
[EKS] EKS GPU 트러블슈팅: 2. 실습 환경 구성 - 3. GPU 노드 프로비저닝 결과
정영준님의 AWS EKS Workshop Study(AEWS) 5주차 학습 내용을 기반으로 합니다.
TL;DR
이전 글에서 배포한 기반 인프라(GPU 0대, Helm 0개) 위에 GPU 노드 2대를 프로비저닝하고 GPU Operator를 설치한다.
- GPU 노드 프로비저닝: 이전 코드 분석에서 확인한 대로 AWS CLI로 스케일업. g5.xlarge × 2, 단일 AZ, ~2-3분만에 Ready
- GPU Operator 설치: Helm apply 25초 완료. 단, Helm
wait는 chart template 리소스(Deployment 3 + DaemonSet 1)만 감시하고, ClusterPolicy reconcile 산물(DaemonSet 6, Service 2 등)은 비동기로 생성된다 - end-to-end 검증: nvidia-smi Pod에서 Driver 580.126.09, CUDA 13.0, NVIDIA A10G 24GB 확인. AMI 내장 드라이버가 컨테이너까지 정상 전달됨
- Helm vs Operator 경계: Helm이 직접 생성하는 ~30개 리소스와 Operator가 reconcile로 만드는 ~50개 리소스의 경계를 확인
Pre-apply 상태 확인
이전 글의 배포 종료 시점에서 시작한다. GPU 노드 0대, Helm release 0개인 기반 인프라만 올라가 있는 상태다.
쿼터 재확인
aws sts get-caller-identity
aws service-quotas get-service-quota \
--service-code ec2 --quota-code L-DB2E81BA --region ap-northeast-2
{
"Account": "123456789012",
"Arn": "arn:aws:iam::123456789012:user/admin"
}
{
"Quota": {
"ServiceCode": "ec2",
"QuotaCode": "L-DB2E81BA",
"QuotaName": "Running On-Demand G and VT instances",
"Value": 8.0,
"Unit": "None"
}
}
g5.xlarge × 2 = 8 vCPU가 필요하고, 쿼터도 8 vCPU다. 사전 준비에서 증설한 딱 그 값이다. 여유가 없으므로 ASG 최대 노드 수 2 제한이 유효하다.
클러스터 현황
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP
ip-192-168-xx-xx.ap-northeast-2.compute.internal Ready <none> 62m v1.35.3-eks-bbe087e 192.168.xx.xx
ip-192-168-yy-yy.ap-northeast-2.compute.internal Ready <none> 62m v1.35.3-eks-bbe087e 192.168.yy.yy
helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kubectl get ns
NAME STATUS AGE
cert-manager Active 62m
default Active 72m
external-dns Active 62m
kube-node-lease Active 72m
kube-public Active 72m
kube-system Active 72m
시스템 노드 t3.medium × 2(AZ 2a/2c)가 62분째 Ready, Helm release 0개, gpu-operator 네임스페이스 없음. 이전 글의 종료 상태와 일치한다.
GPU 노드 스케일업
코드 분석에서 확인한 대로, 이미 존재하는 노드 그룹의 desiredSize는 EKS 모듈의 lifecycle.ignore_changes 때문에 Terraform으로 변경할 수 없다. AWS CLI로 직접 호출한다.
CLI 스케일업
aws eks update-nodegroup-config \
--cluster-name myeks5w \
--nodegroup-name myeks5w-ng-gpu \
--scaling-config minSize=0,maxSize=2,desiredSize=2 \
--region ap-northeast-2
{
"update": {
"id": "abcd1234-5678-90ef-ghij-klmnopqrstuv",
"status": "InProgress",
"type": "ConfigUpdate"
}
}
desiredSize=2로 설정했다. Terraform state는 건드리지 않으므로, TF 입장에서 이 노드 그룹의 desiredSize는 여전히 0이다. 의도된 드리프트(drift)다.
GPU 노드 Ready 대기
while true; do
READY=$(kubectl get nodes -l tier=gpu --no-headers 2>/dev/null \
| awk '$2=="Ready"' | wc -l)
TOTAL=$(kubectl get nodes -l tier=gpu --no-headers 2>/dev/null | wc -l)
echo "gpu nodes: ${READY}/${TOTAL} Ready"
[ "$READY" = "2" ] && break
sleep 20
done
gpu nodes: 2/2 Ready
g5.xlarge 2대가 단일 AZ(ap-northeast-2a)에서 ~2-3분 만에 Ready 상태에 도달했다. AL2023 NVIDIA AMI 부팅 후 nodeadm이 kubelet 등록을 완료하는 데까지 포함된 시간이다.
