
MLOps와 GitOps: 어느 영역까지 적용할 수 있는가
TL;DR
- MLOps 플랫폼에는 성격이 다른 두 종류의 워크로드가 섞여 있다: 장기 실행 인프라/서비스와 일회성 Job(학습, 배치 inference(추론) 등)이다.
- ArgoCD를 직접 띄워 RayJob을 Application으로 등록해 보면, 항상 OutOfSync다. 이건 우연이 아니라 선언형(declarative) 도구로 명령형(imperative) 작업을 수행하는 구조에서 오는 본질적인 미스매치다.
- 반면 ML 인프라(operator, 메타데이터 서비스, 서빙 컴포넌트)는 ArgoCD가 가장 잘 다루는 영역이다.
- “MLOps에 GitOps를 적용한다”는 표현은 이 구분 위에서만 의미를 가진다.
들어가며: 두 도구의 만남
MLOps 플랫폼을 구성하다 보면 어느 시점에 ArgoCD를 도입을 고민하게 된다. ArgoCD는 GitOps 도구로 잘 알려져 있고, “Git을 진실의 원천으로 클러스터 상태를 동기화한다”는 모델이 명확해서 채택의 문턱이 낮다.
문제는 MLOps에는 성격이 다른 두 종류의 워크로드가 섞여 있다는 점이다.
- 장기 실행되는 인프라/서비스: MLflow, Airflow, KubeRay operator, GPU operator, KServe 같은 컴포넌트들. “이 설정으로 항상 떠 있어야 한다”는 desired state가 명확하다.
- 일회성 Job: 학습 작업, 배치 inference 같은 run-to-completion 워크로드. 한 번 실행하고 끝나는(run-to-completion) 것이 본질이다.
이 둘을 같은 도구로 다룰 수 있을까? “MLOps 전반에 GitOps를 적용했다”고 말할 때 그 GitOps가 실제로 다루는 영역은 어디까지일까?
이 질문이 궁금해서, 두 영역에 직접 ArgoCD를 적용해 보면서 답을 정리해 보았다.
- Training Job에 적용할 수 있을까
- ML 인프라에 적용할 수 있을까
- 정리: 어디는 되고 어디는 안 되는가
1. Training Job에 GitOps를 적용할 수 있을까
ArgoCD가 학습 Job 형태의 워크로드까지 깔끔하게 다룰 수 있는지 궁금했다. 그래서 직접 띄워 봤다.
실험 셋업
KubeRay 공식 ray-job sample을 base로 minimal한 RayJob을 ArgoCD Application으로 등록했다.
- KubeRay operator가 설치된 클러스터
- RayJob CR을 담은 Helm chart 하나
- 이 chart를 source로 하는 ArgoCD Application 하나
RayJob을 고른 이유는 KubeRay가 제공하는 세 CRD 중 가장 “일회성 학습”의 성격이 명확한 리소스이기 때문이다.
| CRD | 역할 |
|---|---|
| RayCluster | Ray 클러스터의 라이프사이클(생성, 삭제, 오토스케일링, 장애 복구)을 관리한다. 사용자가 직접 클러스터를 띄우고, Ray Jobs API로 작업을 제출하는 방식이다. |
| RayJob | RayCluster를 자동으로 생성하고, 클러스터가 준비되면 작업을 제출하며, 작업 완료 후 클러스터를 정리(shutdownAfterJobFinishes)하는 것까지 한 번에 처리한다. |
| RayService | RayCluster와 Ray Serve 배포 그래프를 결합해 제로 다운타임 업그레이드와 고가용성을 지원하는 서빙 전용 CRD다. |
세 CRD 중 RayJob이 run-to-completion 모델에 가장 직접적으로 맞는다. 학습 작업마다 클러스터를 새로 만들고 정리하는 패턴이 갖는 “일회성(run-to-completion)”이라는 성격이 뒤에서 ArgoCD와 충돌하는 지점이 된다.
결과: 항상 OutOfSync
띄워 보니 RayJob Application은 항상 OutOfSync였다.
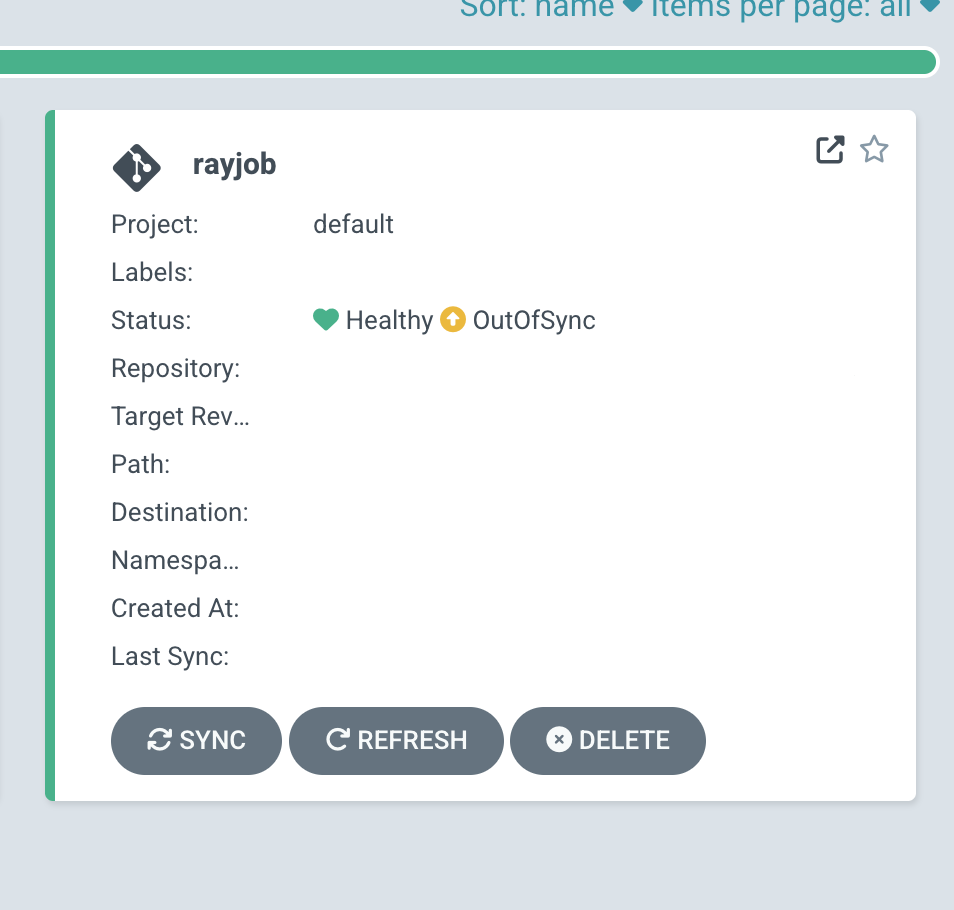
# RayJob Application 상태 확인: OutOfSync
$ kubectl get application rayjob -n argocd \
-o jsonpath='{.status.sync.status} {.status.health.status}'
OutOfSync Healthy
# RayJob 자체는 정상 실행 중
$ kubectl get rayjob \
-o custom-columns='NAME:.metadata.name,STATUS:.status.jobStatus,DEPLOYMENT:.status.jobDeploymentStatus'
NAME STATUS DEPLOYMENT
rayjob RUNNING Running
RayJob 자체는 정상적으로 실행되고 있는데, ArgoCD 입장에서는 desired state와 actual state가 어긋난다고 본다.
