r=32일 때 하나의 레이어에 추가되는 파라미터 수를 계산해 보면: A가 4096 × 32 = 131,072개, B가 32 × 4096 = 131,072개, 합계 262,144개다. 원래 W의 파라미터 수(4096 × 4096 = 16,777,216개)의 1.6%에 불과하다.
여기서 r(rank)은 LoRA의 핵심 하이퍼파라미터다. 원 가중치 W는 r과 무관하게 항상 frozen이므로, 사전학습된 지식은 r=1이든 r=64이든 그대로 보존된다. r이 제어하는 건 ΔW(= B·A)가 도메인 데이터를 얼마나 잘 학습할 수 있느냐 — 즉 fine-tuning의 표현력이다.
예를 들어, “cashback은 2%이고 연간 $1000 한도”라는 단순한 사실 하나를 학습시키는 데는 작은 r로 충분하다. 그러나 도메인 전체의 복잡한 패턴(다양한 질문 형식에 대한 일관된 응답, 여러 사실 간의 관계 등)을 학습시키려면 r이 커야 한다.
- r이 커지면: 학습 가능한 파라미터가 많아져 fine-tuning 표현력이 높아진다. 대신 메모리·학습 시간이 늘고, 학습 데이터가 적을 때 과적합(overfitting) 위험도 높아진다.
- r이 작으면: 메모리·속도 면에서 효율적이고 과적합 위험이 낮지만, 도메인 데이터의 복잡한 패턴을 충분히 반영하지 못할 수 있다.
본 실습에서 r=32를 쓴 건 T4 16GB에서 동작 가능한 범위 내에서 충분한 표현력을 확보하기 위한 선택이다.
target_modules
LoRA 어댑터를 어느 가중치 행렬에 붙일지 결정하는 것이 target_modules다. Transformer 레이어에는 여러 개의 독립적인 가중치 행렬이 있고, 각각에 개별적으로 LoRA를 붙일지 말지 선택할 수 있다. Llama-3 기준으로 후보는 다음과 같다.
| 모듈 | 역할 |
|---|---|
| q_proj, k_proj, v_proj, o_proj | Attention Q/K/V/Output projection |
| gate_proj, up_proj, down_proj | Llama FFN의 SwiGLU 3개 projection |
| lm_head | hidden → vocab 차원 출력 |
모든 모듈에 붙일 필요는 없다. 어떤 모듈에 붙이느냐에 따라 조정 범위가 달라진다.
- Q/V만 (LoRA 원 논문의 기본 설정): “어디에 주목할지”(Q)와 “무엇을 참조할지”(V)만 조정한다. 가장 경량이고, 많은 task에서 충분한 성능을 보인다.
- Q/K/V/O 전부: Attention 메커니즘 전체를 조정한다. Q/V만으로 부족한 복잡한 도메인에서 성능이 올라간다.
- FFN(gate/up/down)까지 (본 실습): Attention뿐 아니라 FFN의 지식 저장 영역까지 조정한다. Transformer에서 factual knowledge는 주로 FFN 레이어에 저장된다는 연구 결과가 있어, 도메인 사실을 주입하려면 FFN까지 포함하는 것이 효과적이다.
본 실습에서 7개 모듈 전부(Q/K/V/O + gate/up/down)에 붙인 건, 30행짜리 소량 데이터로 최대한 도메인 사실을 주입하려는 선택이다. 프로덕션에서는 데이터량과 GPU 예산에 따라 Q/V만으로 시작해서 점진적으로 늘리는 것이 일반적이다.
LoRA를 적용하면 전체 파라미터의 약 2%만 학습 대상이 된다. gradient와 optimizer state를 유지해야 하는 대상이 이 2%뿐이므로 full fine-tuning 대비 메모리 사용량이 극적으로 줄어든다. 구체적인 LoraConfig 설정, 각 인자의 의미, lm_head 제외 트러블슈팅은 아래 실습 § LoRA 적용에서 코드와 함께 다룬다.
그런데 여기서 한 가지 문제가 남는다. 학습 파라미터가 2%로 줄었더라도, base 모델 자체는 여전히 GPU에 올려야 한다. forward pass에서 W·x를 계산해야 하기 때문이다.
이번 실습에서 사용할 GPU는 Google Colab에서 무료로 제공하는 NVIDIA T4다. T4는 Turing 아키텍처 기반의 추론·경량 학습용 GPU로, VRAM이 16GB다. 데이터센터 GPU 중에서는 가장 저렴한 축에 속하지만, QLoRA 덕분에 8B 모델도 이 한 장으로 fine-tune할 수 있다.
문제는 8B 모델을 FP16으로 올리면 그것만으로 16GB — T4의 전체 VRAM을 잡아먹는다는 것이다. LoRA 파라미터와 optimizer state를 올릴 공간이 없다.
QLoRA = Quantization + LoRA
이 문제를 해결하기 위해 등장한 것이 QLoRA(Quantized LoRA, Dettmers et al. 2023)다. 핵심 아이디어는 간단하다: base 모델의 가중치를 양자화(Quantization)해서 VRAM을 아끼고, 그 위에 LoRA를 붙여 학습하는 것이다. 두 기법을 조합하면 다음과 같다.
| 기법 | 하는 일 | 효과 |
|---|---|---|
| Quantization (4-bit NF4) | frozen인 base 가중치를 32-bit → 4-bit로 압축하여 GPU에 올림 | 8B 모델이 4GB에 들어감 |
| LoRA (r=32, α=64) | 압축된 base 위에 저랭크 행렬 A, B만 FP16/BF16으로 학습 | 학습 대상 파라미터 2%로 제한 |
| QLoRA = Q + LoRA | 위 두 가지를 동시에 적용 | T4 16GB 한 장으로 8B fine-tune 가능 |
양자화가 왜 이렇게 효과가 큰지, VRAM을 계산해 보면 체감할 수 있다.
