
[Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 0. Overview
서종호(가시다)님의 On-Premise K8s Hands-on Study 3주차 학습 내용을 기반으로 합니다.
TL;DR
이번 글의 목표는 kubeadm의 개념과 설계 철학 이해다.
- kubeadm: 머신을 쿠버네티스 노드로 만들어주는 노드 부트스트래퍼
- 설계 철학: 부트스트래핑만 담당하고, CRI·CNI·CSI에 구애받지 않는 infrastructure agnostic 도구
- 워크플로우:
kubeadm init→ CNI 설치 →kubeadm join세 단계로 클러스터 구성 - 신뢰 모델: Bootstrap Token + JWS 서명으로 init과 join 사이의 안전한 연결 보장
- 활용: minikube, kind, kubespray, Cluster API, kubeone 등이 kubeadm을 빌딩 블록으로 사용
들어가며
Kubernetes The Hard Way는 내 손으로 직접 쿠버네티스 클러스터를 구성하는 방법을 안내했다. 인증서 생성, etcd 설치, 컨트롤 플레인 구성, 워커 노드 조인까지 모든 과정을 수동으로 진행했다. 클러스터의 각 구성 요소를 이해하는 데는 좋지만, 실제 운영 환경에서 매번 이렇게 할 수는 없다.
이번 글부터는 kubeadm을 사용해 클러스터를 구성해 본다. kubeadm은 쿠버네티스 클러스터를 구성하기 위해 필요한 작업들을 자동화해주는 도구이다. Kubernetes The Hard Way에서 수동으로 수행한 작업들을 자동으로 수행한다고 생각하면 된다.
kubeadm이란
공식 문서 살펴보기
kubeadm 공식 문서를 보면, kubeadm을 다음과 같이 소개한다.
Kubeadm is a tool built to provide
kubeadm initandkubeadm joinas best-practice “fast paths” for creating Kubernetes clusters.
쿠버네티스 클러스터 생성을 위한 best-practice fast path를 제공하는 도구라고 한다. kubeadm init과 kubeadm join이라는 두 명령어로 클러스터를 빠르게 구성할 수 있다는 의미다.
한마디로 kubeadm은 노드 부트스트래퍼(node bootstrapper)다. 이미 준비된 머신(VM이든, 물리 서버든)을 쿠버네티스 노드로 만들어주는 역할을 한다. 머신 자체를 만들어주는 것이 아니라, 머신을 쿠버네티스 노드로 만들어 주는 것이다. Kubernetes The Hard Way에서 VM 생성, 네트워크 설정 등 머신 프로비저닝에 해당하는 작업은 kubeadm의 범위가 아니다.
kubeadm은 Kubernetes SIG(Special Interest Group) 중 Cluster Lifecycle 그룹에서 관리하는 공식 프로젝트다. 즉, 쿠버네티스에서 공식적으로 제공하는 클러스터 부트스트래핑 도구다.
kubeadm이 좋은 점
그렇다면 kubeadm은 어떤 경우에 유용한가? Kubeadm Deep Dive 발표에 따르면, 크게 세 가지로 정리할 수 있다.
- 쿠버네티스를 처음 시도해보는 간단한 방법: 처음 쿠버네티스를 접하는 사람이 빠르게 클러스터를 구성하고 사용해볼 수 있다.
- 기존 사용자가 클러스터 구성을 자동화하고 애플리케이션을 테스트하는 방법: 이미 쿠버네티스에 익숙한 사용자가 반복적인 클러스터 구성 작업을 자동화할 수 있다.
- 더 넓은 범위의 도구에서 사용되는 빌딩 블록: kubeadm 자체로 끝이 아니라, 다른 생태계 도구들이 kubeadm을 기반으로 더 높은 수준의 기능을 제공한다.
특히 세 번째가 중요하다. kubespray, Cluster API, kubeone 같은 도구들이 내부적으로 kubeadm을 사용한다. kubeadm은 이들의 기초(foundation) 역할을 한다. 이 부분은 kubeadm 활용 섹션에서 다시 자세히 살펴본다.
설계 철학
kubeadm의 설계 철학은 명확하다. 공식 문서에서 이렇게 설명한다.
kubeadm performs the actions necessary to get a minimum viable cluster up and running.
최소한의 실행 가능한 클러스터(minimum viable cluster)를 구성하는 데 필요한 작업만 수행한다. 설계 상, 부트스트래핑만 담당한다. 이를 뒷받침하는 두 가지 원칙이 있다.
- Be simple: kubeadm은 클러스터 부트스트래핑이라는 한 가지 일에만 집중한다. 머신 프로비저닝, CNI 설치, 애드온 관리 등을 담당하지 않는다.
- Be Extensible: 단순하되, 확장 가능해야 한다. kubeadm이 하지 않는 영역은 다른 도구들이 채울 수 있도록 설계되어 있다. kubeadm 위에 kubespray나 Cluster API 같은 도구가 올라갈 수 있는 이유다.
kubeadm이 하지 않는 것
kubeadm이 하지 않는 것들이 있다.