왜 OutOfSync인가
ArgoCD는 두 상태를 비교해서 sync 여부를 판단한다.
- Desired State: Git에 선언된 상태. Helm chart라면
helm template으로 렌더링한 결과이고, raw YAML이라면 매니페스트 그 자체다. - Actual State: 클러스터에 실제로 존재하는 리소스의 현재 상태.
- OutOfSync 판단: 1과 2가 같으면
Synced, 다르면OutOfSync.
일반적인 쿠버네티스 리소스는 선언한 spec이 그대로 유지되지만, RayJob은 다르다. 선언한 spec이 그대로 유지되지 않는다.
직접 원인은 KubeRay operator가 RayJob CR(Custom Resource)의 .spec에 사용자가 선언하지 않은 필드를 기본값으로 주입(CRD defaulting)하기 때문이다.
| 필드 | chart (desired) | 클러스터 (actual) | 변경 주체 |
|---|---|---|---|
spec.backoffLimit |
(없음) | 0 |
operator 기본값 주입 |
spec.submissionMode |
(없음) | K8sJobMode |
operator 기본값 주입 |
spec.ttlSecondsAfterFinished |
(없음) | 0 |
operator 기본값 주입 |
workerGroupSpecs[*].maxReplicas |
(없음) | 2147483647 |
operator 기본값 주입 |
workerGroupSpecs[*].minReplicas |
(없음) | 0 |
operator 기본값 주입 |
workerGroupSpecs[*].numOfHosts |
(없음) | 1 |
operator 기본값 주입 |
workerGroupSpecs[*].scaleStrategy |
(없음) | {} |
operator 기본값 주입 |
metadata.finalizers |
(없음) | [ray.io/rayjob-finalizer] |
operator 추가 |
.status (전체) |
(없음) | operator가 지속 업데이트 | operator |
.status는 ArgoCD의 비교 대상이 아니므로 직접적인 OutOfSync 원인은 아니다. operator가 동적으로 업데이트하는 필드라는 맥락에서 표에 포함했을 뿐이다. OutOfSync의 핵심 원인은 spec 레벨의 기본값 주입(backoffLimit, submissionMode, maxReplicas 등)이다.
부수적으로 KubeRay operator는 RayJob을 보고 RayCluster를 동적 생성하고, RayCluster는 다시 head/worker Pod와 service들을 만든다.
RayJob (chart가 생성)
├── RayCluster rayjob-xxxxx (KubeRay operator가 생성)
│ ├── head pod
│ ├── head-svc
│ └── worker pod × N
└── Job rayjob-yyyyy (submitter Job)
이 자식 리소스들은 ArgoCD 리소스 트리에 ownerReference(소유자 참조)를 통해 표시되긴 하지만, desired manifest에 없으므로 sync 계산에는 직접 관여하지 않는다. OutOfSync의 직접 원인은 어디까지나 RayJob CR spec 레벨의 drift다.
ArgoCD가 sync를 다시 수행해서 맞춰줄 수 있을까? 그것도 아니다. 되돌려 봤자 operator가 다시 같은 기본값을 주입할 뿐이다.
1차 해결: ignoreDifferences
OutOfSync 자체는 ArgoCD Application spec에 ignoreDifferences를 설정해 operator가 변경하는 필드를 비교 대상에서 제외하면 해소할 수 있다.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: rayjob
spec:
ignoreDifferences:
- group: ray.io
kind: RayJob
jsonPointers:
- /spec/backoffLimit
- /spec/submissionMode
- /spec/ttlSecondsAfterFinished
- group: ray.io
kind: RayJob
jqPathExpressions:
- .spec.rayClusterSpec.workerGroupSpecs[].maxReplicas
- .spec.rayClusterSpec.workerGroupSpecs[].minReplicas
- .spec.rayClusterSpec.workerGroupSpecs[].numOfHosts
- .spec.rayClusterSpec.workerGroupSpecs[].scaleStrategy
ArgoCD 공식 문서의 Diffing Customization 섹션도 “controllers that mutate resources”를 명시적으로 언급하며, HPA가 Deployment의 replicas를 변경하는 경우를 대표 예시로 든다. ignoreDifferences는 정확히 이런 상황을 위해 만들어진 기능이다.
다만 이 접근에는 한계가 있다. operator가 주입하는 기본값은 operator 버전에 종속적이라, KubeRay operator가 업그레이드되면서 새로운 기본값 필드를 추가하면 다시 OutOfSync가 발생한다. operator의 내부 구현 변경을 ArgoCD 설정이 쫓아가야 하는 구조인데, 유지보수 부담이 될 수 있다.
더 깊은 문제: 그래서 뭘 유지하는 걸까
여기까지는 표면 현상이다. ignoreDifferences로 OutOfSync를 가린다고 해도, 한 발 더 들어가면 더 본질적인 의문이 남는다.