VRAM 계산
모델 가중치가 GPU 메모리에서 차지하는 크기는 “파라미터 수 × 파라미터당 바이트 수”로 결정된다. precision에 따른 차이는 다음과 같다.
| Precision | Bytes/Param | Llama-3-8B |
|---|---|---|
| FP32 | 4 | 32 GB |
| FP16 / BF16 | 2 | 16 GB |
| INT8 | 1 | 8 GB |
| INT4 (4-bit) | 0.5 | 4 GB ← 본 실습 |
FP32 → 4-bit로 바꾸는 것만으로 32GB → 4GB, 8배 압축이다. 4-bit 양자화로 모델 가중치를 4GB로 줄이면, T4의 나머지 12GB를 LoRA 파라미터 + optimizer state + activation + KV cache에 활용할 수 있다. 이것이 T4 16GB 한 장으로 8B 모델을 학습할 수 있는 이유다.
실행 환경 결정
T4 16GB로 8B 모델을 학습할 수 있다는 걸 확인했으니, 실제로 어디서 T4를 확보할지 결정해야 한다. 후보로 세 가지를 비교했다.
| 옵션 | 1회 비용 | 셋업 시간 | 적합한 경우 |
|---|---|---|---|
| Colab 무료 T4 | $0 | 5분 | 알고리즘·코드 흐름 학습 |
| EC2 g5.xlarge Spot | ~$0.30~0.50/h | 30분 | 클라우드 GPU 인프라 경험 |
| EKS + g5.xlarge | ~$1.17/h | 1~2시간 | K8s 위에서 GPU 워크로드 운영 |
이번 실습의 목적은 QLoRA의 알고리즘과 코드 흐름을 이해하는 것이지, 인프라 구축이 아니다. 비용 $0, 셋업 5분이라는 압도적인 효율을 고려하면 Colab 무료 T4가 최선이다. EC2나 EKS는 나중 챕터에서 K8s 위의 GPU 워크로드를 다룰 때 다시 검토하면 된다.
실습: Llama-3-8B QLoRA Fine-tuning (Colab T4)
실습의 핵심은 동일한 질문에 대해 fine-tune 전후 응답을 비교하는 것이다. 전체 흐름은 다음과 같다.
- 데이터셋 준비 + 모델 로딩 + 토크나이저 설정
- Base 모델 응답 확인 — fine-tune 전 baseline
- LoRA 적용 + 학습 실행
- Fine-tuned 모델 응답 확인 — 도메인 지식 내재화 검증
데이터셋 준비
가상의 MyElite 멤버십 프로그램에 대한 사실 기반 Q&A 데이터셋을 사용한다.
| 사실 | 값 |
|---|---|
| Annual subscription fee | $99 (non-refundable) |
| Discounts | 직접 할인 없음, 대신 early access |
| Cashback | 2%, capped at $1000/year, 연 1회 gift card |
| Sales events early access | Black Friday, Labor Day, Cyber Monday, Christmas |
| Extended support | wear and tear 지원 |
책(p.77~78)에서도 이 데이터셋을 ChatGPT로 합성(synthetic data generation)했다고 명시하고 있다.
“To fine-tune Llama3, we have created a synthetic loyalty program FAQ dataset using ChatGPT.” — Generative AI on Kubernetes, p.77
다만 책의 upstream repo에는 실제 jsonl 파일이 포함되어 있지 않고 가이드라인만 제공한다. 본 실습에서는 책의 가이드라인을 그대로 따라 GPT-3.5로 37쌍의 Q&A를 합성했다. 비용은 $0.0043.
- Train: 30쌍
- Validation: 7쌍
모든 prompt에는 [MyElite Loyalty Program FAQ]: prefix를 붙였다. 책(p.78)이 의도한 장치로, Llama-3가 이미 학습한 다른 loyalty program FAQ와 구분해서 학습하도록 하기 위함이다.
모델 로딩 + 4-bit 양자화
bitsandbytes는 GPU 위에서 양자화된 연산을 수행하는 CUDA 커널 라이브러리다. QLoRA 논문의 제1저자인 Tim Dettmers가 만들었으며, Hugging Face Transformers와 통합되어 BitsAndBytesConfig 설정 클래스를 통해 모델 로딩 시 양자화를 적용할 수 있다.
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
base_model_id = "meta-llama/Meta-Llama-3-8B"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit로 양자화해 GPU에 올림
bnb_4bit_use_double_quant=True, # 양자화 상수도 다시 양자화 (~0.4 bit/param 절약)
bnb_4bit_quant_type="nf4", # NormalFloat 4-bit
bnb_4bit_compute_dtype=torch.bfloat16, # 계산은 bf16으로
)
model = AutoModelForCausalLM.from_pretrained(
base_model_id,
quantization_config=bnb_config,
device_map="auto",
)
| 설정 | 의미 |
|---|---|
load_in_4bit=True |
모델 가중치를 4-bit로 양자화하여 GPU에 적재 |
bnb_4bit_use_double_quant=True |
양자화 상수(scale factor)까지 다시 양자화. 파라미터당 ~0.4 bit 추가 절약 |
bnb_4bit_quant_type="nf4" |
NormalFloat 4-bit. 정규분포를 가정한 최적 양자화 |
bnb_4bit_compute_dtype=torch.bfloat16 |
forward/backward 연산은 bfloat16으로 수행 |
device_map="auto" |
사용 가능한 GPU에 자동 배치 |
토크나이저 + 데이터 전처리
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
base_model_id,
padding_side="left", # decoder 모델은 left padding
add_eos_token=True, # 문장 끝에 EOS 토큰 추가
add_bos_token=True, # 문장 시작에 BOS 토큰 추가
)
tokenizer.pad_token = tokenizer.eos_token # pad 토큰을 EOS로 설정
def formatting_func(example):
return f"### Question: {example['prompt']}\n ### Answer: {example['response']}"
formatting_func은 각 Q&A 쌍을 ### Question: ... ### Answer: ... 형식의 단일 문자열로 변환한다. 이 포맷이 fine-tune 후 모델이 학습하는 입출력 패턴이 된다.