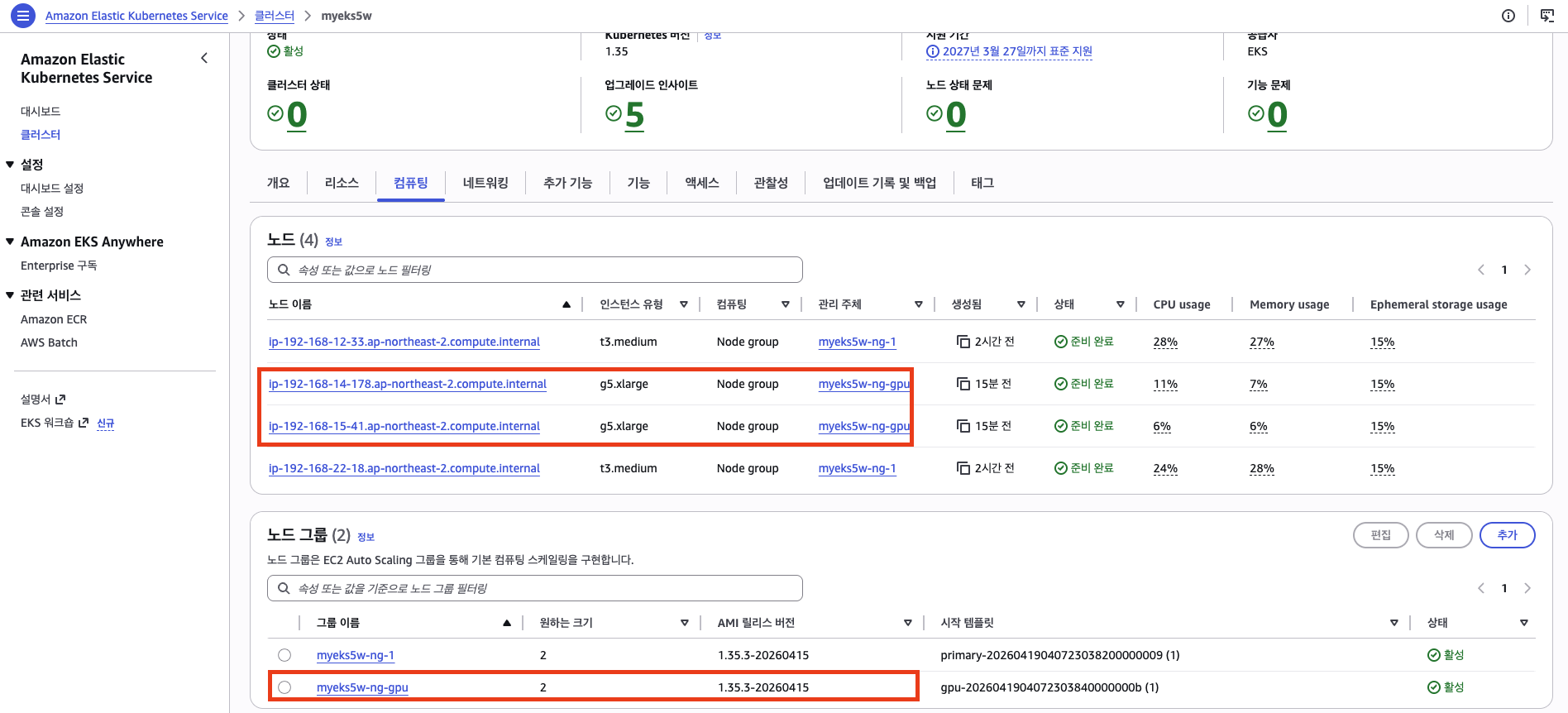
노드 상태 확인
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP NODE
ip-192-168-xx-xx.ap-northeast-2.compute.internal Ready <none> 65m v1.35.3-eks-bbe087e 192.168.xx.xx # primary, AZ 2a
ip-192-168-yy-yy.ap-northeast-2.compute.internal Ready <none> 65m v1.35.3-eks-bbe087e 192.168.yy.yy # primary, AZ 2c
ip-192-168-aa-aa.ap-northeast-2.compute.internal Ready <none> 2m v1.35.3-eks-bbe087e 192.168.aa.aa # gpu, AZ 2a
ip-192-168-bb-bb.ap-northeast-2.compute.internal Ready <none> 2m v1.35.3-eks-bbe087e 192.168.bb.bb # gpu, AZ 2a
GPU 노드 2대가 모두 ap-northeast-2a 단일 AZ에 배치된 것을 확인할 수 있다. 코드 분석에서 의도한 대로 NCCL 레이턴시를 최소화하는 배치다.