이 RayJob에 ArgoCD를 쓰는 게 적합한 구조인가?
ArgoCD의 본래 목적은 “이 상태를 유지해라”이다. Deployment의 이미지 태그가 바뀌었거나, replicas 수가 변경됐거나, 누가 수동으로 리소스를 건드렸을 때 drift(상태 편차)를 감지해서 desired state로 되돌리는 것이 핵심 가치다. 즉 ArgoCD는 desired state가 장기적으로 유지되어야 하는 워크로드를 위해 만들어진 도구다.
그런데 RayJob은 다르다. 학습 Job은 한 번 실행하고 끝나는 일회성 작업이지, 상태가 지속적으로 관리될 필요가 있는 대상이 아니다.
| ArgoCD가 잘 맞는 리소스 | RayJob (학습 Job) | |
|---|---|---|
| 성격 | 장기 실행 서비스 (Deployment, StatefulSet) | 일회성 태스크 (run-to-completion) |
| 기대 | “Git과 클러스터가 항상 같아야 한다” | “한 번 실행하고 끝” |
| 상태 변화 | spec 변경 시에만 | controller가 status를 계속 변경 |
| 완료 후 | 계속 존재하면서 서빙 | SUCCEEDED 후 의미 없음 |
ArgoCD는 “desired state = actual state”를 유지하는 도구인데, RayJob은 실행되는 순간부터 controller가 상태를 바꾸기 때문에 desired ≠ actual이 구조적으로 발생한다. “잘못된” 것은 아니지만, ArgoCD가 이 상태를 조정하기 위해 할 수 있는 것이 없다.
ArgoCD가 의미를 가지려면 아래와 같은 구조가 성립해야 한다.
Git의 선언 상태 (desired) ↔ 클러스터 실제 상태 (actual)
↑ 변경 발생 시 ↑ ArgoCD가 맞춰줌
이 구조가 성립하려면 “항상 이 상태여야 한다“는 desired state가 존재해야 하고, 그것이 Git에 선언되어 있어야 한다. 학습 Job에 이런 의미의 desired state가 있을 수 있을까?
- 장기 실행 서비스(Airflow, MLflow 등)는 이 구조가 성립한다. replicas 수든 이미지 태그든, 원하는 상태가 있고 클러스터가 이 상태에서 벗어나면 ArgoCD가 selfHeal(자동 복구)을 통해 되돌린다.
- 학습 Job은 다르다. “이 학습을 한 번 실행해라“가 목적이지, “이 RayJob이 항상 존재해야 한다“가 아니다. 실행이 끝나면 SUCCEEDED 상태로 남은 RayJob은 의미가 없다. 다음 학습은 다른 이미지, 다른 파라미터를 쓸 수 있으니 같은 desired state를 유지할 이유 자체가 없다.
이 차이는 추상적인 이야기로 그치지 않는다. 실험을 하면서 직접 한 가지 함정을 발견했다.
직접 확인한 함정: Synced인데 학습이 시작되지 않는다
이전 실험에서 SUCCEEDED 상태로 종료된 RayJob이 클러스터에 남아 있는 상태에서, 학습 파라미터만 바꿔서(예: entrypoint의 인자 변경) values.yaml을 수정하고 ArgoCD를 다시 sync해 봤다.
ArgoCD 입장에서는 모든 단계가 깨끗하게 떨어졌다. sync는 성공했고, 클러스터의 RayJob .spec.entrypoint도 새 값으로 업데이트됐다. desired = actual, drift 없음, Application은 Synced. 하지만 새 학습은 시작되지 않았다.
원인은 KubeRay 소스에 있다. RayJob의 jobDeploymentStatus가 Complete 또는 Failed에 도달하면 그 상태는 terminal로 간주되고, 이후의 spec 변경은 controller에 의해 새 실행으로 이어지지 않는다. ArgoCD가 reconcile(조정)하는 단위(리소스의 desired vs actual 일치)와 RayJob controller가 reconcile하는 단위(작업 자체의 라이프사이클)가 서로 다른 레벨에서 작동하기 때문이다.
해결하려면 ArgoCD에는 손댈 게 없다. 기존 RayJob CR을 삭제하면(ownerReference로 RayCluster도 함께 정리됨) 그제서야 ArgoCD가 OutOfSync로 바뀌고, re-sync를 통해 새 RayJob이 만들어지면서 학습이 시작된다.
ArgoCD UI는 초록색이지만 그 너머의 controller는 아무 일도 하지 않는 상태이다. GitOps 관점에서 가장 위험한 종류의 false positive다. “Git과 클러스터가 같다”는 신호가 “내가 의도한 작업이 수행되고 있다”를 보장하지 못한다.
Operator 변이와 리소스 본질은 별개 문제
여기서 두 문제를 분리해서 봐야 한다.
| 문제 | 원인 | 해결 수단 | ArgoCD로 해결 가능한가 |
|---|---|---|---|
| Operator가 spec에 기본값을 주입해서 drift 발생 | CRD defaulting | ignoreDifferences |
O |
| 리소스 자체가 일회성이라 유지할 desired state가 없음 | 리소스의 본질 | 해결 수단 없음 | X |
operator가 필드를 추가하고 자식 리소스를 만드는 것 자체는 RayJob만의 문제가 아니다. 다른 operator-managed 리소스들도 같은 패턴을 가지지만, 그렇다고 ArgoCD로 관리하기 부적합한 것은 아니다.
- Zalando PostgreSQL (
acid.zalan.do/v1): operator가 credential secret 생성, replica pod 관리. 하지만 “이 DB가 항상 존재해야 한다”는 desired state가 유효 → ArgoCD 적합 - KServe InferenceService: Knative가 동적으로 revision, route 생성. 하지만 “이 서빙 엔드포인트가 항상 떠 있어야 한다”는 desired state가 유효 → ArgoCD 적합
- ExternalSecret: ESO가 K8s Secret을 동적 생성. 하지만 “이 secret이 항상 동기화되어야 한다”는 desired state가 유효 → ArgoCD 적합
이 사례들은 전부 operator가 필드를 추가하고 자식 리소스를 만들지만, “이 리소스가 이 설정으로 계속 존재해야 한다”는 전제가 성립한다. ignoreDifferences로 operator 변이를 무시하면 Synced 상태로 유지할 수 있다.