Base 모델 응답 (fine-tune 전)
Fine-tuning 전에 base 모델의 응답을 먼저 확인한다. 동일한 질문에 대해 fine-tune 전후를 비교하기 위한 기준선(baseline)이다.
eval_prompt = "### Question: What is the maximum cashback I can earn?\n ### Answer: "
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
output = tokenizer.decode(
model.generate(**model_input, max_new_tokens=256)[0],
skip_special_tokens=True,
)
print(output)
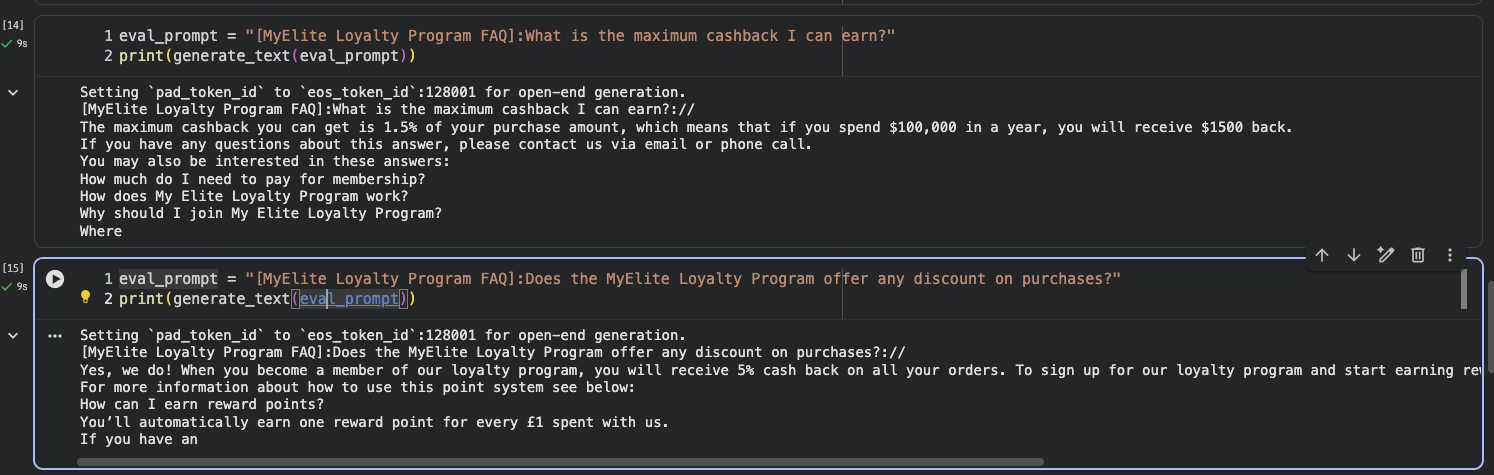
Base 모델의 응답은 hallucination으로 가득하다:
- “1.5% of your purchase amount… $100,000… $1500…” — 가상의 숫자
- 가짜 FAQ 자동 생성
- 자기 답끼리도 모순 (1.5% vs 5%)
- 가상 URL, 영국 파운드(£) 등 실존하지 않는 정보
MyElite 프로그램에 대해 아무것도 모르니 당연하다. 이전 RAG 글에서 no-RAG 호출 시 hallucination을 확인한 것과 같은 현상이다. 사전학습 데이터에 없는 내용을 물으면, temperature=0이든 아니든 가장 확률 높은 토큰을 이어붙일 뿐이므로 그럴듯한 거짓말을 생성할 수밖에 없다. RAG는 이 문제를 외부 문서 주입으로 우회했지만, fine-tuning은 모델 가중치 자체에 도메인 지식을 내재화해서 해결하려는 접근이다.
LoRA 적용
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32,
lora_alpha=64,
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
bias="none",
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
trainable params: 83886080 || all params: 4624486400 || trainable%: 1.813954518279046
전체 파라미터 약 46억 개 중 학습 대상은 약 8,400만 개로 1.81%에 불과하다. 각 인자의 의미는 다음과 같다.
| 인자 | 의미 |
|---|---|
r=32 |
저랭크 근사의 rank. 클수록 표현력 ↑, 파라미터 수 ↑ |
lora_alpha=64 |
LoRA 출력에 곱해지는 스케일링 팩터. 실제 스케일 = alpha / r = 2.0 |
target_modules |
LoRA를 부착할 레이어 목록. 원래 8개(lm_head 포함)에서 7개로 조정 |
bias="none" |
bias 파라미터는 학습 대상에서 제외 |
lora_dropout=0.05 |
5% 확률로 어댑터 출력을 드롭 → overfitting 방지 |
task_type="CAUSAL_LM" |
autoregressive 다음 토큰 예측 task |
lm_head 트러블슈팅
원래 target_modules에 lm_head를 포함시키려 했으나 에러가 발생했다:
ImportError: torchao 0.10.0, need >=0.16
원인: Llama-3의 tie_word_embeddings=True 설정으로 lm_head가 embed_tokens와 가중치를 공유(tied weights)한다. PEFT가 tied weight를 처리하기 위해 torchao를 호출하는데, Colab의 torchao 버전이 낮아 발생한 문제다.
해결: lm_head를 target_modules에서 제거했다. 88M → 84M으로 파라미터가 소폭 줄었지만(1.81%), 도메인 학습에는 문제없다. lm_head는 hidden state를 vocab 차원으로 매핑하는 출력 레이어로, attention과 FFN 레이어에 도메인 지식이 충분히 반영되면 lm_head는 기존 가중치로도 올바른 토큰을 선택할 수 있다.
