
[GenAI] GenAI on K8s: 4.2 - RAG (Retrieval-Augmented Generation)
Kubernetes for Generative AI Solutions(Packt 2025, ISBN 978-1-83620-993-5, 저자 Ashok Srirama / Sukirti Gupta) 4장의 학습 내용을 바탕으로 합니다
이전 글에서 도메인 특화 최적화의 3가지 기법을 비교했다. 이번 글에서는 그 중 첫 번째 핵심 기법인 RAG(Retrieval-Augmented Generation)를 깊이 다룬다.
TL;DR
- RAG는 5단계 파이프라인으로 구성된다: Embedding → Storing → Indexing → Retrieval → Final Interaction
- 1~3단계는 오프라인 배치, 4~5단계는 온라인 실시간. 비용과 지연시간은 온라인 단계에 집중된다
- LLM 입장에서 RAG는 단순히 “input이 길어진 것”일 뿐이다. 외부 검색 결과를 prompt에 텍스트로 붙여 넣는 것이 전부다
- RAG의 query와 Transformer attention의 Q(Query)는 완전히 다른 개념이다. 혼동하지 말 것
- hallucination(환각) 비교: RAG 없이 동일 질문 시 “Shirt A”, “Shirt B” 같은 가상의 결과를 생성. RAG 적용 시 실제 카탈로그 ProductID 기반 응답
- RAG는 도메인 정보 주입 + hallucination 확률 감소를 동시에 달성하지만, 검색 정확도와 문서 신뢰도가 여전히 변수다
RAG 동작 단계
RAG(Retrieval-Augmented Generation, 검색 증강 생성)는 외부 지식을 LLM에 주입하는 파이프라인이다. 총 5단계로 나눌 수 있다.
| # | 단계 | 시점 | 무엇을 하는가 | 비유 |
|---|---|---|---|---|
| 1 | Embedding (문서) | 인덱싱 시 (배치) | 외부 문서들을 embedding model에 통과 → 고차원 벡터화 | 책 한 권을 한 줄 요약 벡터로 |
| 2 | Storing (벡터 DB) | 인덱싱 시 | 벡터들을 vector DB에 저장 | 도서관 책장에 꽂기 |
| 3 | Indexing | 인덱싱 시 | 벡터들을 빠른 검색이 가능한 자료구조(HNSW/IVF/tree)로 조직 | 도서관 색인 카드 만들기 |
| 4 | Retrieval | 요청 시 (실시간) | 사용자 query를 같은 embedding model로 벡터화 → DB 검색 → top-K 유사 문서 회수 | 사서가 색인 보고 책 가져옴 |
| 5 | Final Interaction | 요청 시 | retrieved docs + original query를 prompt에 끼워 LLM 호출 | 책 발췌 + 질문을 같이 묻기 |
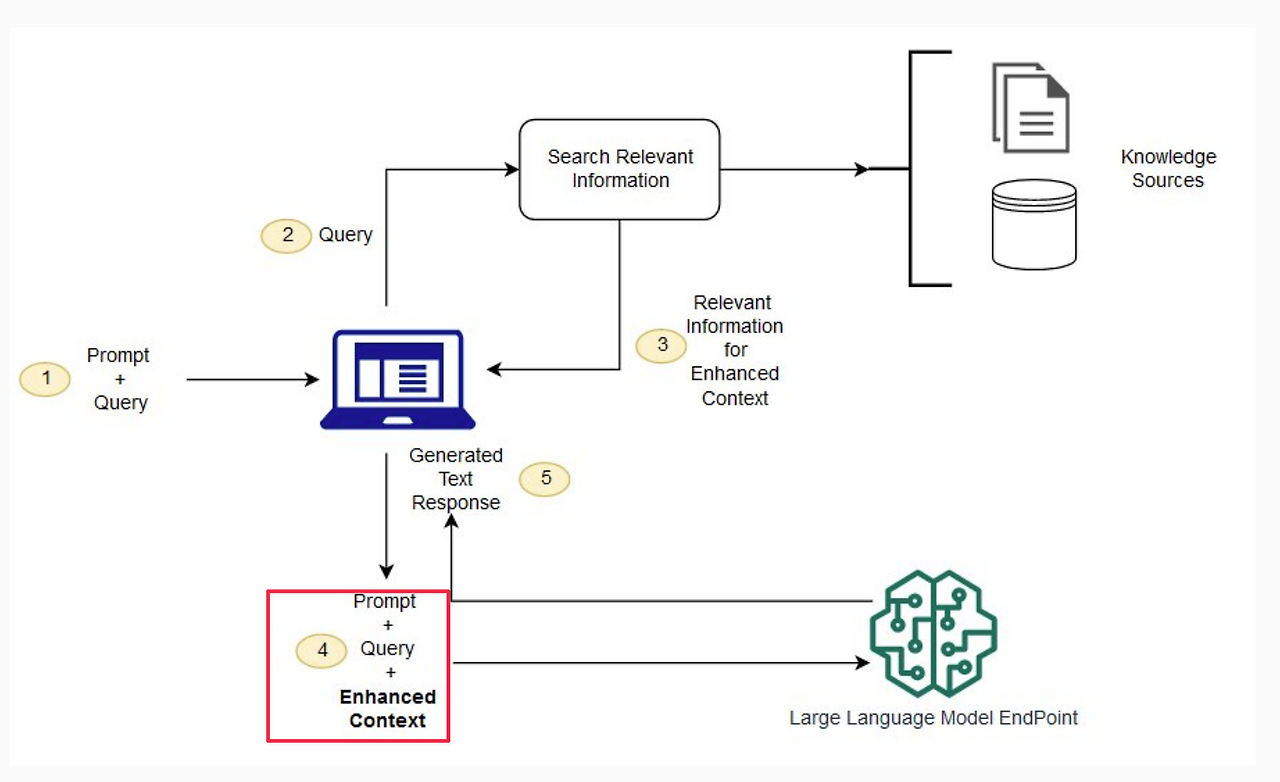 출처: Understanding Retrieval Augmented Generation - AWS Prescriptive Guidance
출처: Understanding Retrieval Augmented Generation - AWS Prescriptive Guidance
Offline(1~3) vs Online(4~5)
- 1~3단계: 한 번 (또는 문서 변경 시) 수행하는 오프라인 배치 작업이다. embedding 모델을 교체하면 전체 재인덱싱이 필요하다.