라벨 확인
kubectl get nodes -l tier=gpu --show-labels
GPU 노드에 붙은 주요 라벨을 정리하면 다음과 같다.
| 라벨 | 값 | 출처 |
|---|---|---|
tier |
gpu |
Terraform labels |
nvidia.com/gpu |
true |
Terraform labels |
nvidia.com/gpu.present |
true |
AMI bootstrap |
node.kubernetes.io/instance-type |
g5.xlarge |
EKS 자동 |
topology.kubernetes.io/zone |
ap-northeast-2a |
EKS 자동 |
nvidia.com/gpu.present=true가 눈에 띈다. 이 라벨은 Terraform labels에 명시하지 않았고 NFD(Node Feature Discovery)도 아직 설치되지 않은 상태다. AL2023 NVIDIA AMI의 nodeadm/bootstrap 스크립트가 kubelet 등록 시점에 직접 주입한 것이다. nodeSelector: nvidia.com/gpu.present=true 형태의 간단한 셀렉터는 NFD 없이도 동작할 수 있다는 뜻이다.
Pre-operator Allocatable
kubectl describe node ip-192-168-aa-aa.ap-northeast-2.compute.internal
Allocatable:
cpu: 3920m
ephemeral-storage: 95491281146
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15147936Ki
pods: 50
nvidia.com/gpu 항목이 없다. Device Plugin이 아직 동작하지 않으므로, kubelet은 GPU를 인식하지 못한다. 이 상태에서 nvidia.com/gpu: 1을 요청하는 Pod는 Insufficient nvidia.com/gpu로 Pending에 빠진다.
GPU Operator 설치
GPU 노드가 Ready된 상태에서 GPU Operator를 설치한다.
terraform plan + apply
terraform plan -var gpu_desired_size=2 -var enable_gpu_operator=true -out=e4.tfplan
Plan: 1 to add, 0 to change, 0 to destroy.
helm_release.gpu_operator[0] create 1건이다. 노드 그룹 scaling 변경은 ignore_changes 때문에 plan에 잡히지 않는다.
terraform apply e4.tfplan
helm_release.gpu_operator[0]: Creating...
helm_release.gpu_operator[0]: Creation complete after 25s [id=gpu-operator]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
25초만에 완료되었다. helm_release의 설정은 wait=true, timeout=900인데, 왜 이렇게 빠를까?
Helm wait의 범위
Helm의 wait는 chart template에 직접 포함된 Deployment/DaemonSet/Service의 Readiness만 감시한다. 이전 글에서 확인한 대로, Helm template이 직접 생성하는 리소스는 27개이고, 그중 Readiness를 기다리는 대상은 Deployment 3개 + DaemonSet 1개(nfd-worker)뿐이다.
ClusterPolicy CR은 Helm 입장에서 단순한 manifest create다. 이 CR을 Operator 컨트롤러가 watch하다가 reconcile로 DaemonSet, Service, ConfigMap 등을 비동기로 만들어낸다. 즉, Helm이 “deployed” 상태를 선언한 25초 시점에 Operator reconcile 산물은 아직 생성 중일 수 있다.
| Helm “deployed” (25초) | Operator reconcile 완료 |
|---|---|
| Deployment 3 (operator, nfd-master, nfd-gc) | DaemonSet 6개 |
| DaemonSet 1 (nfd-worker) | Service 2개 |
| ServiceAccount 2 | ServiceAccount/Role/RoleBinding 6세트 |
| ClusterPolicy CR 1 (manifest create만) | ConfigMap 3개 |
| … | Validator Job 4개 |
Helm release deployed ≠ “모든 GPU가 준비됨”이다. 실제 준비 완료 판단 기준은
kubectl get clusterpolicy -o jsonpath='{.items[0].status.state}'가ready인 시점 + GPU 노드 Allocatable에nvidia.com/gpu가 노출되는 시점이다.