모델 구조: LoRA 적용 전 vs 후
LoRA 적용 전 — 4-bit 양자화만 된 base 모델:
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear4bit(in=4096, out=4096, bias=False)
(k_proj): Linear4bit(in=4096, out=1024, bias=False)
(v_proj): Linear4bit(in=4096, out=1024, bias=False)
(o_proj): Linear4bit(in=4096, out=4096, bias=False)
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in=4096, out=14336, bias=False)
(up_proj): Linear4bit(in=4096, out=14336, bias=False)
(down_proj): Linear4bit(in=14336, out=4096, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in=4096, out=128256, bias=False)
)
모든 projection이 Linear4bit — bitsandbytes 4-bit 양자화가 적용된 상태다. k_proj/v_proj의 out_features=1024는 Llama-3가 Grouped-Query Attention(GQA)을 사용하기 때문이다. 32개 attention head 중 KV head는 8개만 사용(4:1 grouping)하여 4096 / 4 = 1024 차원으로 축소한다.
LoRA 적용 후 — get_peft_model() 호출 결과:
PeftModelForCausalLM(
(base_model): LoraModel(
(model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): lora.Linear4bit(in=4096, out=4096, r=32)
(k_proj): lora.Linear4bit(in=4096, out=1024, r=32)
(v_proj): lora.Linear4bit(in=4096, out=1024, r=32)
(o_proj): lora.Linear4bit(in=4096, out=4096, r=32)
)
(mlp): LlamaMLP(
(gate_proj): lora.Linear4bit(in=4096, out=14336, r=32)
(up_proj): lora.Linear4bit(in=4096, out=14336, r=32)
(down_proj): lora.Linear4bit(in=14336, out=4096, r=32)
)
)
)
(norm): LlamaRMSNorm((4096,))
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in=4096, out=128256)
)
)
)
핵심 변화:
- 최상위 클래스:
LlamaForCausalLM→PeftModelForCausalLM(LoraModel(LlamaForCausalLM))— 두 겹의 wrapping이 추가됐다. - projection 레이어:
Linear4bit→lora.Linear4bit— 기존 frozen 가중치 위에 LoRA 어댑터(A, B 행렬 + dropout)가 병렬로 부착됐다. - lm_head: 일반
Linear로 남아 있다 (frozen, LoRA 미적용).
학습 실행
import transformers
output_dir = "./results"
trainer = transformers.Trainer(
model=model,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_val_dataset,
args=transformers.TrainingArguments(
output_dir=output_dir,
warmup_steps=2,
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
gradient_checkpointing=True, # activation 재계산으로 메모리 절약
max_steps=200,
learning_rate=2.5e-5,
bf16=True, # forward/backward 16-bit
optim="paged_adamw_8bit", # optimizer state 8-bit + paging
logging_steps=25,
save_strategy="steps",
save_steps=25,
eval_strategy="steps",
eval_steps=25,
do_eval=True,
report_to="wandb", # W&B로 메트릭 전송
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()
T4 16GB에 8B 모델 학습이 가능한 이유
T4 한 장(16GB)으로 8B 모델을 학습하려면 GPU 메모리에 가중치, optimizer state, activation, 연산 결과가 모두 올라가야 한다. 이 중 하나라도 FP32 그대로 두면 메모리가 터진다. 위 TrainingArguments에는 이를 해결하는 4가지 기법이 동시에 적용되어 있다.
load_in_4bit=True(가중치): 모델 가중치를 FP16(16GB)이 아닌 4-bit(~4GB)로 양자화해서 GPU에 올린다. QLoRA의 핵심이자 가장 큰 절감 효과다.optim="paged_adamw_8bit"(optimizer state): AdamW는 파라미터마다 momentum과 variance 두 텐서를 저장한다. 이를 FP32가 아닌 8-bit로 양자화하고, GPU VRAM이 부족하면 CPU RAM으로 paging한다.gradient_checkpointing=True(activation): forward pass의 중간 activation을 메모리에 저장하지 않고, backward pass에서 필요할 때 재계산한다. VRAM을 ~50% 절약하는 대신 학습 시간이 ~20% 늘어나는 trade-off다.bf16=True(연산): forward/backward 연산을 FP32가 아닌 BFloat16으로 수행한다.BitsAndBytesConfig의bnb_4bit_compute_dtype=torch.bfloat16과 맞춰야 한다.
이 중 NF4 양자화(load_in_4bit)와 paged optimizer(paged_adamw_8bit)는 QLoRA 논문이 제안한 기법이고, gradient checkpointing과 bf16 mixed precision은 이전부터 존재하던 범용 기법이다. QLoRA의 기여는 전자 두 가지를 통해 “4-bit로 양자화된 모델 위에서도 LoRA 학습이 가능하다”는 것을 보여준 데 있고, 나머지 두 기법과 결합하면 T4 16GB 한 장으로 8B 모델 학습이 현실적으로 가능해진다.