- 4~5단계: 매 요청마다 수행하는 온라인 실시간 작업이다. 비용과 지연시간(latency)이 이 두 단계에 집중된다.
책에서는 4단계
책(p.72)에서는 위의 5단계를 4단계로 정리하고 있다.
| 책의 4단계 | 본 글의 5단계 매핑 | 설명 |
|---|---|---|
| 1. Embedding | 1. Embedding | 동일 |
| 2. Storing & Indexing | 2. Storing + 3. Indexing | 두 단계를 하나로 묶음 |
| 3. Retrieval | 4. Retrieval | 동일 |
| 4. Final Interaction | 5. Final Interaction | 동일 |
묶은 이유는 실용적이다. 대부분의 벡터 DB 클라이언트(LangChain, LlamaIndex 등)가 “문서를 넣으면 임베딩 → 저장 → 인덱스 갱신”을 한 번의 API 호출로 처리하기 때문에, 사용자 입장에서 Storing과 Indexing이 분리되는 순간이 없다. 아래 실습에서 사용하는 DocArrayInMemorySearch.from_documents(documents, embeddings) 한 줄이 대표적인 예다.
다만 프로덕션 규모에서는 이 둘이 분리될 수 있다. 예를 들어 Pinecone이나 Weaviate 같은 managed 벡터 DB에서는 데이터 적재(upsert)와 인덱스 리빌드 타이밍이 다르고, HNSW 파라미터 튜닝이나 인덱스 교체 같은 작업은 Storing과 독립적으로 일어난다. 개념적으로 분리해서 이해하는 편이 맞다.
DocArrayInMemorySearch.from_documents 내부 동작
그렇다면 “한 줄 호출”이 내부에서 실제로 뭘 하는지 소스를 보자. DocArrayInMemorySearch는 LangChain이 제공하는 인메모리 벡터 스토어 중 하나로, DocArray 라이브러리를 백엔드로 사용한다. 본 실습에서 사용한 벡터 DB이기도 하다.
# 베이스 VectorStore.from_documents
@classmethod
def from_documents(cls, documents, embedding, **kwargs):
texts = [d.page_content for d in documents]
metadatas = [d.metadata for d in documents]
return cls.from_texts(texts, embedding, metadatas=metadatas, **kwargs)
# DocArrayInMemorySearch.from_texts
@classmethod
def from_texts(cls, texts, embedding, metadatas=None, **kwargs):
store = cls.from_params(embedding, **kwargs) # ① 빈 DocArray 컨테이너 + 인덱스 자료구조 초기화 (Storing)
store.add_texts(texts=texts, metadatas=metadatas) # ② 텍스트마다 embedding API 호출 → 1536D 벡터 → 삽입 + 인덱스 갱신
return store
흐름을 정리하면:
from_documents→ 문서에서 텍스트와 메타데이터를 추출from_texts→ 빈 스토어 초기화(①) 후, 각 텍스트를 임베딩하여 저장 및 인덱스 갱신(②)
OpenAIEmbeddings.embed_query: 단일 텍스트 임베딩
Retrieval 단계에서 사용자 query를 벡터화할 때 호출되는 embed_query는 다음과 같다.