- 머신 프로비저닝: VM이나 물리 서버를 생성하지 않음
- 컨테이너 런타임 설치: containerd, CRI-O 등 CRI 호환 런타임을 설치하지 않음
- kubelet 설치: kubelet 바이너리 설치 및 systemd 서비스 등록을 하지 않음
- CNI 플러그인 설치: Pod 네트워크를 위한 CNI 플러그인(Calico, Flannel 등)을 설치하지 않음
- 애드온 설치: Kubernetes Dashboard, 모니터링 솔루션, 클라우드 특화 애드온 등을 설치하지 않음
즉, kubeadm을 실행하기 전에 containerd(또는 다른 CRI 런타임)와 kubelet이 이미 설치되어 있어야 한다.
이렇게 하지 않는 것들이 많다 보니 kubeadm은 인프라에 구애받지 않는(infrastructure agnostic) 도구다. CRI(컨테이너 런타임), CNI(네트워크 플러그인), CSI(스토리지 드라이버)를 직접 설치하지 않으므로, 어떤 조합을 사용하든 상관없다. containerd든 CRI-O든, Calico든 Flannel이든, kubeadm이 관여하는 영역이 아니다.
Instead, we expect higher-level and more tailored tooling to be built on top of kubeadm.
공식 문서의 설명을 보면 kubeadm 위에 더 높은 수준의, 더 맞춤화된 도구들이 만들어지길 기대한다고 한다. kubeadm은 기초(foundation) 역할만 하고, 그 위에 다양한 도구들이 쌓이는 구조다.
kubeadm이 하는 것
kubeadm이 하는 것들은 다음과 같다.
- 인증서 생성: CA 및 각 컴포넌트용 TLS 인증서 자동 생성
- kubeconfig 파일 생성: admin, kubelet, controller-manager, scheduler용 kubeconfig 자동 생성
- etcd 구성: Static Pod로 etcd 자동 배포
- 컨트롤 플레인 구성: kube-apiserver, kube-controller-manager, kube-scheduler를 Static Pod로 배포
- kubelet 설정: kubelet 설정 파일 생성 및 시작
- CoreDNS, kube-proxy 설치: 기본 애드온으로 자동 설치
kubeadm이 배포하는 것
아래 그림은 kubeadm이 실제로 배포하는 컴포넌트와 사용자가 사전에 준비해야 하는 컴포넌트를 노드 유형별로 나타낸 것이다.
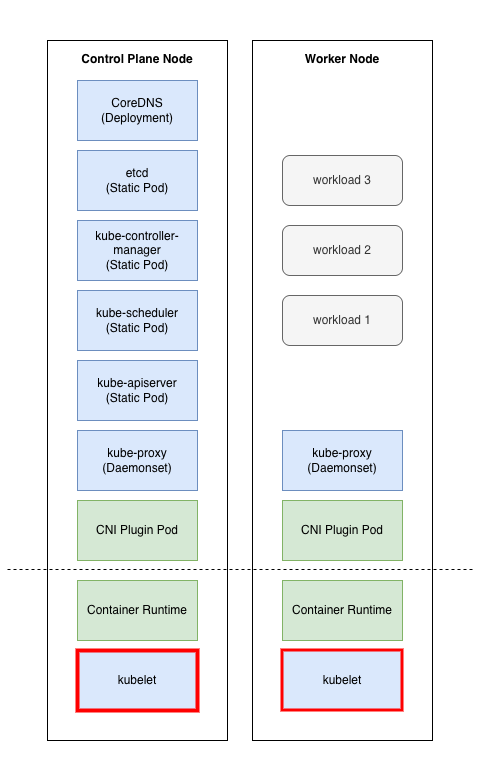
컨트롤 플레인 노드에서 kubeadm이 배포하는 컴포넌트는 다음과 같다.
| 컴포넌트 | 배포 방식 | 비고 |
|---|---|---|
| kube-apiserver | Static Pod | /etc/kubernetes/manifests/kube-apiserver.yaml |
| kube-controller-manager | Static Pod | /etc/kubernetes/manifests/kube-controller-manager.yaml |
| kube-scheduler | Static Pod | /etc/kubernetes/manifests/kube-scheduler.yaml |
| etcd | Static Pod | /etc/kubernetes/manifests/etcd.yaml (local etcd 구성 시) |
| CoreDNS | Deployment | kubeadm init의 addon 단계에서 배포 |
| kube-proxy | DaemonSet | 모든 노드에서 실행 |
워커 노드에서는 kube-proxy(DaemonSet)만 kubeadm이 관리한다. CoreDNS Pod도 스케줄링될 수 있지만, 이는 쿠버네티스 스케줄러가 결정하는 것이지 kubeadm이 배치하는 것은 아니다.
반면 사용자가 사전에 준비해야 하는 것들은 다음과 같다.
| 컴포넌트 | 설명 |
|---|---|
| Container Runtime | containerd 등 CRI 호환 런타임을 직접 설치 |
| kubelet | 바이너리 설치 및 systemd 서비스 등록 (kubeadm은 설정 구성만 담당) |
| CNI 플러그인 | Calico, Flannel, Cilium 등을 kubeadm init 이후 별도 설치 |
참고: 원본 발표 자료에서는 CoreDNS와 etcd가 사용자 설치 영역으로 표시되어 있다. 하지만 CoreDNS는
kubeadm init의 addon 단계에서 Deployment로 배포되고, etcd는 local 구성 시 Static Pod로 배포되므로 kubeadm 배포 영역으로 수정했다. 다만 external etcd를 사용하는 경우에는 사용자가 직접 구성해야 한다.