RayJob이 다른 이유는 operator 때문이 아니다. ignoreDifferences로 drift를 전부 무시하고 Synced로 만든다 해도, “그래서 뭘 유지하겠다는 건데?” 에 대한 답이 명확하지 않다. SUCCEEDED 상태의 RayJob을 Synced로 유지한다고 해서 그것이 어떤 의미를 갖는 걸까.
선언형 도구로 명령형 성격의 작업을 수행하고 있는 구조다. 학습은 “이 상태를 유지해라”가 아니라 “이걸 실행해라”를 위한 도구가 필요한데, ArgoCD는 전자를 위한 도구다.
외부 레퍼런스: 같은 방향을 가리키는 신호들
이 의문이 타당한지 외부 레퍼런스를 찾아봤다. 같은 결론을 직접 명시한 글을 찾기는 어려웠지만, 같은 방향을 가리키는 단서들은 여럿 있었다.
ArgoCD 프로젝트 자체의 인식
ArgoCD Issue #1639는 generateName을 쓰는 Job/Workflow가 즉시 OutOfSync가 되는 문제를 보고한 이슈다. 작성자가 jessesuen(Argo 공동 창시자)이고, 2025년 2월에 closed as not planned로 종료되었다. 이 이슈가 다루는 범위 자체는 좁지만(generateName 지원에 한정), ArgoCD 팀이 sync를 trigger 메커니즘으로 쓰는 패턴을 핵심 범위로 보지 않는다는 신호로 읽을 수 있다.
ArgoCD Best Practices 문서는 “Leaving Room For Imperativeness”라는 절에서 이렇게 말한다.
“If you want the number of your deployment’s replicas to be managed by HPA, then you would not want to track replicas in Git.”
모든 것을 Git에서 선언적으로 관리하는 게 최선이 아닌 경우가 있음을 ArgoCD 자체가 인정하고 있다. controller가 상태를 적극적으로 관리하는 리소스는 Git으로 추적하는 것이 잘 맞지 않을 수 있다.
Argo 프로젝트 내부의 역할 분리
같은 Argo 프로젝트 안에서 ArgoCD와 Argo Workflows는 명확히 분리되어 있다.
| 도구 | 역할 |
|---|---|
| ArgoCD | Declarative state 동기화 (인프라, 서비스) |
| Argo Workflows | Imperative task 실행 (ML 파이프라인, batch job) |
Argo Workflows 공식 문서는 주요 유스케이스 중 하나로 Machine Learning pipelines를 명시한다. 같은 Argo 프로젝트 안에서 두 도구가 분리돼 있다는 사실 자체가, declarative state 동기화와 imperative task 실행을 별개 도구로 다루겠다는 설계 결정을 반영한다.
ML 플랫폼들의 설계 선택
Kubeflow 아키텍처는 이 구분을 잘 보여준다. Kubernetes가 인프라를 declarative하게 관리하고, 그 위에서 Kubeflow Pipelines가 ML workflow를 orchestrate한다. 인프라 계층(declarative)과 실행 계층(imperative)을 섞지 않는 설계다. 실행 백엔드 선택에서도 이 분리가 드러나는데, KFP v2는 SDK 레벨에서 Argo Workflows로부터 디커플링되어 backend-agnostic한 IR YAML로 컴파일되면서도, Kubernetes 환경에서는 여전히 Argo Workflows를 실행 엔진으로 사용한다.
Ray 공식 문서에서도 RayJob은 명시적인 one-shot execution model로 설명된다. jobDeploymentStatus가 Complete 또는 Failed로 전이되고, shutdownAfterJobFinishes와 ttlSecondsAfterFinished로 자동 정리하는 것이 권장 패턴이다. 완료 후 continuous reconciliation이 불필요한 리소스인 것이다.
GitOps의 두 가지 의미
“GitOps가 ML training에 적합한가?”라는 질문에는 두 가지 의미를 구분해서 답해야 한다.
- 넓은 의미의 GitOps: 학습 설정(config, 파라미터, 환경)을 Git에 두고, 변경 시 워크플로우 엔진(Argo Workflows, Airflow 등)이 그 설정을 읽어 학습을 trigger한다는 뜻이라면 적합하다. 실제로 ML 영역에서 “GitOps for training”이라고 할 때 가리키는 패턴이 대개 이쪽이다.
- 좁은 의미의 GitOps: ArgoCD 같은 reconciliation 도구가 RayJob CR을 직접 sync해서 학습을 trigger한다는 뜻이라면, 본문에서 본 미스매치가 발생한다. 설정과 실행은 같은 Git 위에 있되, 실행 주체는 reconciliation 도구가 아니라 워크플로우 엔진이어야 한다.
1번 결론: 학습 Job은 ArgoCD의 영역이 아니다
학습 Job 자체를 ArgoCD로 trigger + reconcile하는 구조는 본질적인 미스매치를 가진다. operator 변이로 인한 OutOfSync는 ignoreDifferences로 가릴 수 있지만, “Synced인데 새 학습이 시작되지 않는” 함정처럼 더 깊은 곳에서 false positive가 발생한다.
학습 Job 실행은 워크플로우 엔진(Argo Workflows, Airflow 등)이 맡는 것이 자연스럽다. 같은 Argo 프로젝트 안에서 ArgoCD와 Argo Workflows가 분리되어 있는 이유, Kubeflow가 KFP라는 별도 레이어를 두는 이유가 여기에 있다.
2. ML 인프라에 GitOps를 적용할 수 있을까
이건 1번과 정반대다.
시작하기 전에: 어느 레이어를 다루는가
“ML 인프라”라고 한 덩어리로 묶었지만, 그 안에는 성격이 다른 두 레이어가 있다.
- 노드 레벨: OS 패키지, 컨테이너 런타임(containerd config, registry mirror 등), GPU 드라이버, K8s/K3s 자체 설정. 노드라는 기반에 직접 적용되는 설정들이다.