학습 결과와 overfitting
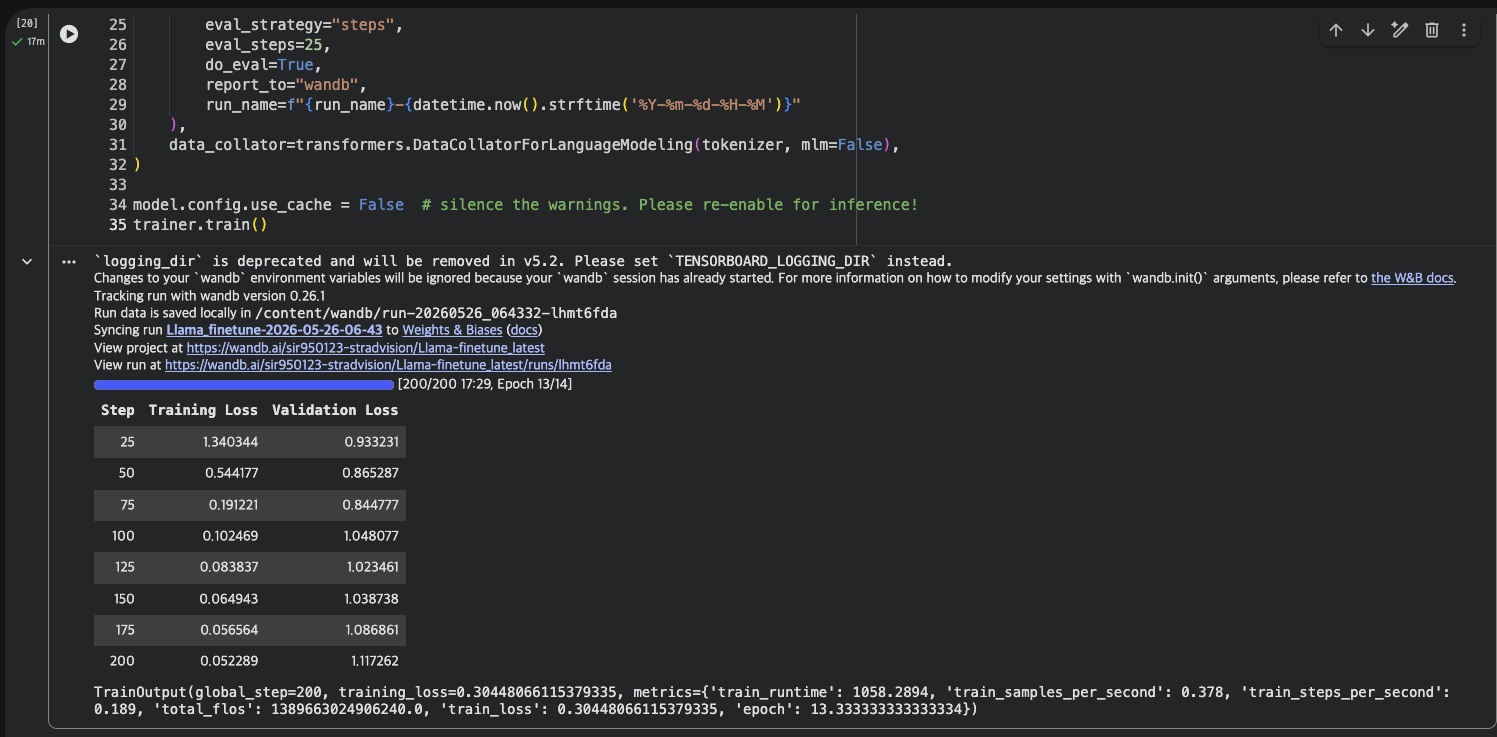
| Step | Training Loss | Validation Loss |
|---|---|---|
| 25 | 1.340344 | 0.933231 |
| 50 | 0.544177 | 0.865287 |
| 75 | 0.191221 | 0.844777 ← val loss 최소점 |
| 100 | 0.102469 | 1.048077 |
| 125 | 0.083837 | 1.023461 |
| 150 | 0.064943 | 1.038738 |
| 175 | 0.056564 | 1.086861 |
| 200 | 0.052289 | 1.117262 |
TrainOutput(global_step=200, training_loss=0.30448, train_runtime=1058.29s,
train_samples_per_second=0.378, train_steps_per_second=0.189, epoch=13.33)
training loss는 200 step까지 꾸준히 감소하지만, validation loss는 step 75에서 최솟값(0.845)을 찍고 이후 계속 상승한다. 전형적인 overfitting 패턴이다.
원인은 데이터 크기에 있다. train 30행으로 13 epoch(200 step)을 돌렸으니, 같은 데이터를 13번 반복 학습한 셈이다. step 75 이후부터 모델은 도메인 지식을 “이해”하는 게 아니라 훈련 데이터를 “암기”하기 시작한 것이다. 그럼에도 아래 응답 비교에서 보듯 fine-tuned 모델은 도메인 질문에 정확히 답하므로, 30행이라는 극소량 데이터로도 QLoRA가 도메인 지식을 주입할 수 있음을 확인할 수 있다.
프로덕션에서는 EarlyStoppingCallback(patience=2)를 추가해 step 75~100에서 학습을 자동 종료하는 것이 일반적이다.
wandb 대시보드
W&B(Weights & Biases)로 전송된 학습 메트릭을 시각적으로 확인할 수 있다.
train/loss
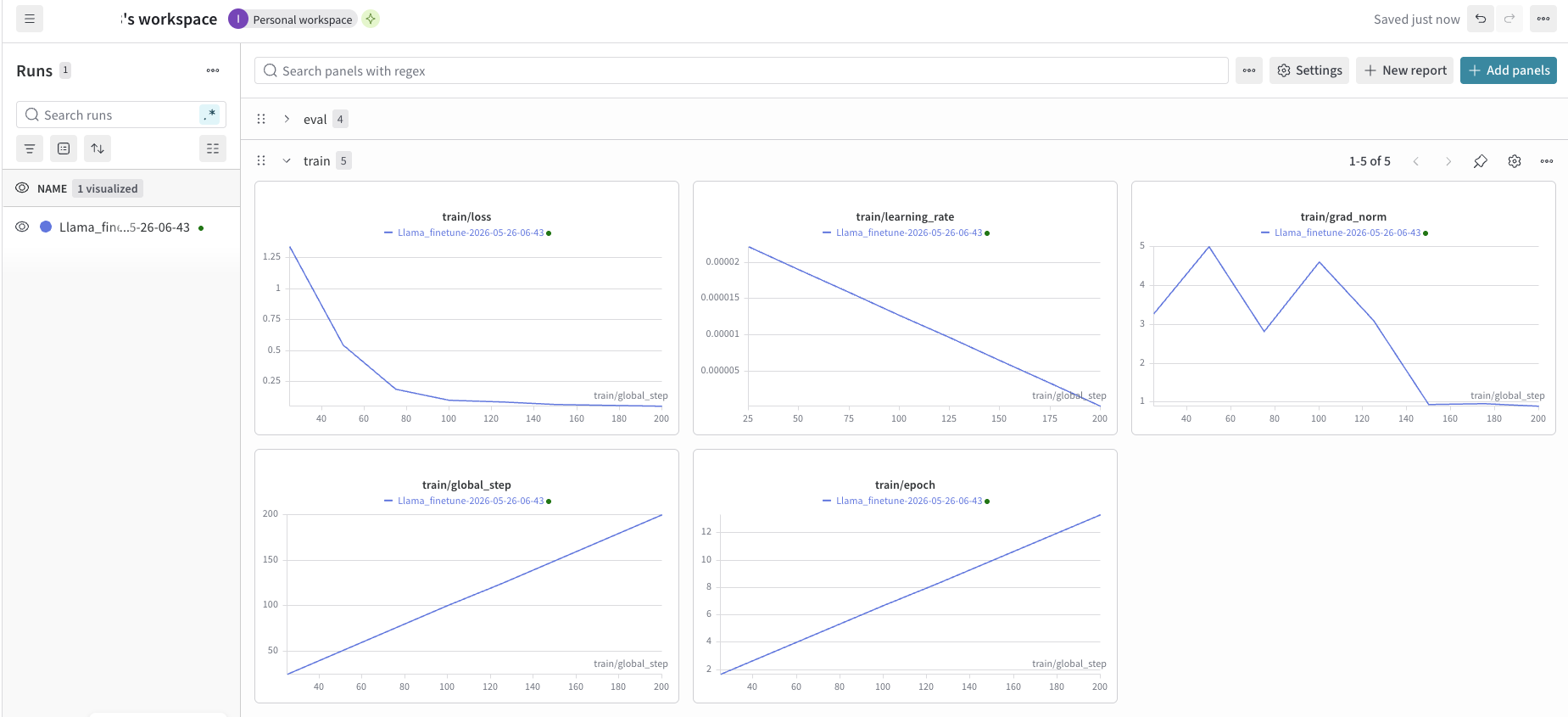
1.34 → 0.05로 지수적 감소. 모델이 훈련 데이터의 패턴을 빠르게 학습하고 있다.