Helm/Operator 상태 확인
helm list -n gpu-operator
NAME NAMESPACE REVISION STATUS CHART APP VERSION
gpu-operator gpu-operator 1 deployed gpu-operator-v26.3.1 v26.3.1
kubectl get pods -n gpu-operator -o wide
| STATUS | 개수 | Pod |
|---|---|---|
| Running | 13 | operator, nfd-master/gc/worker, gpu-feature-discovery, dcgm-exporter, device-plugin, operator-validator 등 |
| Completed | 4 | nvidia-cuda-validator × 2, nvidia-device-plugin-validator × 2 |
| 합계 | 17 | driver/toolkit Pod 0개 (AMI 내장, disabled 의도) |
kubectl get ds -n gpu-operator
| DaemonSet | DESIRED | READY | 비고 |
|---|---|---|---|
| gpu-operator-node-feature-discovery-worker | 4 | 4 | 전체 노드(primary 2 + gpu 2) |
| nvidia-gpu-feature-discovery | 2 | 2 | GPU 노드만 |
| nvidia-dcgm-exporter | 2 | 2 | GPU 노드만 |
| nvidia-device-plugin-daemonset | 2 | 2 | GPU 노드만 |
| nvidia-operator-validator | 2 | 2 | GPU 노드만 |
| nvidia-device-plugin-mps-control-daemon | 0 | 0 | MPS 미사용 |
| nvidia-mig-manager | 0 | 0 | MIG 미사용 |
DaemonSet 7개 중 활성 5개, 비활성 2개(MPS/MIG). nfd-worker만 전체 노드에, 나머지는 GPU 노드에만 배치된다.
kubectl get clusterpolicy -o jsonpath='{.items[0].status.state}'
ready
ClusterPolicy status.state가 ready다. “all resources have been successfully reconciled” — Operator가 필요한 리소스를 모두 생성하고 정상 상태를 확인한 것이다.
GPU 검증
Post-operator Allocatable
kubectl describe node ip-192-168-aa-aa.ap-northeast-2.compute.internal
Capacity:
nvidia.com/gpu: 1
Allocatable:
cpu: 3920m
ephemeral-storage: 95491281146
memory: 15147936Ki
nvidia.com/gpu: 1
pods: 50
nvidia.com/gpu: 1이 Capacity와 Allocatable 모두에 나타난다. Device Plugin DaemonSet이 GPU를 kubelet에 등록한 결과다.
| 항목 | Pre-operator | Post-operator |
|---|---|---|
nvidia.com/gpu |
없음 | 1 |
cpu |
3920m | 3920m |
memory |
15147936Ki | 15147936Ki |
GPU 외 다른 Allocatable 값은 변하지 않았다. Device Plugin은 GPU 리소스 광고(advertisement)만 담당하고, CPU/메모리에는 영향을 주지 않는다.
nvidia-smi Pod
GPU taint toleration과 nvidia.com/gpu: 1 resource limits를 지정해 Pod를 실행하고, 컨테이너 내부에서 GPU 드라이버가 보이는지 최종 검증한다.
kubectl run smi --restart=Never \
--image=nvidia/cuda:12.4.1-base-ubuntu22.04 \
--overrides='{
"spec": {
"containers": [{
"name": "smi",
"image": "nvidia/cuda:12.4.1-base-ubuntu22.04",
"command": ["nvidia-smi"],
"resources": {
"limits": {"nvidia.com/gpu": "1"}
}
}],
"tolerations": [{
"key": "nvidia.com/gpu",
"operator": "Exists",
"effect": "NoSchedule"
}]
}
}'
kubectl logs smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
|--------------------------------------------+------------------------+-------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
|============================================+========================+====================+
| 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 |
| 0% 28C P8 24W / 300W | 0MiB / 23028MiB | 0% Default |
+--------------------------------------------+------------------------+-------------------+
트러블슈팅: 처음
kubectl run --rm -i조합으로 실행했을 때 stdout 캡처에 실패했다.--rm을 제거하고kubectl logs→kubectl delete pod순서로 재실행하면 정상 수집된다.