- 클러스터 리소스 레벨: operator, 서비스, manifest, secret 매핑. K8s API를 통해 다루는 모든 것이다.
ArgoCD는 K8s API 위에서 동작하는 도구라 노드 레벨 설정은 그 가시 범위 바깥이다. 두 레이어를 같은 도구로 다룰 수 없다.
| 레이어 | 도구의 영역 | 예시 |
|---|---|---|
| 노드 레벨 | IaC 도구 (Ansible, Terraform 등) | OS 패키지, 런타임 설정, GPU 드라이버, 레지스트리 mirror |
| 클러스터 리소스 | GitOps (ArgoCD) | operator, Helm chart, manifest, ExternalSecret |
이 글의 2번 섹션은 후자, 클러스터 리소스 레벨만 다룬다. 노드 레벨 IaC와 GitOps 사이의 역할 경계 자체도 흥미로운 주제인데, 기회가 된다면 별도로 정리해 보고 싶다.
왜 이 영역에 GitOps인가
수동 helm 커맨드와 SSH 접속에 의존해 ML 인프라를 운영하다 보면, 어느 순간 “개인의 기억에 의존하는 인프라” 상태가 된다. 사람이 바뀌면 지식이 유실되고, 컴포넌트가 늘어날수록 파편화는 가속된다.
직접 부딪혔던 장면들이 있다.
- 노드 하나가 디스크 고장으로 재구성이 필요했을 때, 다른 노드의 설정을 그대로 복사했지만 미묘한 차이로 동작하지 않았다. 정상 동작하던 노드의 “정답” 자체가 코드로 남아 있지 않았기 때문이다.
- 어떤 컴포넌트가 동작하지 않아 한참 디버깅하다가, 결국 노드 사이에 핵심 설정 하나가 다르게 들어가 있던 것이 원인이었음을 뒤늦게 발견한 적이 있다. 그 설정이 왜 그렇게 되어 있는지는 아무도 알지 못했다.
- staging 환경을 프로덕션과 동일하게 복제하는 일이 사실상 불가능했다. “프로덕션이 어떻게 떠 있는가”가 사람의 머리와 산발적인 문서에만 있어서, 동일하게 만든다는 것이 무엇을 의미하는지조차 합의가 안 됐다.
이런 한계는 운영 인력이 바뀔 때, 새 환경을 띄울 때, 사고에서 회복할 때 한꺼번에 드러난다. 플랫폼 자체의 기능 개선에 써야 할 시간을 인프라의 비일관성을 파악하고 수습하는 데 반복적으로 소모하게 된다.
위 사례 중 첫 두 개는 노드 레벨에 가까운 페인포인트라 ArgoCD 자체로는 풀리지 않는다. 다만 동일한 종류의 문제 — “선언된 정답이 없고, 사람의 기억에만 있는 상태” — 가 클러스터 리소스 레벨에서도 똑같이 일어난다. operator의 values를 누가 언제 바꿨는지, helm release가 어떤 버전이었는지, 이 ConfigMap이 왜 이런 상태인지가 모두 사람의 머리에 들어 있다. ArgoCD는 이 영역을 commit history와 자동 동기화로 옮긴다.
왜 ArgoCD가 적합한가
ArgoCD가 잘하는 일은 “이 상태로 항상 떠 있어야 한다”는 desired state를 Git으로 관리하고, drift를 자동 감지/복구하는 것이다. ML 플랫폼의 핵심 컴포넌트들은 정확히 이 모델에 들어맞는다.
- Operator 계열: 분산 컴퓨팅, GPU, 관측성 스택 operator 등
- 메타데이터·실험 추적 서비스
- 워크플로우 엔진 (예: Argo Workflows / Airflow / Prefect 중 하나)
- 서빙 컨트롤러 (예: KServe, Seldon 등)
- 보조 서비스: secret 동기화 operator, 인증서 관리, ArgoCD self-management
이들은 모두 1번의 RayJob과 다른 성격을 가진다.
| 인프라 컴포넌트 | RayJob (학습 Job) | |
|---|---|---|
| 성격 | 장기 실행 | 일회성 실행 |
| desired state | “이 설정으로 항상 떠 있어야 한다” | “한 번 실행하고 끝” |
| operator 변이 | 있을 수 있음 (ignoreDifferences로 처리) |
있음 |
| ArgoCD 적합도 | O | X |
App-of-apps 패턴
여러 컴포넌트를 하나의 ArgoCD Application으로 묶을 수도 있지만, ML 플랫폼처럼 컴포넌트 수가 많아지면 App-of-apps 패턴으로 계층화하는 것이 일반적이다. 부모 Application 하나가 디렉토리를 recurse하면서 그 아래에 있는 자식 Application들을 발견하고, 각 자식이 실제 컴포넌트를 배포한다.
환경별 디렉토리 레이아웃
소수의 환경(dev/stage/prod)을 운영하면서 컴포넌트가 환경마다 거의 동일하게 반복된다면, “환경 우선(env-first)” 디렉토리 레이아웃이 단순하다. 한 환경의 모든 컴포넌트가 한 트리 아래에 모이므로 “이 환경에 뭐가 있는지”가 한눈에 보이고, 환경별 권한 분리(AppProject)와 정합이 좋다.
apps/ ← ArgoCD Application CR (환경별 그룹핑)
shared/ ← 클러스터 공통 (operator, secret 동기화 등)
external-secrets/
app.yaml
infra.yaml
dev/
mlflow/
app.yaml ← Helm chart 설치 (wave 1)
infra.yaml ← namespace, quota, DB CR 등 raw manifest (wave 0)
monitoring/
helm-values/ ← Helm values 파일 ($values 참조 대상)
shared/
dev/
mlflow/values.yaml
monitoring/values.yaml
manifests/ ← Raw K8s manifest (namespace, quota, DB CR, route 등)
shared/
dev/
argocd/ ← ArgoCD 자체 설정 (수동 kubectl apply)
projects/ ← AppProject (환경별)
root-apps/ ← 환경별 root Application
bootstrap/ ← 1회성 수동 적용 (PriorityClass, health check 등)
이 구조의 핵심은 세 디렉토리의 역할 분리다.
apps/: ArgoCD Application CR만 둔다.recurse: true로 root가 이 디렉토리 전체를 스캔하므로 다른 종류의 YAML이 섞이면 그대로 클러스터에 적용되어 사고가 난다.helm-values/: 업스트림 Helm chart에 주입할 values 파일. Application CR의$valuessource가 이 디렉토리를 참조한다.manifests/: chart로 표현하기 어려운 raw 리소스 — namespace, ResourceQuota, LimitRange, DB operator의 CR, Gateway HTTPRoute, ExternalSecret 등.