def embed_query(self, text, **kwargs):
self._ensure_sync_client_available()
return self.embed_documents([text], **kwargs)[0]
단일 텍스트를 batch size 1로 embed_documents에 보내고 첫 결과만 빼내는 wrapper다. 문서 임베딩과 쿼리 임베딩이 동일한 모델·동일한 벡터 공간을 공유한다는 점이 핵심이다.
핵심: LLM 입장에서는 input이 길어질 뿐
RAG를 처음 접하면 “검색된 문서가 LLM 내부의 Q 행렬에 들어간다”거나 “RAG의 query와 attention의 Q는 같다”는 직관을 갖기 쉽다. 틀렸다.
LLM 입장에서 RAG는 단순히 prompt 텍스트가 길어진 것일 뿐이다. 외부에서 검색했든, 사람이 직접 붙여넣었든, LLM은 구분하지 못한다. 아래 흐름을 보자.
사용자 query: "회색 정장에 어울리는 셔츠 추천해줘"
↓
[embedding model — RAG 전용, 예: text-embedding-ada-002]
↓
query 벡터 (1536차원)
↓
[Vector DB — cosine similarity 검색]
↓
top-5 문서 (셔츠 카탈로그 row 5개의 텍스트)
↓
─────────────────────────────────────────────────
여기부터는 그냥 "텍스트 합치기" — 행렬 주입이 아님
prompt = f"""
{retrieved_doc_1_text}
{retrieved_doc_2_text}
...
{retrieved_doc_5_text}
Question: 회색 정장에 어울리는 셔츠 추천해줘
"""
─────────────────────────────────────────────────
↓
[LLM (gpt-3.5-turbo 등)]
↓
토큰화
↓
X (입력 임베딩 행렬, row가 그만큼 늘어남)
↓
평소와 똑같은 self-attention
↓
응답
비유하자면, RAG는 오픈북 시험이다. 매 시험(요청)마다 책(외부 DB)에서 찾아서 답안(prompt)에 첨부한다. 반대 방향의 접근인 Fine-tuning(파인튜닝)은 암기 — 가중치에 지식을 내재화하는 방식인데, 이건 다음 글에서 다룬다. LLM 자체는 어느 쪽이든 똑같은 추론 엔진으로 동작한다.
RAG query ≠ Attention Q/K/V
| 흔히 가지는 직관 | 실제 |
|---|---|
| “검색된 문서가 LLM 내부의 Q 행렬에 들어간다” | ✗ — LLM 입장에선 그냥 입력 텍스트가 길어진 것. LLM은 이게 외부에서 검색됐는지 알지 못함 |
| “RAG의 query와 attention의 Q는 같다” | ✗ — RAG query = 벡터 DB 검색용 임베딩 (요청당 1개 벡터). Attention Q = 매 토큰·매 레이어·매 head마다 W_Q 곱해 만드는 임시 벡터 (수천 개) |
| “query 행렬에 토큰이 쌓인다” | △ — 정확히는 X(입력 임베딩 행렬)에 토큰이 쌓이고, Q = X @ W_Q이므로 Q, K, V 모두 row가 그만큼 늘어남 |
두 “query”는 어원부터 다르다. RAG의 query는 Information Retrieval(정보 검색) 분야의 용어로, 검색 엔진에 던지는 질의를 뜻한다. Transformer의 Q(Query)는 Vaswani et al. (2017)의 Attention 메커니즘에서 “이 토큰이 어디에 주목할지”를 계산하기 위한 학습된 projection 벡터다. 내적으로 유사도를 구한다는 수학적 구조만 닮았을 뿐, 완전히 다른 개념이다.
실습: Myntra 셔츠 카탈로그 RAG
책의 원본 노트북은 Colab Drive에서 Kaggle의 “Myntra Fashion Product Dataset”(~10,000행)을 불러온다. 하지만 RAG 파이프라인의 동작 흐름을 관찰하는 것이 학습 목표이므로, 진본 대신 같은 컬럼 스키마(ProductID, ProductName, Gender, Color, Fit, Occasion 등)로 mock 카탈로그 15행을 만들어 사용했다.