Kubernetes The Hard Way에서 OpenSSL로 인증서를 생성하고, systemd 서비스 파일을 작성하고, etcd와 컨트롤 플레인 컴포넌트를 직접 설치했던 과정들을 kubeadm이 자동화해준다.
kubeadm 워크플로우
클러스터 구성
kubeadm으로 클러스터를 구성하는 전체 흐름은 세 단계로 이루어진다.
| 단계 | 명령어 | 설명 |
|---|---|---|
| 1 | kubeadm init |
컨트롤 플레인 부트스트래핑 |
| 2 | kubectl apply ... |
CNI 플러그인 설치 (Pod 네트워크 활성화) |
| 3 | kubeadm join |
워커 노드 조인 |
1단계: 클러스터 초기화
sudo kubeadm init
첫 번째 컨트롤 플레인 노드에서 kubeadm init을 실행한다. 인증서 생성, etcd 구성, 컨트롤 플레인 컴포넌트 배포 등 클러스터 초기화에 필요한 모든 작업이 자동으로 수행된다. 이 단계가 완료되면 컨트롤 플레인은 동작하지만, 아직 Pod 네트워크가 없는 상태다.
2단계: CNI 플러그인 설치
kubectl apply -f <CNI 플러그인 매니페스트>
kubeadm init 직후, CNI 플러그인을 설치해야 한다. kubeadm은 infrastructure agnostic하므로 CNI 플러그인을 직접 설치하지 않는다. Calico든, Flannel이든, Cilium이든 원하는 CNI를 선택해서 설치하면 된다.
이 단계가 중요한 이유는 CoreDNS 때문이다. kubeadm init이 CoreDNS를 배포하긴 하지만, CNI가 없으면 Pod 간 네트워크 통신이 불가능하므로 CoreDNS Pod가 Pending 상태에 머문다. CNI를 설치해야 CoreDNS가 정상적으로 동작하고, 클러스터 내부 DNS 해석이 가능해진다.
참고: Kubernetes The Hard Way에서는 CoreDNS를 별도로 배포하지 않았다.
/etc/hosts파일로 로컬 DNS를 설정하고, Pod 네트워크 라우팅도 수동으로 구성했다. kubeadm에서는 CoreDNS가 기본 애드온으로 포함되어 있어 CNI만 설치하면 클러스터 내부 DNS가 자동으로 동작한다.
3단계: 워커 노드 조인
sudo kubeadm join <control-plane-host>:<control-plane-port> \
--token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
CNI 설치가 완료되면 워커 노드를 클러스터에 조인시킨다. kubeadm init 완료 시 출력되는 kubeadm join 명령어를 워커 노드에서 그대로 실행하면 된다. 토큰과 CA 인증서 해시를 통해 안전하게 클러스터에 합류한다.
클러스터 업그레이드
클러스터가 구성된 이후, kubeadm upgrade를 사용해 쿠버네티스 버전을 업그레이드할 수 있다. 업그레이드도 세 단계로 진행된다.
| 단계 | 명령어 | 설명 |
|---|---|---|
| 1 | kubeadm upgrade plan |
업그레이드 가능한 버전 확인 |
| 2 | kubeadm upgrade apply v1.xx.x |
첫 번째 컨트롤 플레인 노드 업그레이드 |
| 3 | kubeadm upgrade node |
나머지 노드 업그레이드 |
1단계: 버전 확인
업그레이드 가능한 버전을 확인한다. 현재 클러스터 버전과 업그레이드 가능한 대상 버전, 필요한 사전 조건 등을 보여준다.
sudo kubeadm upgrade plan
2단계: 컨트롤 플레인 업그레이드
첫 번째 컨트롤 플레인 노드를 업그레이드한다. 지정한 버전으로 컨트롤 플레인 컴포넌트(kube-apiserver, kube-controller-manager, kube-scheduler, etcd)의 Static Pod 매니페스트를 갱신한다.
sudo kubeadm upgrade apply v1.xx.x
3단계: 기타 노드 업그레이드
나머지 컨트롤 플레인 노드와 워커 노드를 업그레이드한다. 각 노드에서 실행하면 해당 노드의 kubelet 설정과 컨트롤 플레인 컴포넌트(추가 컨트롤 플레인인 경우)를 업그레이드한다.
sudo kubeadm upgrade node
참고:
kubeadm upgrade는 컨트롤 플레인 컴포넌트만 업그레이드한다. kubelet과 kubectl은 별도로 업그레이드해야 한다. 이 역시 kubeadm의 설계 철학(부트스트래핑만 담당)과 일관된다.
kubeadm Bootstrap 신뢰 모델
kubeadm init이 완료되면 다음과 같은 kubeadm join 명령어가 출력된다.
kubeadm join 192.168.10.100:6443 --token 123456.1234567890123456 \
--discovery-token-ca-cert-hash sha256:bd763182...
--token과 --discovery-token-ca-cert-hash는 무엇이고, 왜 필요할까?