Source 패턴: Multi-source Application
ML 플랫폼 컴포넌트 대부분은 업스트림에서 제공하는 Helm chart로 설치한다. 이때 chart는 손대지 않고 values만 우리 Git에 두는 게 자연스럽다. ArgoCD 2.6+의 multi-source Application이 이 패턴을 정확히 지원한다. 아래는 Grafana를 예로 든 형태인데, 어떤 chart든 구조는 동일하다.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: monitoring-dev-app
annotations:
argocd.argoproj.io/sync-wave: "1"
spec:
sources:
- repoURL: https://grafana.github.io/helm-charts # 업스트림 chart repo
chart: grafana
targetRevision: 8.x.x
helm:
releaseName: grafana
valueFiles:
- $values/helm-values/dev/monitoring/values.yaml
- repoURL: https://git.example.com/org/platform-infra.git
targetRevision: main
ref: values # ← 위에서 $values로 참조
destination:
server: https://kubernetes.default.svc
namespace: monitoring-dev
이렇게 두면 chart 버전 업그레이드는 targetRevision만 바꾸면 되고, 환경별 값 차이는 helm-values/<env>/<svc>/values.yaml에만 모인다. chart fork나 wrapper chart 없이 업스트림을 그대로 따라간다.
반면 chart화하기 애매한 리소스(예: operator가 watch하는 CR 묶음, 자체 제작한 ExternalSecret 묶음 등)는 raw manifest path로 가리키는 single-source Application이 더 깔끔하다.
spec:
source:
repoURL: https://git.example.com/org/platform-infra.git
targetRevision: main
path: manifests/dev/<service>
같은 컴포넌트를 두 개의 Application으로 쪼개는 패턴이 자주 등장한다. *-infra(wave 0)는 namespace·quota·DB CR·라우트 같은 기반 리소스를 raw manifest로 깔고, *-app(wave 1 또는 2)은 그 위에 Helm chart를 얹는다. 의존성이 명확해지고, drift 처리(ignoreDifferences)도 리소스 종류별로 분리해서 작성할 수 있다.
환경 분리
환경 우선 레이아웃에서는 환경별 독립성이 자연스럽게 따라온다.
- AppProject 분리:
platform-dev,platform-shared, (장래)platform-prod. 각 project의sourceRepos,destinations(허용 namespace),clusterResourceWhitelist를 환경별 권한으로 좁힌다. - Root Application 분리:
argocd/root-apps/dev.yaml은apps/dev/만,shared.yaml은apps/shared/만 스캔한다. dev 변경이 prod에 새어나갈 경로 자체를 구조로 차단한다. - values 분리:
helm-values/dev/...vshelm-values/prod/...로 환경별 값을 분리하되, chart 버전과ignoreDifferences같은 정책은 Application CR(apps/<env>/...)에서 관리해 환경 간 정책 차이를 한곳에서 본다.
환경 수가 많거나 multi-tenant(팀별 분리)가 필요한 단계로 가면 ApplicationSet으로 generator 기반 스캐폴딩을 도입하는 것이 다음 스텝이다. 다만 환경이 두세 개 수준일 때 ApplicationSet은 종종 과한 추상화라, 단순 디렉토리 + AppProject 분리로 시작해서 확장 시점에 옮기는 것이 무난하다.
Sync wave 기반 의존성 표현
ML 플랫폼에는 자연스러운 의존성이 있다. operator가 먼저 떠야 그 operator가 관리하는 CR이 의미를 가지고, secret이 먼저 있어야 secret을 참조하는 컴포넌트가 뜬다. ArgoCD의 sync wave는 이 의존성을 annotation 하나로 표현한다. 같은 wave 안의 리소스는 병렬로 sync되고, 낮은 wave가 모두 Healthy가 된 뒤에 다음 wave가 시작된다.
metadata:
annotations:
argocd.argoproj.io/sync-wave: "0" # 먼저
# argocd.argoproj.io/sync-wave: "1" # 나중
어떤 wave에 무엇을 두는가
일반적으로 wave는 다음과 같이 분류된다.
| Wave | 무엇이 뜨는가 | 왜 이 위치인가 |
|---|---|---|
| −2 ~ −1 | 클러스터 공통 기반 — secret 동기화 operator, 인증서 관리, 관측성 스택 등 | 여러 환경의 모든 컴포넌트가 의존하므로 가장 먼저 떠야 한다 |
| 0 | 환경별 기반 리소스 — namespace, ResourceQuota, LimitRange, DB CR, ExternalSecret CR, route 리소스 | namespace가 없으면 wave 1 리소스가 갈 곳이 없고, ExternalSecret이 동기화돼야 chart가 그 secret을 참조할 수 있다 |
| 1 | 플랫폼 서비스 — Helm chart로 설치하는 본체 (메타데이터/실험 추적, 워크플로우 엔진, 데이터 카탈로그, 모니터링 등) | wave 0의 namespace/secret/DB가 준비된 상태에서 안전하게 뜬다 |
| 2 | ML 워크로드 계층 — operator가 watch하는 클러스터/서비스 CR, 서빙 엔드포인트, runner pool 등 | 플랫폼 서비스가 떠 있어야 의미가 있는 상위 리소스 |
*-infra/*-app을 두 Application으로 쪼개는 패턴(앞서 언급)이 wave와 자연스럽게 맞물린다. *-infra는 wave 0, *-app은 wave 1 또는 2.
Sync wave가 동작하려면 health check가 정확해야 한다
wave 진행은 “낮은 wave 리소스가 Healthy 인가”로 결정되는데, ArgoCD 기본 health check는 일부 CR을 평가하지 못한다. 평가가 안 되면 status가 Progressing에서 멈추고, 다음 wave가 영원히 시작되지 않는다.