Mock 카탈로그 설계
책의 query가 Gender × Color × Fit × Occasion 4개 축을 조합하므로, 각 축의 값이 골고루 분포하도록 의도적으로 구성했다.
| 축 | 분포 |
|---|---|
| Gender | Men 11 · Women 4 |
| Fit | Regular 10 · Slim 5 |
| Occasion | Formal 7 · Casual 6 · Party 2 |
| Color | White / Blue / Sky Blue / Navy / Black / Grey / Pink / Red / Green / Olive Green / Burgundy / Beige 등 |
15행이라는 소규모 데이터지만, 임베딩 공간에서의 유사도 검색 동작을 확인하기엔 충분하다. 진본 데이터를 사용하고 싶다면 같은 컬럼 스키마의 CSV로 교체하면 동일 코드로 동작한다.
LangChain 1.x 마이그레이션
이전 글의 Agent 실습에서도 0.x → 1.x 마이그레이션을 다뤘다(ChatOpenAI import, set_debug, agent.invoke). RAG 실습에서는 추가로 CSVLoader, DocArrayInMemorySearch의 import 경로와 LLM 호출 방식이 달라진다.
| 원본 (0.x) | 수정 (1.x) | 이유 |
|---|---|---|
from langchain.document_loaders import CSVLoader |
from langchain_community.document_loaders import CSVLoader |
community 패키지로 이동 |
from langchain.vectorstores import DocArrayInMemorySearch |
from langchain_community.vectorstores import DocArrayInMemorySearch |
동일 |
llm.call_as_llm(...) |
llm.invoke(...) |
deprecated |
RAG 코드
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.document_loaders import CSVLoader
from langchain_community.vectorstores import DocArrayInMemorySearch
# 1. CSV → Document 로딩
loader = CSVLoader(file_path="data/processed_file.csv")
docs = loader.load()
# 2. Embedding + Vector Store (Storing + Indexing 한 줄)
embeddings = OpenAIEmbeddings()
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# 3. Similarity Search (Retrieval)
query = ("Shirts which are good for Men, have regular fit and not the slim fit "
"and can be used for a Formal occasions and have a color of either Blue or white")
results = db.similarity_search(query, k=5)
# 4. LLM 호출 (Final Interaction)
llm = ChatOpenAI(model="gpt-3.5-turbo")
docs_text = "\n".join([r.page_content for r in results])
response = llm.invoke(f"{docs_text}\n\nQuestion: {query}\nplease summarize results...")
실행 결과 요약
위 코드를 실행하면 embedding과 LLM 호출이 순서대로 일어난다. 전체 실행에 사용된 리소스를 정리하면 다음과 같다.
| 항목 | 값 |
|---|---|
| Embedding 모델 | text-embedding-ada-002 |
| Embedding 차원 | 1536 |
| LLM | gpt-3.5-turbo-0125 |
| LLM 호출 횟수 | 3회 |
| Token 합 | prompt 969 + completion 825 = 1,794 tokens |
| 비용 | ~$0.0018 |
15행짜리 카탈로그 RAG 전체 비용이 $0.002 이하다. RAG 파이프라인 자체의 비용은 미미하고, 프로덕션에서 비용이 커지는 건 문서 규모와 호출 빈도 때문이다.
similarity_search 결과 분석
RAG의 4단계(Retrieval)에 해당하는 db.similarity_search(query, k=5) 호출 결과를 보자. query는 “Men, Regular fit, Formal, Blue or White”를 요구하고 있다.
| Rank | ProductID | Name | Color | Fit | Occasion | 매치 여부 |
|---|---|---|---|---|---|---|
| 1 | 13 | Striped White Blue Regular Formal Shirt | White and Blue | Regular | Formal | ✓ |
| 2 | 12 | Sky Blue Regular Formal Shirt | Sky Blue | Regular | Formal | ✓ |
| 3 | 2 | Navy Blue Formal Shirt | Blue | Regular | Formal | ✓ |
| 4 | 11 | Beige Regular Fit Shirt | Beige | Regular | Casual | ✗ (Color·Occasion 어긋남) |
| 5 | 1 | Classic Oxford White Shirt | White | Regular | Formal | ✓ |
5개 중 4개는 query 조건과 정확히 일치한다. 그런데 4위에 #11 Beige Casual이 끼어들었다. Color는 Beige(Blue/White 아님), Occasion은 Casual(Formal 아님)인데 왜 상위에 올라왔을까?