문제: 신뢰 부트스트래핑
Worker 노드가 클러스터에 join하려면 Control Plane과 TLS 통신을 해야 하고, 그러려면 CA 인증서가 필요하다. 그런데 CA 인증서를 받으려면 Control Plane에 접속해야 한다. 인증서 없이 최소한의 신뢰를 확보하는 방법이 필요하다. 전형적인 닭과 달걀 문제다.
kubeadm은 이 문제를 두 겹의 검증으로 해결한다.
| 검증 계층 | 메커니즘 | 방어 대상 |
|---|---|---|
| 1차 | JWS 서명 (Bootstrap Token) | 데이터 변조 |
| 2차 | CA 공개키 해시 | Token Secret 유출 시 CA 위조 |
이 글에서는 각 계층이 어떻게 동작하고, 어떤 위협을 막는지 순서대로 살펴본다.
Bootstrap Token
Bootstrap Token은 kubeadm의 TLS Bootstrap 전용 형식으로, Token ID와 Token Secret 두 부분으로 구성된다. Kubernetes가 사용하는 다른 토큰(ServiceAccount의 JWT 등)과는 별개의 형식이다.
123456.1234567890123456
↑ ID ([a-z0-9]{6}) ↑ Secret ([a-z0-9]{16})
이 토큰은 out-of-band(대역 외)로 전달된다. kubeadm init 완료 시 화면에 출력되고, 관리자가 네트워크 도청과 무관한 경로(예: SSH 접속 후 직접 입력)로 Worker 노드에 전달한다. 토큰이 API Server의 HTTP 응답에 포함되는 일은 없다.
1차 검증: JWS 서명
init — 서명 생성
kubeadm init의 bootstrap-token 단계에서 다음을 수행한다.
kube-public네임스페이스에cluster-infoConfigMap을 생성한다.kubeconfig데이터(API Server 주소 + CA 인증서)를 Token Secret으로 HMAC-SHA256 서명한다.- 서명 결과를
jws-kubeconfig-{Token ID}키로 ConfigMap에 저장한다. - RBAC를 설정하여 User
system:anonymous에cluster-infoGET을 허용한다.
참고:
system:anonymousvssystem:unauthenticatedAPI Server에 인증 정보 없이 요청이 들어오면(
--anonymous-auth=true기본값), authenticator가 자동으로 두 가지를 동시에 부여한다(공식 문서):
구분 system:anonymoussystem:unauthenticated종류 User (사용자) Group (그룹) 의미 인증되지 않은 요청에 부여되는 가상 사용자 이름 인증되지 않은 요청에 부여되는 가상 그룹 즉, 인증되지 않은 요청 하나는 User
system:anonymous이면서 동시에 Groupsystem:unauthenticated의 멤버다. 어느 쪽에 RoleBinding을 걸어도 결과는 동일하지만, kubeadm은 User에 직접 바인딩하는 더 보수적인 방식을 사용한다. 실제 RoleBinding 확인은 init 실행 — Role/RoleBinding 확인을 참고한다.한편, kubeadm implementation details 공식 문서에서는 “unauthenticated users (i.e. users in RBAC group
system:unauthenticated)”라고 Group으로 설명하고 있지만, 실제 kubeadm 코드가 생성하는 RoleBinding은kind: User, name: system:anonymous다. 기능적으로는 동일하나, User에 직접 바인딩하는 쪽이 범위가 더 좁아 약간 더 보수적인 접근이다.
ConfigMap 키에는 Token ID(123456)만 노출된다. Secret은 절대 노출되지 않는다.
| ConfigMap 키 | 내용 |
|---|---|
kubeconfig |
API Server 주소 + CA 인증서 (클러스터 접속을 위한 최소 정보) |
jws-kubeconfig-123456 |
HMAC-SHA256(kubeconfig 데이터, Token Secret) |
서명 = HMAC-SHA256(kubeconfig 데이터, "1234567890123456")
↑ Token Secret
실제로 생성된
cluster-infoConfigMap의 내용은 init 실행에서 확인할 수 있다.
join — 서명 검증
kubeadm join --token 123456.1234567890123456을 실행하면 Worker 노드는 다음 순서로 검증한다.
- 인증 없이
cluster-infoConfigMap을 조회하여kubeconfig과jws-kubeconfig-123456을 가져온다. - 자신이 가진 Token Secret(
1234567890123456)으로kubeconfig데이터의 HMAC을 재계산한다. - 재계산 결과와
jws-kubeconfig-123456값을 비교한다.- 일치 →
kubeconfig안의 CA 인증서를 신뢰 → TLS Bootstrap 진행 - 불일치 → 데이터가 변조됨 → 거부
- 일치 →
kubeadm join의 상세 동작(Discovery, TLS Bootstrap, CSR 발급 과정)은 join 동작 원리에서 다룬다.
JWS가 막는 것: 중간자 공격
cluster-info는 인증 없이 누구나 읽을 수 있으므로, 중간자(MITM)가 응답을 가로채 kubeconfig 안의 CA 인증서를 자신의 가짜 CA로 바꿔치기할 수 있다.