ML 플랫폼에서 자주 부딪히는 케이스들은 다음과 같다:
- DB operator의 CR (예: PostgreSQL operator의
postgresqlCR): 기본 health check 미정의 → status에서 Running 여부를 보고 Healthy를 판정하는 Lua 스크립트를argocd-cm에 넣어줘야 한다. ExternalSecret: secret이 실제로 동기화 완료된 시점을 wave 진행 신호로 삼아야 한다.Ready=Truecondition을 보고 Healthy를 판정한다.HTTPRoute(Gateway API): backend Service가 다음 wave에서 만들어지는 경우, 기본 health check는 backend가 없다고 보고 Degraded를 반환해 wave를 멈춘다.Accepted=True만 보고 Healthy로 판정하도록 우회하는 게 안전하다.- Application 자기 자신: App-of-apps 구조에서 부모가 자식 Application들의 health를 본다. 자식 Application의
status.health.status를 그대로 부모에 전파하는 health check가 있어야 wave가 의도대로 흐른다.
이 health check들은 클러스터 단 한 번만 패치하면 되므로 GitOps의 바깥, 즉 bootstrap 단계에서 kubectl patch configmap argocd-cm으로 적용한다.
Sync wave만으로 부족한 경우
순수 ArgoCD 차원에서 sync wave는 “이 리소스가 뜬 다음에 이 리소스가 뜬다”는 정도까지를 표현한다. 그보다 강한 의존성 — 예를 들어 “DB가 ready 되고, schema migration이 끝난 뒤에야 app이 떠야 한다” — 는 wave 위에 추가 메커니즘이 필요하다.
- PreSync/Sync/PostSync hook: ArgoCD의
argocd.argoproj.io/hookannotation으로 sync 단계별 Job을 끼워 넣는다. schema migration처럼 “한 번 실행되고 끝”인 작업에 적합하다. - Helm chart 내부 init/probe: chart 자체의 readiness/liveness probe와 init container로 의존 서비스 ready를 기다린다. ArgoCD의 영역 바깥이지만, 결과적으로 Application 단위 health에 자연스럽게 반영된다.
- operator 측 reconcile: 어떤 의존성은 operator가 알아서 해결한다(예: DB operator가 secret을 생성하면 chart가 그 secret을 참조). 이 경우 wave 0에 CR을 두고 wave 1에 chart를 두는 것만으로 충분하다.
한 가지 주의할 점은, sync wave는 단일 sync 작업 안에서의 순서라는 것이다. 이미 클러스터에 떠 있는 리소스에 변경이 들어올 때는 wave 진행이 동시에 일어난다고 가정해야 한다. wave를 “운영 중 의존성 보장”용으로 쓰면 안 된다.
Secret 관리
ML 플랫폼은 외부 시스템과 연결되는 지점이 많다. 모델 레지스트리, 객체 스토리지, 메트릭 백엔드, 외부 컨테이너 레지스트리, 깃 호스팅, 메시지 큐 등. 이런 secret을 Git에 두면 안 되고, 그렇다고 ArgoCD 외부에 두면 GitOps 일관성이 깨진다 — “클러스터의 어떤 상태가 Git에서 왔고 어떤 상태가 사람 손에서 왔는지” 추적이 흐려진다.
ESO(External Secrets Operator)는 이 문제의 표준 해법이다. 외부 secret store(Vault, 클라우드 사업자의 secret manager, GCP Secret Manager 등)에서 값을 가져와 K8s Secret으로 동기화한다. ArgoCD는 ExternalSecret CR만 관리하면 되고, 실제 값은 Git에 남지 않는다.
전체 흐름
[ Git: ExternalSecret CR ]
│ ArgoCD가 sync
▼
[ 클러스터의 ExternalSecret CR ]
│ ESO가 watch
▼
[ External Secrets Operator ] ──read──▶ [ 외부 Secret Store (Vault / Cloud SM / ...) ]
│ fetch한 값으로 K8s Secret 생성/갱신
▼
[ K8s Secret ]
│ envFrom / volumeMount
▼
[ Helm chart / Pod ]
요점은 Git에는 “어디서 어떤 키를 끌어다 어떤 K8s Secret으로 만들지”라는 매핑만 들어간다는 것이다. 값은 외부 store에 남고, ArgoCD는 매핑(ExternalSecret)만 reconcile한다.
ExternalSecret 예시
apiVersion: external-secrets.io/v1
kind: ExternalSecret
metadata:
name: grafana-admin
namespace: monitoring-dev
spec:
refreshInterval: 1h
secretStoreRef:
name: cloud-secrets-manager # 클러스터 단의 ClusterSecretStore
kind: ClusterSecretStore
target:
name: grafana-admin # 생성될 K8s Secret 이름
deletionPolicy: Retain # ExternalSecret 삭제돼도 K8s Secret은 보존
data:
- secretKey: admin-password # K8s Secret 안의 key
remoteRef:
key: platform-dev-grafana-admin # 외부 store의 secret 이름
property: admin-password # 외부 store의 키
이 CR을 컴포넌트의 *-infra 묶음(wave 0) 에 함께 넣어 두면, wave 1의 chart가 뜨기 전에 secret이 준비된다. chart 쪽은 자기 values에서 admin.existingSecret: grafana-admin 같은 식으로 이 K8s Secret을 가리키기만 하면 된다.
ClusterSecretStore vs SecretStore: 어떻게 가르나
ESO는 외부 store와의 연결 정보를 두 가지 CR 중 하나로 표현한다.