Pod 내부에서 NVIDIA A10G(23028MiB)가 정상 인식되었다. 주요 필드를 해석하면 다음과 같다.
| 필드 | 값 | 의미 |
|---|---|---|
| NVIDIA-SMI / Driver Version | 580.126.09 | 호스트(AMI)에 설치된 커널 드라이버 버전. Operator가 아닌 AL2023 NVIDIA AMI 내장 |
| CUDA Version | 13.0 | 드라이버가 지원하는 최대 CUDA 런타임 버전. 실제 사용 버전은 애플리케이션이 결정 |
| GPU 0 | NVIDIA A10G | g5.xlarge에 탑재된 Ampere 아키텍처 GPU |
| Memory | 0MiB / 23028MiB | VRAM 24GB 중 사용량 0 — idle 상태 정상 |
| Persistence-M | On | Persistence Mode 활성화. GPU 초기화 오버헤드 없이 즉시 사용 가능 |
| Perf | P8 | 최저 성능 상태(P0이 최고). idle 시 전력 절약을 위해 자동 전환 |
| Pwr | 24W / 300W | idle 전력 24W, TDP 300W |
| ECC | 0 | Uncorrectable ECC 에러 0건. 메모리 정상 |
Driver 580.126.09는 AL2023 NVIDIA AMI에 내장된 드라이버다. gpu-operator 네임스페이스에 nvidia-driver-daemonset이 없는 것과 함께, AMI가 드라이버를 담당하고 Operator는 관측/device-plugin 레이어만 담당하는 아키텍처가 검증되었다.
이제 검증용 Pod을 삭제한다.
kubectl delete pod smi
Helm vs Operator reconcile 분리
GPU Operator의 리소스는 두 경로로 나뉜다. Helm이 직접 생성하는 것(1)과 Operator 컨트롤러가 ClusterPolicy reconcile로 만들어내는 것(2)이다.
분리 조회
# Helm이 직접 생성한 리소스 (managed-by=Helm 라벨)
kubectl get all,sa,role,rolebinding,configmap,secret \
-n gpu-operator -l app.kubernetes.io/managed-by=Helm
# 전체 네임스페이스 객체 (Operator reconcile 산물 포함)
kubectl get all,sa,role,rolebinding,configmap,secret -n gpu-operator
# cluster-scoped 분리
kubectl get clusterrole,clusterrolebinding \
-l app.kubernetes.io/managed-by=Helm
두 결과의 차이가 곧 Operator reconcile 산물이다.
1. Helm이 직접 생성한 리소스
app.kubernetes.io/managed-by=Helm 라벨이 붙은 리소스다. 이전 글에서 helm template으로 확인한 27개 리소스에 설치 시점 Job/CRD 몇 개가 더해진다.
| 종류 | 개수 | 리소스 |
|---|---|---|
| Deployment | 3 | gpu-operator(controller), nfd-master, nfd-gc |
| DaemonSet | 1 | nfd-worker (전체 노드 4개) |
| ServiceAccount | 2 | gpu-operator, node-feature-discovery |
| Role / RoleBinding | 2 / 2 | gpu-operator, nfd-worker |
| ConfigMap | 2 | nfd-master-conf, nfd-worker-conf |
| ClusterRole / ClusterRoleBinding | 10 | cluster-scope |
| ClusterPolicy (CR) | 1 | cluster-policy — Helm values에서 렌더링 |
| Jobs (install hooks) | 2 | nfd-prune, upgrade-crd-hook |
| CRDs | 5 | clusterpolicies, nvidiadrivers, nodefeatures, nodefeaturegroups, nodefeaturerules |
| 소계 | ~30 |
Helm이 직접 만드는 DaemonSet은 nfd-worker 단 1개다. device-plugin, dcgm-exporter, gpu-feature-discovery 등은 여기에 포함되지 않는다.
2. Operator reconcile 산물
Operator 컨트롤러가 ClusterPolicy CR을 watch하고, reconcile 과정에서 추가 생성한 리소스다.