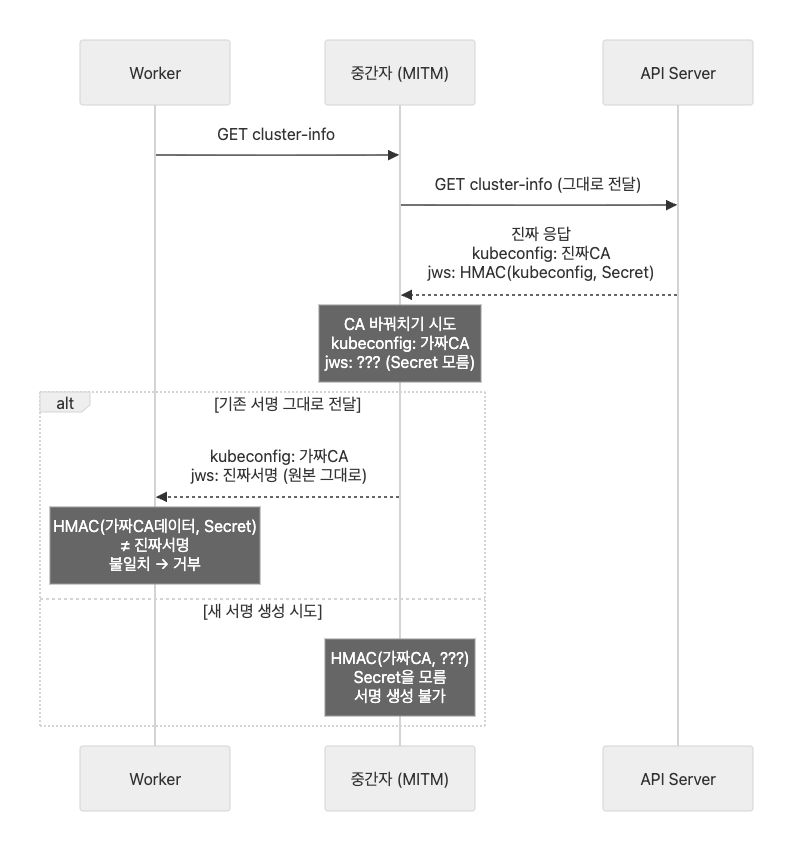
그러나 CA를 바꾸면 kubeconfig 데이터가 달라지고, 기존 JWS 서명은 무효가 된다. 공격자가 유효한 서명을 새로 만들려면 Token Secret이 필요한데, Secret은 out-of-band로만 전달되므로 네트워크 도청으로는 얻을 수 없다.
핵심은 네트워크에 노출되는 정보와 노출되지 않는 정보의 분리다.
| 구분 | 내용 |
|---|---|
| 네트워크에 노출 | kubeconfig (CA 인증서 포함) + JWS 서명값 + Token ID |
| 네트워크에 미노출 | Token Secret → out-of-band 전달 |
공격자의 선택지는 두 가지뿐이고, 둘 다 실패한다.
- 기존 서명을 그대로 두면 → Worker가 HMAC 재계산 시 불일치 → 거부
- 새 서명을 만들려면 → Secret이 필요한데 모름 → 불가능
Token Secret은 Control Plane과 Worker만 아는 공유 비밀이고, 이것으로 kubeconfig 데이터의 무결성을 HMAC 서명으로 보증하는 구조다.
2차 검증: CA 공개키 해시
JWS의 전제는 Token Secret을 중간자가 모른다는 것이다. 이 전제가 무너지면(예: 실습 환경에서 1234567890123456처럼 고정한 경우) 공격자가 가짜 CA에 대해 유효한 JWS 서명을 만들 수 있다.
--discovery-token-ca-cert-hash sha256:<hash>는 Token Secret과 독립적으로 CA 인증서의 공개키를 직접 확인하는 2차 방어선이다.
- 해시 대상: CA 인증서의 SPKI(Subject Public Key Info) 객체를 SHA-256으로 해시한 값 (RFC 7469)
- 검증 방식: Worker가
cluster-info에서 가져온 CA 인증서의 공개키 해시를 계산하고, join 명령어에 지정된 해시와 비교 - 불일치 시: CA 인증서가 변조되었거나 다른 클러스터의 인증서 → 거부
이 해시값 역시 kubeadm init 출력에서 out-of-band로 전달된다. Token Secret이 유출되어 JWS를 위조하더라도, 공격자의 가짜 CA는 원래 CA와 공개키가 다르므로 해시가 일치하지 않는다.
# CA 해시는 다음 명령으로 직접 계산할 수 있다
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
정리
| 상황 | JWS 검증 (--token) |
CA 해시 검증 (--discovery-token-ca-cert-hash) |
결과 |
|---|---|---|---|
| 정상 | 통과 | 통과 | join 성공 |
| MITM + Secret 안전 | 실패 (서명 위조 불가) | - | 거부 |
| MITM + Secret 유출 | 통과 (서명 위조 가능) | 실패 (가짜 CA 공개키 해시 불일치) | 거부 |
두 메커니즘은 서로 다른 전제 조건의 실패를 커버한다. JWS는 Token Secret의 비밀성에 의존하고, CA 해시는 그 의존성마저 제거한다. 결과적으로, 두 out-of-band 값(Token과 CA 해시) 중 하나만 안전해도 중간자 공격을 방어할 수 있는 구조다.
참고: 실습 환경 주의 사항
이 시리즈의 실습에서는 재현성을 위해 토큰을 고정하고 TTL을 무기한으로 설정한다. 토큰을 고정하면 위에서 설명한 JWS 보안 모델의 전제(“Secret을 중간자가 모른다”)가 무너지므로, 프로덕션에서는 절대 이렇게 하면 안 된다. 구체적인 위험성과 프로덕션 권장 사항은 init 실행 - token 고정의 위험성에서 다룬다.