임베딩 기반 검색은 SQL의 WHERE color IN ('Blue', 'White') AND occasion = 'Formal' 같은 논리적 AND 필터가 아니다. 텍스트 전체를 하나의 벡터로 변환한 뒤 cosine similarity를 계산하므로, “Men + Regular fit + shirt”라는 공통 패턴이 강하면 나머지 축의 차이를 상쇄할 수 있다. #11의 경우 Gender(Men)와 Fit(Regular)이 정확히 일치하고, “shirt”라는 공통 토큰이 1536차원 공간에서 query와 가깝게 만든 것이다.
이걸 눈으로 확인하기 위해 임베딩 공간을 시각화해 보자.
PCA 임베딩 시각화
15개 셔츠의 1536차원 임베딩을 PCA(Principal Component Analysis, 주성분 분석)로 2차원에 투영했다. 아래 그림에서 marker는 Gender(Men ●, Women ▲), 색상은 Occasion(Formal / Casual / Party)을 나타낸다.
PCA는 데이터의 공분산 행렬을 고윳값 분해해서 분산이 큰 축(주성분)을 찾는 방법이다. 이 과정은 데이터 행렬의 SVD(Singular Value Decomposition, 특잇값 분해)와 수학적으로 동치다. 데이터 행렬 X의 SVD에서 V의 열벡터가 곧 PCA의 주성분이고, 특잇값의 제곱이 고윳값(= 분산)에 비례한다. SVD에 대해서는 예전에 정리한 글을 참고하자.
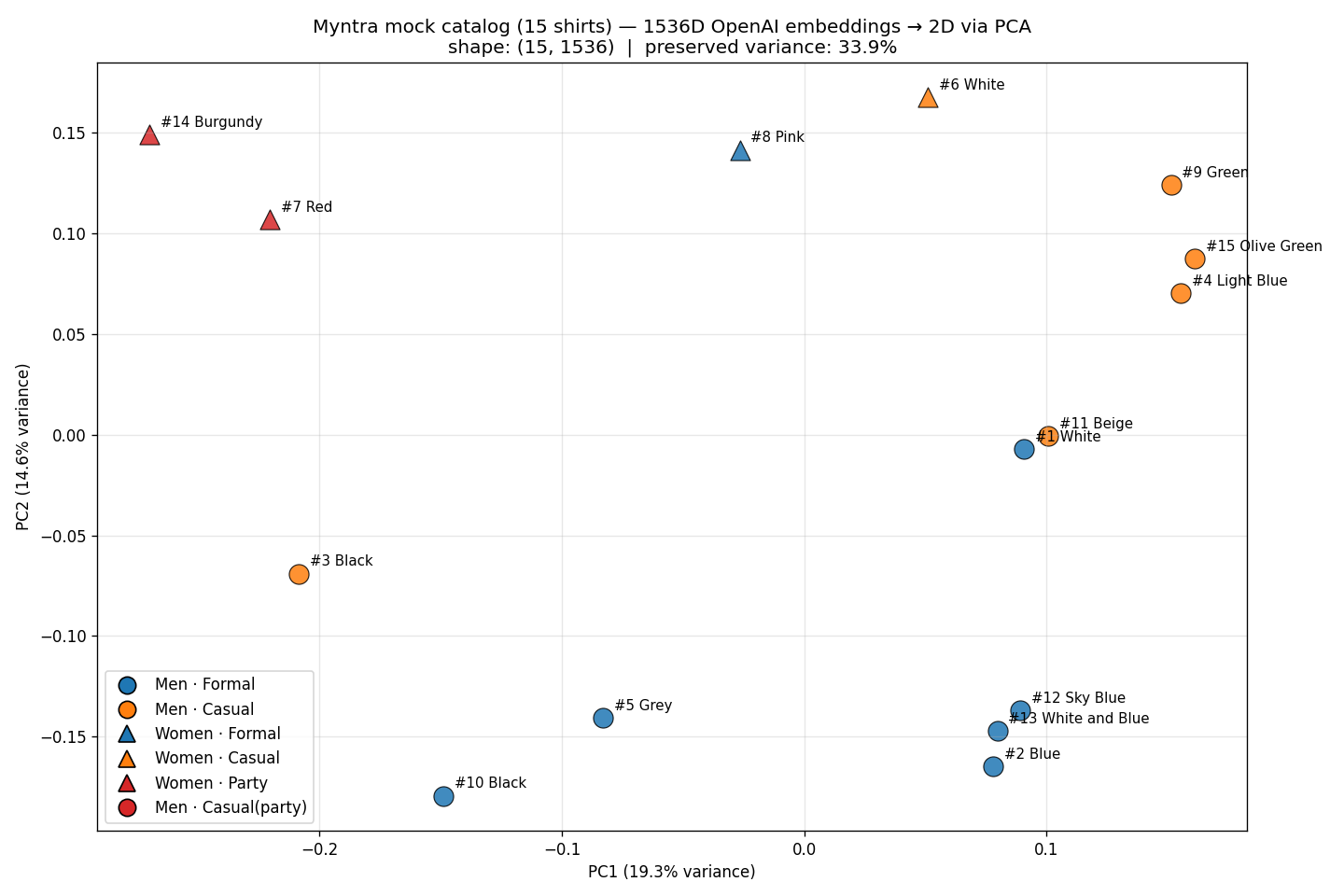
먼저 분산 보존율을 확인하자. PC1이 설명하는 분산은 19.3%, PC2는 14.6%로, 합계 33.9%만 보존되고 66.1%가 손실된다. 1536차원을 2차원으로 압축했으니 당연하다. 그래도 대략적인 클러스터 구조는 관찰할 수 있다.