Operator reconcile 리소스 상세
| 종류 | 개수 | 리소스 |
|---|---|---|
| DaemonSet | 6 | gpu-feature-discovery, nvidia-dcgm-exporter, nvidia-device-plugin-daemonset, nvidia-device-plugin-mps-control-daemon(0/0), nvidia-mig-manager(0/0), nvidia-operator-validator |
| Service | 2 | gpu-operator:8080(metrics), nvidia-dcgm-exporter:9400(Prometheus) |
| ServiceAccount | 7 | 각 컴포넌트당 1개 + k8s default |
| Role / RoleBinding | 6 / 6 | 6개 컴포넌트 매핑 |
| ConfigMap | 3 | default-gpu-clients, default-mig-parted-config, nvidia-device-plugin-entrypoint 등 |
| Validator Job Pod | 4 | nvidia-cuda-validator × 2, nvidia-device-plugin-validator × 2 |
| NodeFeature CR | 6 | NFD worker가 각 노드의 feature를 CR로 기록 |
| Node 라벨 | 89개/gpu-node | nvidia.com/*, feature.node.kubernetes.io/* |
한 가지 눈에 띄는 점은 nvidia-driver-daemonset과 nvidia-container-toolkit-daemonset이 없다는 것이다. 이 둘도 원래는 Operator reconcile 산물이지만, gpu_operator.tf의 Helm values에서 driver.enabled=false, toolkit.enabled=false로 비활성화했기 때문에 생성되지 않았다. AL2023 NVIDIA AMI에 Driver 580 + nvidia-container-toolkit이 이미 번들되어 있으므로 Operator가 별도로 설치할 필요가 없는 것이다.
이를 2중으로 증명할 수 있다.
gpu-operator네임스페이스에 driver/toolkit DaemonSet이 없음- nvidia-smi Pod 로그에서 Driver 580.126.09가 노출됨 → AMI 내장 드라이버가 컨테이너까지 전달
이것이 EKS GPU 운영의 권장 경로다. AMI가 드라이버/toolkit을 담당하고, Operator는 device-plugin·NFD·DCGM 등 관측/스케줄링 레이어만 담당한다.
CRD와 NFD 라벨
kubectl get crd | grep -iE 'nvidia|nfd'
NAME CREATED AT
clusterpolicies.nvidia.com 2026-04-19T05:39:15Z
nvidiadrivers.nvidia.com 2026-04-19T05:39:15Z
nodefeatures.nfd.k8s-sigs.io 2026-04-19T05:39:16Z
nodefeaturegroups.nfd.k8s-sigs.io 2026-04-19T05:39:16Z
nodefeaturerules.nfd.k8s-sigs.io 2026-04-19T05:39:16Z
5개 CRD가 Helm install 과정에서 등록되었다. CRD는 cluster-scoped이므로 네임스페이스에는 보이지 않지만, ClusterPolicy와 NodeFeature CR이 이 CRD로부터 인스턴스화된다. Helm uninstall 시에도 CRD는 삭제되지 않는 것이 현재 chart의 기본 동작이다(데이터 손실 방지).
NFD 라벨 변화
GPU 노드의 nvidia.com/*, feature.node.kubernetes.io/* 라벨 수를 비교하면 다음과 같다.
| 시점 | 라벨 수 | 출처 |
|---|---|---|
| Pre-operator | 3개 (tier=gpu, nvidia.com/gpu=true, nvidia.com/gpu.present=true) |
Terraform 2개 + AMI bootstrap 1개 |
| Post-operator | 89개 | + NFD worker + gpu-feature-discovery |
NFD worker와 gpu-feature-discovery가 GPU 노드의 하드웨어/드라이버 정보를 감지하고, nvidia.com/cuda.driver.major, nvidia.com/gpu.compute.major, feature.node.kubernetes.io/cpu-model.vendor_id 등 상세 라벨을 추가한다.
앞서 언급한 대로 nvidia.com/gpu.present=true는 NFD 이전부터 AMI bootstrap이 주입한다. NFD 미설치 경량 운영에서도 이 라벨 기반의 간단한 nodeSelector는 동작하지만, 나머지 86개 세부 라벨은 사용할 수 없다는 trade-off가 있다.
정리
클러스터 규모 변화
이전 글의 배포 결과(E-bundle)와 이번 GPU 프로비저닝 결과(E-4)를 비교한다.