ClusterSecretStore (cluster-scoped) |
SecretStore (namespace-scoped) |
|
|---|---|---|
| 가시 범위 | 클러스터 전체 NS에서 참조 가능 | 자기 NS에서만 참조 가능 |
| 인증 정보(자격증명) 위치 | 보통 ESO 자체 NS(external-secrets)에 한 번만 둠 |
각 NS에 별도로 둬야 함 |
| 권한 분리 | 약함: 모든 NS가 같은 자격증명으로 store에 접근 | 강함: NS별로 다른 신원·다른 권한 |
| 적합한 경우 | 단일 환경(예: dev 한 클러스터)에서 모든 NS가 같은 store를 공유 | 멀티 테넌트, NS별 권한 격리가 필요한 경우 |
실용적인 출발점은 환경마다 ClusterSecretStore 하나를 두고 시작하는 것이다. dev 클러스터의 모든 컴포넌트가 dev용 외부 store에 read-only로 접근하는 단일 자격증명을 공유하는 모델이다. 권한 분리가 필요해지는 시점(예: 특정 팀의 secret에 다른 팀이 접근하면 안 되는 요건이 생길 때) SecretStore로 분리해 나간다.
apiVersion: external-secrets.io/v1
kind: ClusterSecretStore
metadata:
name: cloud-secrets-manager
spec:
provider:
aws: # provider만 갈아끼우면 Vault/GCP 등으로 전환
service: SecretsManager
region: <region>
auth:
secretRef:
accessKeyIDSecretRef:
name: cloud-sm-credentials
namespace: external-secrets
key: access-key-id
secretAccessKeySecretRef:
name: cloud-sm-credentials
namespace: external-secrets
key: secret-access-key
이 인증 secret(cloud-sm-credentials) 자체는 bootstrap 단계에서 사람이 직접 한 번 넣는 수밖에 없다. ESO가 외부 store에서 secret을 끌어오려면 자기가 외부 store에 인증할 수 있어야 하는데, 그 인증 정보를 또 ESO로 가져오려고 하면 닭-달걀 문제가 된다. 이런 secret은 의도적으로 GitOps 바깥에 둔다.
ESO 도입 후에도 GitOps 바깥에 남는 것들
전부 ESO로 옮기는 것은 비현실적이다. 의도적으로 바깥에 두는 항목들이 있다.
- ESO 자신의 인증 secret: 위에서 본 닭-달걀 문제.
- ArgoCD가 Git repo를 읽기 위한 자격 증명: ESO가 동기화하지 못하는 동안 Git 자체에 접근이 끊어지면 복구 경로가 없어진다.
- Helm chart가 자동 생성하는 secret: 일부 chart는 random fernet key, password 같은 secret을 매 render마다 새로 만든다. 이건 GitOps 대상이 아니라 chart 안의 부수 효과로 두는 게 안전하다.
- operator가 동적으로 만드는 credential (예: DB operator가 만드는 사용자별 connection secret): 이건 operator의 책임이다. chart 쪽에서 이 secret 이름을 직접 참조하기만 한다.
secret-specific 처방: existingSecretName으로 자동 생성을 우회하기
위 항목 중 “chart가 자동 생성하는 secret”은 1번 섹션의 RayJob 사례와 같은 구조의 문제를 일으킨다. chart가 매 render마다 다른 값을 채우면서 ArgoCD가 매번 OutOfSync를 잡는 것이다. 처방도 1번에서 본 것과 동일하게 ignoreDifferences로 비교 대상에서 제외하면 된다. 다만 secret 영역에서는 보통 두 가지 path를 같이 잡는다.
spec:
ignoreDifferences:
- group: ""
kind: Secret
jsonPointers:
- /data # secret 값 변경은 sync 대상에서 제외
- group: apps
kind: StatefulSet
jsonPointers:
- /spec/volumeClaimTemplates # PVC 템플릿 mutation도 자주 발생
다만 secret 영역에는 더 깨끗한 처방이 하나 더 있다. chart values에서 가능한 한 existingSecretName: <ESO가 만든 이름> 형태로 secret을 외부에서 주입하는 것. 이렇게 두면 chart의 secret 자동 생성 자체를 우회하고 secret의 진실의 원천을 외부 store에 통일할 수 있다. ignoreDifferences로 사후에 가리는 것보다 한 단계 위의 해법이다.
2번 결론: ML 인프라는 ArgoCD에 적합한 유스케이스다
ML 인프라는 desired state가 명확한 장기 실행 컴포넌트들의 집합이다. operator가 spec에 변이를 일으켜도 ignoreDifferences로 처리할 수 있고, 자식 리소스를 동적으로 만들어도 “이 리소스가 이 설정으로 계속 존재해야 한다”는 전제가 흔들리지 않는다.
App-of-apps + sync wave + ESO 정도의 조합으로, 수동 helm 운영의 한계(추적 가능성, 재현성, drift)를 대부분 해소할 수 있다. 노드 레벨까지 포함한 인프라 일관성은 IaC 도구의 영역으로 따로 다뤄야 하지만, 그 윗단의 클러스터 리소스만큼은 GitOps로 충분히 정합적인 운영이 가능하다.
3. 정리: 어디는 되고 어디는 안 되는가
같은 ML 도메인 안에서도 declarative와 imperative가 공존한다. 도구를 영역에 맞게 쓰는 것이 결국 GitOps의 본래 가치를 살리는 길이라 생각한다.
- Job 단위 실행(training, batch inference)은 워크플로우 엔진의 영역
- Job을 실행하기 위한 기반 인프라(클러스터 리소스 레벨)는 ArgoCD/GitOps의 정확한 유스케이스
- 노드 레벨 인프라(OS, 런타임, 드라이버)는 IaC 도구의 영역
- 설정의 Git 버전 관리(넓은 의미의 GitOps)는 모든 영역에 적용 가능
“MLOps에 GitOps를 적용한다”는 표현은 이 구분 위에서만 의미를 가진다. 무엇을 적용하는가, 어디에 적용하는가를 구분하지 않으면, OutOfSync가 영구히 켜져 있는 RayJob Application이나 Synced인데 새 학습이 시작되지 않는 함정 같은 문제가 생긴다.
참고 링크
- ArgoCD Diffing Customization
- ArgoCD Best Practices
- ArgoCD Issue #1639 - Support generateName for application resources
- ArgoCD Cluster Bootstrapping (App-of-apps)
- Argo Workflows - Machine Learning Use Cases
- RayJob Quickstart - Ray Documentation
- KubeRay rayjob_types.go (
IsJobDeploymentTerminal) - Kubeflow Architecture
- External Secrets Operator


댓글남기기