| 위치 | 상품들 | 해석 |
|---|---|---|
| 우하단 클러스터 | #2 Navy, #12 Sky Blue, #13 White and Blue, #5 Grey | “Men + Regular + Formal + Blue 톤” — query가 원하는 바로 그 조합이다 |
| 거의 겹침 | #1 White, #11 Beige | “Men + Regular fit + shirt” 토큰 패턴이 비슷하여 Formal/Casual 차이에도 불구하고 가까이 위치 |
| 좌상단 분리 | #7 Red, #14 Burgundy | Women · Party 속성으로 query에서 가장 먼 별도 클러스터 형성 |
#1 White와 #11 Beige가 거의 겹쳐 있는 것이 핵심이다. 위의 similarity_search에서 #11이 4위로 올라온 이유가 여기서 시각적으로 확인된다. 두 상품은 Color와 Occasion이 다르지만, 나머지 속성(Men, Regular, shirt)이 동일해서 1536차원 공간에서 거의 같은 위치에 놓인다. cosine similarity는 이 전체 벡터 간 거리를 보므로, 개별 조건의 불일치를 잡아내지 못한다.
이 한계는 RAG 설계에서 중요한 시사점이다. top-K 검색 결과가 항상 정답은 아니며, 5단계(Final Interaction)에서 LLM이 검색 결과를 사후 필터링하는 역할을 해야 한다. 실제로 아래 LLM 호출에서 LLM이 #11 Beige를 자동으로 제외하는 것을 확인할 수 있다.
PCA 시각화 재현 코드
import os, pandas as pd, numpy as np, matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from langchain_openai import OpenAIEmbeddings
df = pd.read_csv("week02/hands-on/ch04/data/myntra_products_catalog.csv")
texts = ["\n".join(f"{c}: {row[c]}" for c in df.columns) for _, row in df.iterrows()]
emb = OpenAIEmbeddings()
vecs = np.array(emb.embed_documents(texts)) # (15, 1536)
proj = PCA(n_components=2).fit_transform(vecs)
# Gender → marker, Occasion → color 인코딩
gender_markers = {"Men": "o", "Women": "s"}
occasion_colors = {"Formal": "blue", "Casual": "green", "Party": "red"}
fig, ax = plt.subplots(figsize=(10, 8))
for i, row in df.iterrows():
ax.scatter(
proj[i, 0], proj[i, 1],
marker=gender_markers.get(row["Gender"], "o"),
color=occasion_colors.get(row["Occasion"], "gray"),
s=100
)
ax.annotate(f"#{row['ProductID']}", (proj[i, 0], proj[i, 1]), fontsize=8)
ax.set_xlabel("PC1 (19.3%)")
ax.set_ylabel("PC2 (14.6%)")
ax.set_title("PCA 2D Projection of 15 Shirt Embeddings")
plt.tight_layout()
plt.savefig("pca_embeddings.png", dpi=150)
plt.show()
3가지 LLM 호출 패턴
RAG의 5단계(Final Interaction)에서 retrieved docs를 prompt에 넣고 LLM을 호출한다. 동일한 top-5 docs에 대해 prompt만 달리하여 3가지 패턴으로 호출했다. Retrieval 결과는 세 호출 모두 동일하다는 점을 기억하자.