eval/loss
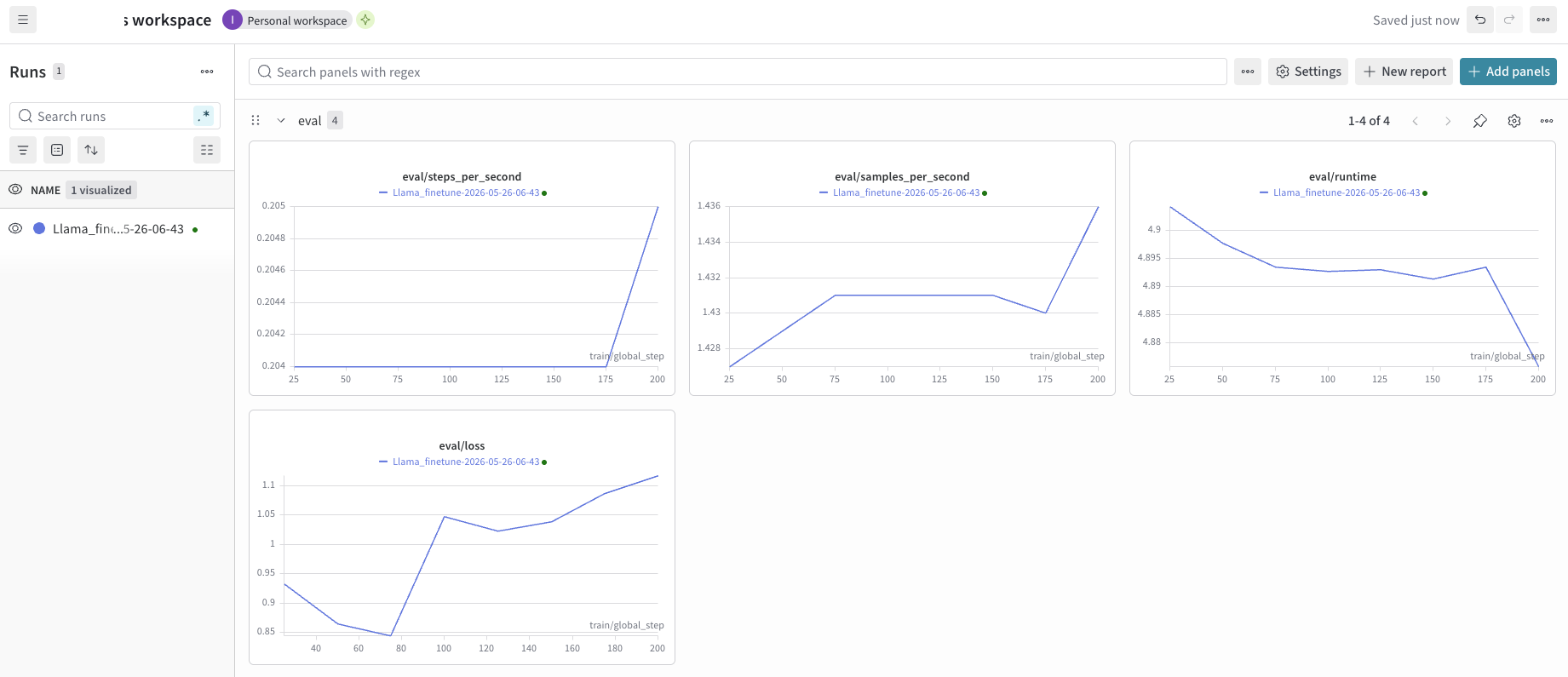
U-자 곡선이 명확하다: 0.93 → 0.84(최솟값) → 1.12. step 75 이후로는 overfitting이 진행되고 있다.