주요 명령어
kubeadm이 제공하는 주요 명령어들을 살펴보자. 명령어들은 크게 세 가지 계층으로 분류할 수 있다.

명령어 관계도
명령어들의 관계를 정리하면 다음과 같다.
[ Cluster Lifecycle ]
│
├── init ────┐
│ │
├── join ────┼──── [ Security ]
│ │ ├── certs
├── upgrade ────┘ ├── kubeconfig
│ └── token
└── reset
[ Utility ]
├── config
├── version
└── alpha
kubeadm init으로 컨트롤 플레인을 구성하면, 내부적으로 인증서(certs)와 kubeconfig를 생성하고, 워커 노드 조인을 위한 토큰(token)을 발급한다.kubeadm join으로 워커 노드를 클러스터에 조인시킨다. 이때 토큰을 사용한다.- 클러스터 버전을 올릴 때는
kubeadm upgrade를 사용한다. - 노드를 클러스터에서 제거하거나 초기화할 때는
kubeadm reset을 사용한다.
생명주기 명령어
클러스터의 생성부터 삭제까지 전체 생명주기를 관리하는 핵심 명령어들이다.
init (시작) ──→ join (확장) ──→ upgrade (갱신)
│
↓
reset (초기화)
| 명령어 | 설명 |
|---|---|
kubeadm init |
컨트롤 플레인 노드 부트스트래핑 |
kubeadm join |
워커 노드 또는 추가 컨트롤 플레인 노드를 클러스터에 조인 |
kubeadm upgrade |
쿠버네티스 클러스터를 새 버전으로 업그레이드 |
kubeadm reset |
kubeadm init 또는 kubeadm join으로 만들어진 변경 사항을 되돌림 |
보안 기반 명령어
생명주기 명령어들이 내부적으로 사용하는 인증/인가 관련 명령어들이다. 직접 사용할 일은 적지만, 인증서 갱신이나 토큰 관리 시 필요하다.
| 명령어 | 설명 |
|---|---|
kubeadm certs |
쿠버네티스 인증서 관리 (갱신, 확인 등) |
kubeadm kubeconfig |
kubeconfig 파일 관리 |
kubeadm token |
kubeadm join 시 사용할 토큰 관리 |
유틸리티 명령어
| 명령어 | 설명 |
|---|---|
kubeadm config |
클러스터 설정 관리 (기본 설정 출력, 필요한 이미지 목록 확인 등) |
kubeadm version |
kubeadm 버전 확인 |
kubeadm alpha |
다음 버전에 포함될 실험적 기능들 |
kubeadm 활용
Composable Solution
앞서 kubeadm의 설계 철학으로 Be simple과 Be Extensible을 언급했다. kubeadm은 올인원 솔루션이 아니라, 조합 가능한 솔루션(composable solution)의 한 조각으로 설계되었다.
kubeadm을 관리하는 SIG Cluster Lifecycle에는 kubeadm 외에도 kubespray, Cluster API, kind, minikube 등 20개 이상의 프로젝트가 있다. 각 프로젝트는 클러스터 라이프사이클의 특정 영역만 담당하고, 이를 레고 블록처럼 조합해서 사용하는 구조다. kubeadm이 infrastructure agnostic하게 설계된 이유가 여기 있다.
kubeadm을 사용하는 도구들
composable solution 구조 덕분에 다양한 도구들이 kubeadm을 빌딩 블록으로 사용한다.
| 도구 | 설명 | kubeadm 활용 방식 |
|---|---|---|
| minikube | 로컬 개발/학습용 단일 노드 클러스터 | VM 또는 컨테이너 내부에서 kubeadm으로 클러스터 부트스트래핑 |
| kind | Docker 컨테이너를 노드로 사용하는 로컬 클러스터 | 각 컨테이너 안에서 kubeadm으로 노드 구성 |
| kubespray | Ansible 기반 프로덕션급 클러스터 배포 | Ansible로 머신 프로비저닝 후 kubeadm으로 클러스터 부트스트래핑 |
| Cluster API | 쿠버네티스 리소스로 클러스터를 선언적 관리 | kubeadm bootstrap provider로 노드 부트스트래핑 |
| kubeone | 멀티 클라우드 쿠버네티스 클러스터 관리 | Terraform으로 인프라 프로비저닝 후 kubeadm으로 클러스터 구성 |
이 도구들은 공통적으로 kubeadm이 하지 않는 영역(머신 프로비저닝, CNI 설치, 애드온 관리 등)을 담당하면서, 클러스터 부트스트래핑은 kubeadm에 위임한다. 계층 구조로 보면 다음과 같다.