호출 #1: 영어 기본 질의
검색된 5개 문서를 prompt에 join하고 요약을 요청했다. LLM 응답 발췌:
| ProductID | Product Name | Color | Occasion | Fit |
|-----------|-----------------------------------------|------------|----------|---------|
| 13 | Striped White Blue Regular Formal Shirt | White/Blue | Formal | Regular |
| 12 | Sky Blue Regular Formal Shirt | Sky Blue | Formal | Regular |
| 2 | Navy Blue Formal Shirt | Blue | Formal | Regular |
| 1 | Classic Oxford White Shirt | White | Formal | Regular |
...
Recommendation: ... the Striped White Blue Regular Formal Shirt (ProductID: 13)
would be a great choice.
LLM이 ProductID 11(Beige Casual)을 표에서 자동으로 제외했다. retrieved docs에는 포함되어 있었지만, LLM이 query의 제약(“Blue or White”, “Formal”)을 다시 읽고 부적합한 후보를 걸러낸 것이다. RAG는 “검색만”이 아니라 “검색 + LLM의 추론” 조합이다.
- Token: prompt 309 / completion 283
호출 #2: 프랑스어 응답 요청
같은 5개 docs를 그대로 보내되 “respond in French”만 추가했다. LLM 응답 발췌:
La chemise recommandée serait la "Chemise Oxford Blanche Classique" (Produit 1) ...
같은 retrieved docs인데 추천이 ProductID 13 → 1로 바뀌었다. Retrieval 단계는 결정론적(deterministic)이다. 같은 query, 같은 vector DB이므로 항상 같은 top-5가 나온다. 그러나 LLM 단계는 비결정론적(non-deterministic)이라, prompt 표현(언어·강조점)에 따라 최종 추천이 달라진다. retrieved docs가 deterministic하다고 응답이 deterministic한 건 아니다.
- Token: prompt 315 / completion 368
호출 #3: 페르소나 추가
같은 5개 docs에 두 인물의 인구통계 정보를 prompt에 추가했다.
demographics = {
"John": {'Age': 30, 'Education': "Bachelor's in CS", 'Occupation': "Software Engineer"},
"Adam": {'Age': 60, 'Occupation': "Retired"}
}
LLM 응답 발췌:
For John, the Software Engineer:
Recommendation: ProductID 2 - Navy Blue Formal Shirt
Reasoning: ... working in a formal office setting ...
For Adam, the Retired individual:
Recommendation: ProductID 1 - Classic Oxford White Shirt
Reasoning: ... may still attend formal events ... timeless and classic ...
같은 5개 docs로 두 사람에게 다른 셔츠를 추천한다. RAG의 가치는 단순 “정답 검색”이 아니라, 검색된 정보 + 추가 context(여기서는 페르소나)를 묶어 추론하는 데 있다.
- Token: prompt 345 / completion 174
Incremental Context 패턴 정리
세 호출을 나란히 놓으면 점층적으로 context가 추가되는 구조다.
| 호출 | retrieved docs | 추가 context | LLM 추천 | 달라진 것 |
|---|---|---|---|---|
| #1 | top-5 (동일) | 없음 | ProductID 13 | — |
| #2 | top-5 (동일) | “respond in French” | ProductID 1 | 표현 언어 |
| #3 | top-5 (동일) | 페르소나 (John/Adam) | ProductID 2 / 1 | 대상 도메인 context |
Retrieval 결과는 세 번 모두 동일하다. prompt에 어떤 context를 추가하느냐에 따라 LLM의 최종 추론이 달라진다. 이것이 RAG의 유연성이다 — 모델 가중치를 건드리지 않고도, prompt 조립만으로 응답의 언어·톤·대상을 제어할 수 있다.
RAG vs no-RAG: hallucination 비교
동일한 query를 RAG 없이 LLM에 직접 던지면 어떻게 되는가.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
query = ("Shirts which are good for Men, have regular fit and not the slim fit "
"and can be used for a Formal occasions and have a color of either Blue or white "
"please summarize results in a nice summary table...")
r = llm.invoke(query)
print(r.content)
카탈로그 데이터 없이 LLM이 내놓은 응답은 다음과 같다.
| Shirt Type | Fit | Occasion | Color |
|------------|---------|----------|-------|
| Shirt A | Regular | Formal | Blue |
| Shirt B | Regular | Formal | White |
Shirt A is a regular fit shirt in blue color, suitable for formal occasions.
Shirt B is a regular fit shirt in white color, suitable for formal occasions.
I recommend Shirt A in blue color as it is a versatile option...