GPU 사용량
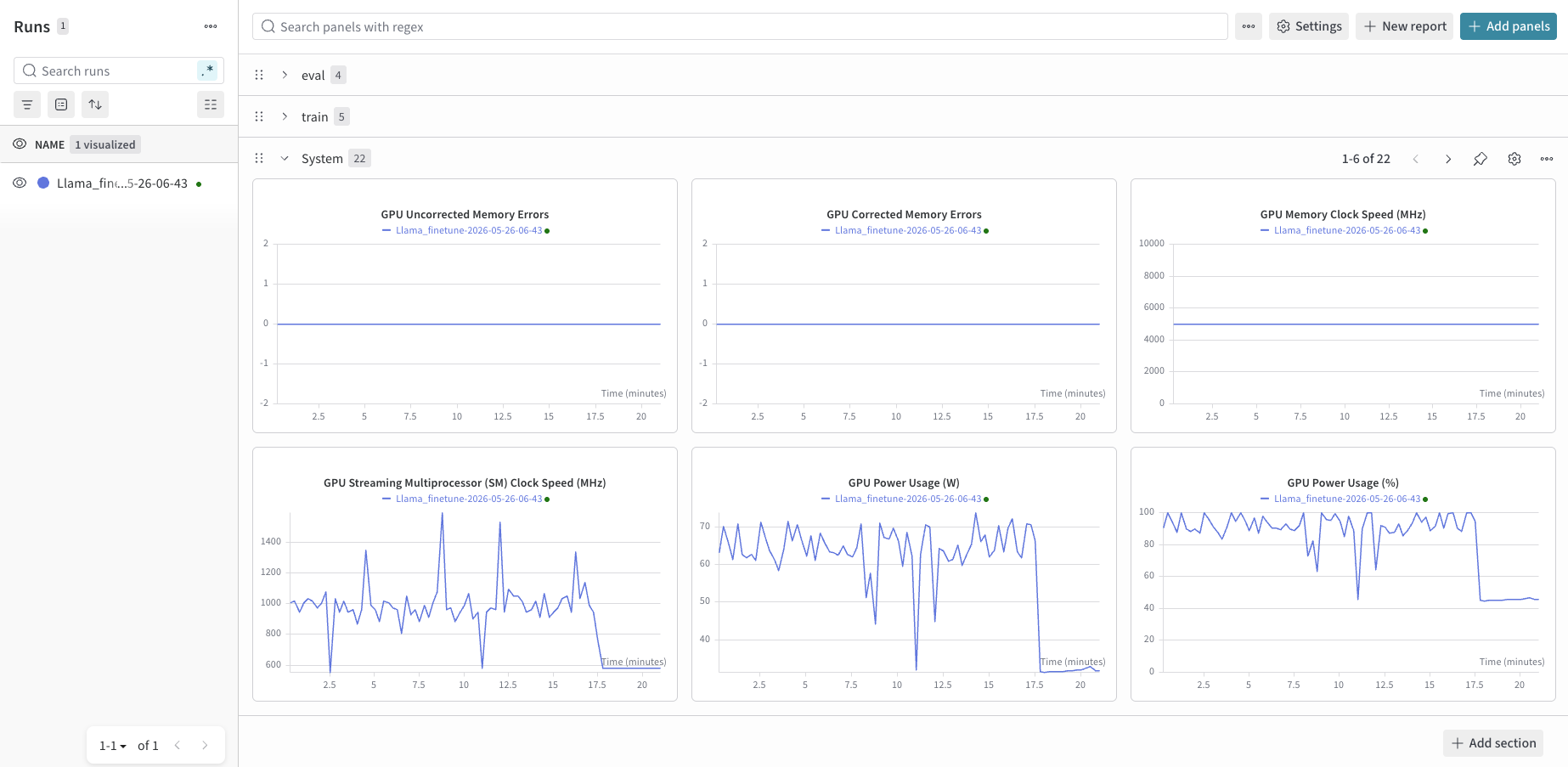
GPU Power 50~70W 범위에서 안정적으로 유지. 17.5분 즈음에 급락하는 것은 학습이 완료된 시점이다.
Fine-tuned 모델 응답 (fine-tune 후)
학습 완료 후 동일한 질문으로 fine-tuned 모델의 응답을 확인한다.
ft_model = AutoModelForCausalLM.from_pretrained(
base_model_id, quantization_config=bnb_config, device_map="auto"
)
ft_model = PeftModel.from_pretrained(ft_model, "./results/checkpoint-200")
eval_prompt = "### Question: What is the maximum cashback I can earn?\n ### Answer: "
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
ft_model.eval()
with torch.no_grad():
output = tokenizer.decode(
ft_model.generate(**model_input, max_new_tokens=256)[0],
skip_special_tokens=True,
)
print(output)
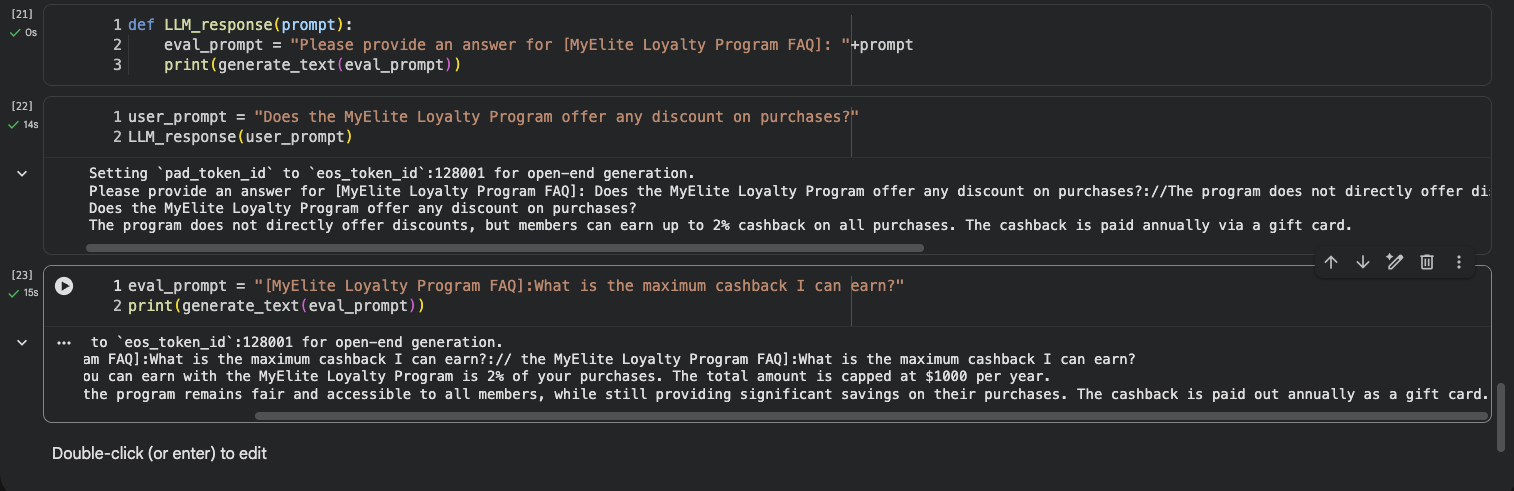
Fine-tuned 모델은 도메인 사실을 정확히 인용했다:
- “2% of your purchases… capped at $1000 per year… paid out annually as a gift card” — 학습 데이터의 사실과 정확히 일치
Base vs Fine-tuned 비교
| Eval Prompt | Base 응답 (STEP A) | Fine-tuned 응답 (STEP B) |
|---|---|---|
| “What is the maximum cashback I can earn?” | Hallucination — “1.5% of your purchase amount… $100,000… $1500…” 가짜 FAQ 자동 생성 | “2% of your purchases… capped at $1000 per year… paid out annually as a gift card” |
| “Does the MyElite program offer discounts?” | Hallucination — “5% cash back… https://www.myelegant.co.uk/… £1 spent…” | “does not directly offer discounts… 2% cashback… paid annually via a gift card” |
Base 모델은 자기 답끼리도 모순(1.5% vs 5%)이고 가상 URL과 통화를 만들어 냈다. Fine-tuned 모델은 학습 데이터의 사실(2%/$1000/gift card)을 일관되게 인용한다.