| 항목 | 배포 직후 (E-bundle) | GPU 프로비저닝 후 (E-4) | 변화 |
|---|---|---|---|
| 노드 총수 | 2 (t3.medium × 2) | 4 (+ g5.xlarge × 2) | +2, CLI 경로 |
| GPU NG desired/max | 0 / 2 | 2 / 2 | CLI 경로 |
| Helm releases | 0 | 1 (gpu-operator v26.3.1) | TF 경로 |
| gpu-operator ns | 없음 | Pod 17개 (Running 13 + Completed 4) | Helm create_namespace=true |
| CRD (nvidia/nfd) | 0 | 5 | Helm install |
GPU 노드 Allocatable nvidia.com/gpu |
— | 1/node | device-plugin |
| GPU 노드 라벨 수 | — | 89개/node | NFD + gpu-feature-discovery |
| 일 비용(대략) | ~$6/일 | ~$54/일 | g5.xlarge × 2 on-demand 가산 |
GPU 노드 상세
| 항목 | 값 |
|---|---|
| 인스턴스 | g5.xlarge × 2 |
| AMI | AL2023_x86_64_NVIDIA |
| AZ | ap-northeast-2a (단일 AZ 고정) |
| Taint | nvidia.com/gpu=true:NoSchedule |
| Pre-operator Allocatable GPU | 없음 |
| Post-operator Allocatable GPU | 1 |
| Driver | 580.126.09 (AMI 내장) |
| CUDA | 13.0 |
| GPU | NVIDIA A10G, 23028MiB (24GB) |
핵심 발견
1. Helm wait과 Operator reconcile의 비대칭
terraform apply가 25초만에 완료되지만, Helm wait가 감시하는 범위는 chart template의 Deployment 3 + DaemonSet 1뿐이다. Device Plugin, DCGM Exporter, GPU Feature Discovery 등 핵심 컴포넌트는 ClusterPolicy reconcile의 비동기 산물이므로, Helm deployed 직후에는 아직 GPU가 준비되지 않았을 수 있다. 실제 준비 완료 판단은 clusterpolicy.status.state == ready + Allocatable에 nvidia.com/gpu 노출 여부로 해야 한다.
2. AMI 내장 드라이버 + Operator 레이어만 아키텍처
AL2023 NVIDIA AMI가 Driver 580 + nvidia-container-toolkit을 제공하고, GPU Operator는 driver.enabled=false, toolkit.enabled=false로 device-plugin·NFD·DCGM 등 관측/스케줄링 레이어만 운영한다. nvidia-smi로 AMI 드라이버가 컨테이너까지 정상 전달됨을 확인했다.
3. AMI bootstrap 라벨 nvidia.com/gpu.present=true
NFD 미설치 상태에서도 AL2023 NVIDIA AMI의 nodeadm이 nvidia.com/gpu.present=true 라벨을 주입한다. NFD 설치 후에는 89개로 증가하지만, 경량 운영에서는 이 라벨만으로도 GPU 노드 셀렉터가 동작한다.
재현용 명령 요약
# 1) GPU NG 스케일업 (CLI — TF의 ignore_changes 때문에 CLI 필수)
aws eks update-nodegroup-config \
--cluster-name myeks5w --nodegroup-name myeks5w-ng-gpu \
--scaling-config minSize=0,maxSize=2,desiredSize=2 \
--region ap-northeast-2
# 2) GPU 노드 Ready 대기
kubectl get nodes -l tier=gpu
# 3) GPU Operator Helm 설치
terraform plan -var gpu_desired_size=2 -var enable_gpu_operator=true -out=e4.tfplan
terraform apply e4.tfplan
# 4) 검증
kubectl get clusterpolicy -o jsonpath='{.items[0].status.state}' # ready
kubectl describe node <gpu-node> | grep nvidia.com/gpu # Allocatable: 1
kubectl run smi --restart=Never \
--image=nvidia/cuda:12.4.1-base-ubuntu22.04 \
--overrides='...' # Driver 580, CUDA 13.0, A10G
kubectl logs smi && kubectl delete pod smi
# 5) 종료 시 (비용 가드)
aws eks update-nodegroup-config \
--cluster-name myeks5w --nodegroup-name myeks5w-ng-gpu \
--scaling-config minSize=0,maxSize=2,desiredSize=0 \
--region ap-northeast-2
다음 단계
이 GPU 환경 위에서 다음 순서로 트러블슈팅 시나리오를 진행한다.
- Device Plugin 비활성화: ClusterPolicy
devicePlugin.enabled: false패치로 GPU Allocatable 소실 → Pod Pending 장애 재현 - vLLM 기동 실패: vLLM 14B-AWQ 서빙 중 기동 실패 시나리오 4가지 재현 및 디버깅
- 분산학습 배경 및 실험 설계: 분산학습 원리, NCCL 통신 계층, EKS에서의 재현 실험 설계
- SG 차단 네트워크 장애 재현: EKS node SG ephemeral self-ref 제거로 분산학습 네트워크 장애 재현


댓글남기기