┌────────────────────────────────────────────────────┐
│ kubespray / Cluster API / kubeone │ ← 머신 프로비저닝, CNI, 애드온
├────────────────────────────────────────────────────┤
│ kubeadm │ ← 클러스터 부트스트래핑
├────────────────────────────────────────────────────┤
│ kubelet + CRI + machine(OS) │ ← 사전 준비
└────────────────────────────────────────────────────┘
vs. Kubernetes The Hard Way
kubeadm은 Kubernetes The Hard Way에서 수동으로 수행하는 단계들을 자동화한다. 각 단계가 수동으로 클러스터를 구성하는 단계에 어떻게 매칭되는지 보여준다.
| kubeadm 단계 | Kubernetes The Hard Way |
|---|---|
| (사전 준비) | 0. Overview |
| (머신 프로비저닝) | 1. Prerequisites |
| (바이너리 준비) | 2. Set Up The Jumpbox |
| (컴퓨트 리소스) | 3. Provisioning Compute Resources |
| kubeadm init | |
| └ preflight | 해당 없음 (사전 체크 없이 바로 진행) |
| └ certs | 4.1. TLS/mTLS/PKI 개념 4.2. ca.conf 구조 분석 4.3. CA 및 TLS 인증서 생성 |
| └ kubeconfig | 5.1. kubeconfig 개념 5.2. kubeconfig 파일 생성 |
| └ etcd | 7. Bootstrapping etcd |
| └ control-plane | 8.1. Control Plane 설정 분석 8.2. Control Plane 배포 |
| └ kubelet-start | 해당 없음 (Control Plane에 kubelet 미설치) |
| └ wait-control-plane | 해당 없음 (수동으로 확인) |
| └ upload-config | 해당 없음 |
| └ upload-certs | 해당 없음 (인증서를 SCP로 수동 배포) |
| └ mark-control-plane | 해당 없음 |
| └ bootstrap-token | 해당 없음 (인증서를 SCP로 수동 배포) |
| └ kubelet-finalize | 해당 없음 |
| └ addon (coredns, kube-proxy) | 해당 없음 (CoreDNS 미설치, /etc/hosts로 DNS 구성) |
| kubeadm join | |
| └ Worker Node 구성 | 9.1. CNI 및 Worker Node 설정 9.2. Worker Node 프로비저닝 |
| (추가 설정) | |
| └ kubectl 원격 접근 | 10. Configuring kubectl |
| └ Pod Network Routes | 11. Pod Network Routes |
| (검증) | 12. Smoke Test |
주요 차이점
| 구분 | Kubernetes The Hard Way | kubeadm |
|---|---|---|
| 인증서 생성 | OpenSSL로 수동 생성 | 자동 생성 (kubeadm certs) |
| etcd | systemd 서비스로 직접 구성 | Static Pod로 자동 구성 |
| Control Plane | systemd 서비스로 직접 구성 | Static Pod로 자동 구성 |
| kubeconfig | kubectl로 수동 생성 | 자동 생성 (kubeadm kubeconfig) |
| CNI | bridge 플러그인 수동 설정 | 별도 설치 필요 (Calico, Flannel 등) |
| 클러스터 DNS | CoreDNS 미설치, /etc/hosts로 구성 |
CoreDNS 기본 애드온으로 배포 |
| etcd 통신 | HTTP (평문) | HTTPS (TLS 암호화) |
| 토큰 기반 join | 수동 인증서 배포 | bootstrap token 사용 |
| join 시 CA 전달 | SCP로 수동 복사 | cluster-info ConfigMap + JWS 검증 |
| join 시 kubelet 인증서 | 관리자 직접 생성 후 SCP 배포 | TLS Bootstrap 자동 발급 (CSR → 승인) |
| Control Plane kubelet | 미설치 (컴포넌트를 systemd로 직접 실행) | 필수 (Static Pod 관리) |
참고: Kubernetes The Hard Way에서는 학습 목적으로 etcd를 HTTP로 구성했지만, kubeadm은 보안을 위해 HTTPS를 기본으로 사용한다.
Control Plane 구성: systemd vs Static Pod
Kubernetes The Hard Way 실습에서는 컨트롤 플레인 컴포넌트들을 systemd 서비스로 직접 구성했다. kube-apiserver.service, kube-controller-manager.service, kube-scheduler.service 파일을 수동으로 작성하고, 각 서비스의 실행 옵션(인증서 경로, etcd 연결, CIDR 등)을 직접 지정했다. Control Plane 노드에는 kubelet이 필요 없었다(systemd가 직접 관리).
kubeadm은 이 모든 작업을 Static Pod 매니페스트 자동 생성으로 대체한다. kubelet이 /etc/kubernetes/manifests를 감시해 API Server 없이도 컨트롤 플레인을 부트스트랩하는 구조이므로, Control Plane에도 kubelet이 필수다.
Control Plane에 kubelet 기동
Kubernetes The Hard Way에서는 Control Plane 컴포넌트들을 systemd 서비스로 직접 실행했기 때문에 kubelet이 필요하지 않았다. 하지만 kubeadm은 앞서 본 것처럼 Control Plane 컴포넌트를 Static Pod로 배포하므로, 이를 관리할 kubelet이 Control Plane에도 반드시 필요하다. 이유는 크게 두 가지다. 컨트롤 플레인 컴포넌트를 Pod로 띄우는 것(kubeadm 구조상)과, Control Plane 노드도 클러스터의 노드이므로 kubelet이 담당하는 노드 역할(상태 보고, Pod 실행)이 필요하다는 것이다.