이 결과를 이전 글의 RAG 실습과 비교하면:
| RAG (04-02 실습) | Fine-tuning (본 글 실습) | |
|---|---|---|
| 차이 위치 | prompt — 같은 모델, 다른 입력 | 모델 자체 — 다른 가중치, 같은 입력 |
| 비유 | 오픈북 | 암기 |
| 핵심 작용 | 사실 토큰을 prompt에 깔아 놓음 | 사실 패턴을 가중치에 새김 |
| 한계 | 검색 정확도, docs 신뢰도 | 데이터 큐레이션, overfit, 재학습 |
비용/시간 요약
| 항목 | 값 |
|---|---|
| Colab T4 GPU | $0 |
| 데이터셋 합성 (GPT-3.5) | $0.0043 |
| 모델 다운로드 | ~16분 |
| 학습 시간 | 17:29 |
| 총 비용 | ~$0.004 |
RAG vs Fine-tuning 선택 가이드
두 기법은 경쟁 관계가 아니라 상호 보완적이다. 프로젝트의 요구사항에 따라 선택하거나 조합한다.
KPI 매트릭스
| KPI | RAG 유리 | Fine-tuning 유리 |
|---|---|---|
| Accuracy (도메인) | medium — 검색 docs 품질 의존 | high — jargon이 가중치에 내재화 |
| Latency | 검색 + LLM = 2단계 | fast — 단일 LLM, 짧은 prompt |
| Cost per inference | prompt 길어짐 → 비용 ↑ | low — 짧은 prompt |
| 데이터 최신성 | easy — vector DB만 갱신 | hard — re-fine-tune 필요 |
| Setup 비용 | medium — vector DB 인프라 | high — GPU + 데이터 큐레이션 |
| Proprietary data 노출 | 매 query마다 docs 전송 | 가중치에 내재화 → 노출 ↓ |
시나리오별 권장
| 시나리오 | 권장 | 이유 |
|---|---|---|
| Medical/Legal chatbot | Fine-tuning | 도메인 jargon, 사실 정확도, 노출 최소화 |
| E-commerce 실시간 Q&A | RAG | 데이터 신선도, 재학습 비용 회피 |
| 내부 FAQ 챗봇 | Fine-tuning | 응답 consistency, 짧은 prompt |
| 뉴스 요약 | RAG | knowledge cut-off 이후 데이터 |
| 하이브리드 | Fine-tune + RAG 조합 | 도메인 base는 fine-tune, 변동 데이터는 RAG |
정리
4장에서는 LLM을 도메인에 맞추는 세 가지 방법을 다뤘다.
04-01에서는 LangChain Agent의 debug 출력을 통해 “agent가 하는 일은 결국 system prompt를 자동 구성하는 것”임을 확인했다. 프롬프트 엔지니어링의 자동화 도구인 셈이다.
04-02에서는 RAG를 적용해 같은 LLM이라도 외부 문서를 prompt에 주입하면 hallucination 없이 정확한 응답을 생성할 수 있음을 확인했다. 모델은 그대로 두고, 입력을 풍부하게 만드는 접근이다.
본 글에서는 fine-tuning을 통해 모델 가중치 자체에 도메인 지식을 내재화하는 과정을 실습했다. base 모델이 지어낸 가상의 숫자들이, QLoRA fine-tuning 후에는 “$99 subscription”, “2% cashback capped at $1000”, “gift card”처럼 학습 데이터의 사실을 정확히 인용하는 응답으로 바뀌었다. 30행짜리 합성 데이터와 $0.004의 비용으로도 이 변화가 가능했다는 점이 QLoRA의 실용성을 보여준다.
결국 세 가지 기법은 “LLM이 도메인을 모른다”는 같은 문제를 서로 다른 지점에서 해결한다. 프롬프트 엔지니어링은 질문을 잘 구성하고, RAG는 답의 재료를 외부에서 가져오며, fine-tuning은 모델 자체를 도메인 전문가로 만든다. 어느 하나가 정답이 아니라, 위 KPI 매트릭스에서 확인했듯 상황에 맞게 선택하거나 조합하는 것이 핵심이다.
참고 링크
- Packt — Kubernetes for Generative AI Solutions (GitHub)
- HuggingFace PEFT Documentation
- QLoRA Paper — Dettmers et al. (2023)
- LoRA Paper — Hu et al. (2021)
- BitsAndBytes Documentation
- Meta Llama 3 — HuggingFace
- Weights & Biases Documentation

댓글남기기