그럴듯한 표 형식을 갖추고 있지만, “Shirt A”, “Shirt B”는 실존하지 않는 가상의 셔츠다. ProductID도 없고, 브랜드도 없다. RAG가 있을 때 LLM은 실제 카탈로그의 ProductID 13(Striped White Blue)을 추천했지만, 없으면 이렇게 그럴듯한 거짓말을 만들어낸다. 이것이 hallucination(환각)이다.
Hallucination이 발생하는 원리
왜 LLM은 “모르겠습니다”라고 하지 않고 가짜 셔츠를 만들어낼까? 세 가지 구조적 이유가 있다.
- 사전학습 목표 자체가 진실 추구가 아니다. LLM의 학습 목표는 “next token probability 최대화”다. 주어진 맥락에서 가장 자연스러운 다음 토큰을 고르도록 훈련된 것이지, 사실 여부를 검증하도록 훈련된 게 아니다.
- “모르겠습니다”도 하나의 token sequence다. 학습 데이터에서 질문에 대해 “모른다”고 답하는 패턴이 적으면, 그 토큰 시퀀스의 생성 확률이 낮다. 대신 “그럴듯한 답변” 패턴이 훨씬 많이 학습되어 있으므로 그쪽으로 생성이 기운다.
temperature=0이어도 발생한다. 결정론적 디코딩은 “가장 확률 높은 토큰을 고른다”는 뜻이지, “가장 사실에 가까운 토큰을 고른다”는 뜻이 아니다. 확률 분포 자체가 거짓 정보를 높게 매기고 있으면 temperature를 아무리 낮춰도 소용없다.
temperature는 LLM 추론(inference) 시 토큰 선택의 무작위성을 제어하는 디코딩 파라미터다. 모델 학습(training)용이 아니라 응답 생성 시 사용한다. 값이 높을수록(예: 1.0) 다양하고 창의적인 응답이 나오고, 낮을수록(예: 0) 가장 확률 높은 토큰만 선택하여 일관된 응답이 나온다. 비슷한 역할을 하는 디코딩 파라미터로top_p(누적 확률 기준 후보 제한)와top_k(상위 k개 토큰만 후보로 제한) 등이 있다. 위 코드에서temperature=0으로 설정한 이유는 “가장 결정론적인 조건에서도 hallucination이 발생한다”는 걸 보이기 위함이다.
RAG가 hallucination을 줄이는 방식과 한계
RAG는 이 문제를 prompt 수준에서 완화한다. 사실 토큰을 prompt에 미리 깔아 놓으면, LLM이 next token을 고를 때 그 사실 토큰의 영향을 받아 정확한 방향으로 생성될 확률이 높아진다. 하지만 완전한 해결은 아니다.
| RAG가 줄이는 방식 | 여전히 남는 한계 |
|---|---|
| 사실 토큰을 prompt에 깔아 놓음 → next token 확률에서 사실 쪽으로 유도 | 검색된 docs 자체가 잘못된 정보면 그것도 그대로 출력 |
| 사전학습에 없던 도메인 데이터를 실시간 주입 | top-K 검색 정확도에 의존 — 관련 없는 docs가 올라오면 무의미 |
| knowledge cut-off 이후 데이터도 활용 가능 | LLM이 retrieved docs를 무시하고 자체 생성할 수도 있음 |
비유하자면, “오늘 서울 날씨가 어때?”라고 물었을 때 기상청 예보 데이터를 함께 건네주면(RAG) “맑고 25°C”라고 답하지만, 아무것도 없이 물으면 “비가 옵니다”라고 그럴듯한 거짓말을 한다. RAG는 LLM에게 참고 자료를 건네주는 것이다. 참고 자료의 품질이 곧 응답의 품질 상한선이 된다.
RAG의 가치 정리
RAG는 두 가지를 동시에 달성한다:
- Contextuality(맥락성): 사전학습에 없는 도메인 데이터를 실시간으로 주입
- Factual Accuracy(사실 정확도): hallucination 확률 감소
다만 완전한 해결책은 아니다:
- 검색 정확도: embedding 모델의 품질과 chunking(문서 분할) 전략에 따라 엉뚱한 문서가 top-K에 올 수 있다 (Beige 셔츠 사례)
- 문서 신뢰도: 저장된 문서 자체가 틀리면 RAG도 틀린 답을 낸다
- LLM의 docs 의존도: LLM이 retrieved docs를 무시하고 자체 지식으로 답할 수 있다
이 변수들을 관리하는 것이 프로덕션 RAG 시스템의 핵심 과제다.
참고 링크
- LangChain Docs — Vector Stores
- OpenAI Embeddings Guide
- DocArray Documentation
- Packt — Kubernetes for Generative AI Solutions (GitHub)

댓글남기기