-
컨트롤 플레인 컴포넌트 실행: kubelet은
/etc/kubernetes/manifests디렉토리를 모니터링하며, 여기에 있는 매니페스트(kube-apiserver, kube-controller-manager, kube-scheduler, etcd)를 자동으로 Pod로 실행하고 관리한다. API Server가 없어도 이 Static Pod만으로 컨트롤 플레인을 부트스트랩할 수 있다. -
노드로서의 역할: Control Plane 노드도 클러스터에 등록된 노드이므로, 해당 노드의 상태(CPU, 메모리, 디스크 등)를 API Server에 보고해야 하고, 그 노드에 스케줄된 Pod를 실행해야 한다. 전자는 kubelet의 노드 상태 보고, 후자는 Pod 실행(컨트롤 플레인 Static Pod뿐 아니라 taint 제거 시 워크로드 Pod 포함)이다. 둘 다 kubelet이 담당한다.
노드 Join: 수동 배포 vs Bootstrap Token
Kubernetes The Hard Way에서는 닭과 달걀 문제가 존재하지 않았다. 관리자가 CA 인증서와 kubelet 인증서를 SCP로 직접 워커 노드에 복사했기 때문이다. 수동 배포라 “인증서 없는 노드가 어떻게 접속하나”라는 문제 자체가 발생하지 않는다.
kubeadm은 이 수동 배포를 자동화하기 위해 Bootstrap Token 메커니즘을 사용한다. 인증서를 직접 복사하는 대신, Token + JWS 서명으로 CA의 무결성을 검증하고, TLS Bootstrap으로 kubelet 인증서를 자동 발급받는 구조다.
| 단계 | Kubernetes The Hard Way | kubeadm |
|---|---|---|
| CA 인증서 전달 | SCP로 수동 복사 | cluster-info ConfigMap + JWS 검증 |
| kubelet 인증서 | 관리자가 직접 생성 후 SCP 배포 | TLS Bootstrap으로 자동 발급 (CSR → 자동 승인) |
| 신뢰 확보 방식 | 관리자의 수동 작업이 곧 신뢰 | Bootstrap Token (out-of-band 전달) |
참고: kubeadm 기반 도구도 마찬가지
앞서 살펴본 것처럼, kubespray, Cluster API, kubeone 같은 도구들은 내부적으로 kubeadm을 사용한다. 이 도구들도 노드 join 시 동일한 Bootstrap Token + JWS 메커니즘을 거친다. 다만, 수동으로 하던 토큰의 out-of-band 전달을 각 도구가 자동화하는 방식이 다르다.
| 도구 | 토큰 전달 방식 |
|---|---|
| kubespray | Ansible이 init 출력에서 토큰을 파싱 → join 태스크에 변수로 주입 |
| Cluster API | Bootstrap Provider가 토큰을 포함한 cloud-init 스크립트를 생성 → 머신 프로비저닝 시 주입 |
| kubeone | SSH로 Control Plane에서 토큰 생성 → Worker 노드에 전달 후 join 실행 |
SCP 수동 배포든, kubeadm이든, kubespray든, 근본적인 보안 모델은 동일하다. 인증서를 전달하는 경로가 네트워크 도청과 분리되어야 한다는 것이다. Kubernetes The Hard Way에서는 관리자의 SCP 접속이, kubeadm에서는 out-of-band 토큰 전달이, 자동화 도구에서는 각자의 보안 채널(Ansible SSH, cloud-init 등)이 이 역할을 한다.
결론
kubeadm은 Kubernetes The Hard Way에서 수동으로 했던 작업들을 자동화해주는 노드 부트스트래퍼다. 하지만 모든 것을 해주는 것은 아니다. 머신 프로비저닝, CRI·CNI 설치 등은 여전히 직접 해야 한다. 이것은 한계가 아니라 Be simple + Be Extensible이라는 의도된 설계다.
kubeadm은 올인원 솔루션이 아니라, SIG Cluster Lifecycle 산하의 여러 프로젝트들과 함께 조합해서 사용하는 composable solution의 한 조각이다. 부트스트래핑에만 집중하고 인프라에 구애받지 않기 때문에, 온프레미스든, 클라우드든, VM이든, 베어메탈이든 상관없이 사용할 수 있다. 그리고 kubespray, Cluster API, kubeone 같은 도구들이 kubeadm 위에 머신 프로비저닝과 애드온 관리를 얹어 완전한 클러스터 라이프사이클 관리를 완성한다.
1주차에 손으로 직접 클러스터를 구성해봤기 때문에, kubeadm이 어떤 작업들을 자동화해주는지 더 잘 이해할 수 있다. 다음 글에서는 실습 전체에서 어떤 파일이 어디에 생성되는지 조감도를 먼저 그려본 뒤, 실제로 클러스터를 구성해 본다.
이 글을 참조하는 글
- [EKS] EKS: EKS vs. Vanilla Kubernetes
- [EKS] EKS: Overview
- [Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 1.0. 실습 구성도
- [Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 1.1. kubeadm init
- [Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 1.4. kubeadm init 실행
- [Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 1.7. Static Pod 및 애드온 확인
- [Kubernetes] Cluster: Kubeadm을 이용해 클러스터 구성하기 - 2.1. kubeadm join
- [Kubernetes] Cluster: Kubespray를 이용해 클러스터 구성하기 - 0. Overview
- [Kubernetes] Cluster: RKE2를 이용해 클러스터 구성하기 - 0. Overview
- [Kubernetes] kubeconfig - 2. 다중 클러스터 접근 구성 실습


댓글남기기