
[Kubernetes] NVIDIA Device Plugin 동작 원리
Kubernetes 환경에서 GPU를 사용하는 방법을 알아본 뒤, 그렇다면 NVIDIA Device Plugin이 어떻게 동작하여 컨테이너에서 GPU를 사용할 수 있는 것인지 공부한 내용을 작성한다.
개요
크게 두 가지의 관점에서 이해하면 좋다. NVIDIA Device Plugin이 쿠버네티스 환경에서 GPU를 인식할 수 있게 해 준다고 했기 때문에, 어떻게 인식할 수 있는 건지(이하 보고라고 하겠다), 인식한 GPU 노드에 어떻게 파드가 스케줄링되어 실행되는지(이하 스케줄링이라고 하겠다)이다.
큰 구조는 아래와 같다. GPU를 사용하기 위해, 아래와 같이 계층 별로 책임이 잘 분리되어 있다.
┌──────────────┐
│ Scheduler │ "어느 노드에 배치할까?" (정책 결정)
└──────┬───────┘
│ Pod.spec.nodeName = "worker-1"
↓
┌──────────────┐
│ Kubelet │ "이 노드에서 어떻게 실행할까?" (실행 조율)
│ (worker-1) │ - Device Plugin에게 물어보기
└──────┬───────┘ - Container Runtime에게 전달하기
│
├─────→ ┌─────────────────┐
│ │ Device Plugin │ "어떤 GPU를 줄까?" (리소스 할당)
│ └─────────────────┘
│
└─────→ ┌─────────────────┐
│Container Runtime│ "어떻게 격리할까?" (실행)
└─────────────────┘
- Scheduler (kube-scheduler): 어느 노드에 배치할지 결정
- 모든 리소스를 동일하게 취급
- 각각의 리소스를 고려했을 때, 파드를 어느 노드에 배치할지가 관심사
- Kubelet: 파드 실행 관리
- 노드별 에이전트
- Device Plugin과 Container Runtime 사이 중개자 역할
- Device Plugin에 물어봐서, Container Runtime에 실행 요청
- NVIDIA Device Plugin: 어떤 장치를 할당할지 결정
- 노드 GPU 세부사항 관리
- Kubelet에게 파드 실행 시 어떤 GPU를 사용하라고 알려 줌
- Container Runtime: 실제 컨테이너 실행
보고
NVIDIA Device Plugin DaemonSet(모든 노드 혹은 특정 노드에 파드를 하나씩 배포하는 컨트롤러)이 배포되어 있는 클러스터라면, GPU 노드에 라벨링했을 때, 각 노드에 NVIDIA Device Plugin이 배포된다고 했다. 이후, 노드의 GPU 상태가 아래와 같이 관리된다.
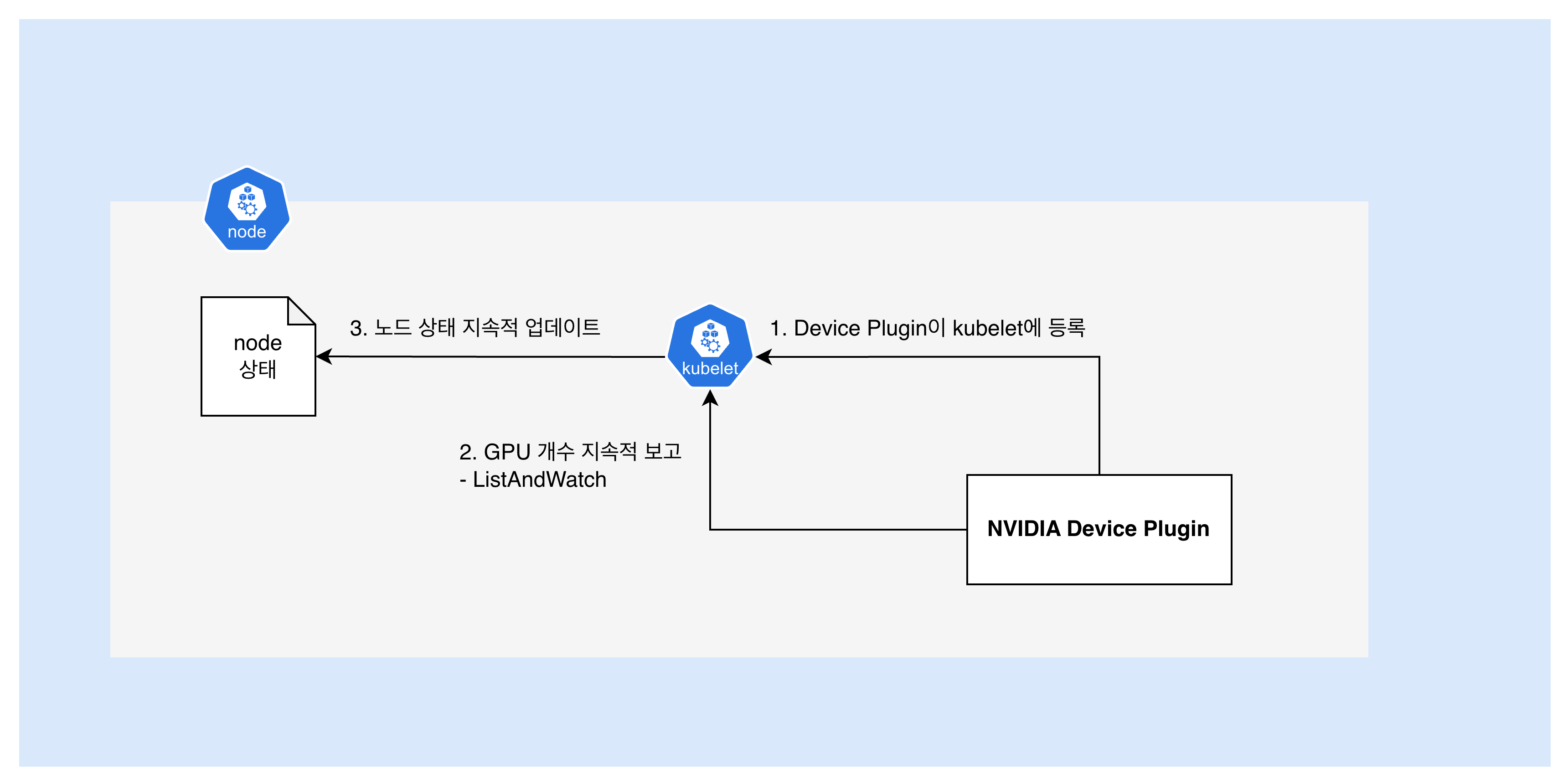
- NVIDIA Device Plugin Pod 시작
- 노드에 배포된 DaemonSet Pod가 자동 시작
/var/lib/kubelet/device-plugins/디렉토리에 자신의 Unix domain socket 파일(예:nvidia-gpu.sock)을 생성한다. 이 소켓이 이후 kubelet ↔ Device Plugin 간 모든 gRPC(Google Remote Procedure Call) 통신의 채널이 된다.
- Device Plugin → Kubelet 등록 (Register)
- 같은 디렉토리의
kubelet.sock에 연결하여RegisterRPC를 호출한다 nvidia.com/gpu 리소스를 관리하겠습니다선언하는 셈이다- 등록이 완료되면 kubelet이 역으로 Device Plugin의 소켓(
nvidia-gpu.sock)에 연결한다
- 같은 디렉토리의
- Device Plugin → Kubelet GPU 개수 보고 (ListAndWatch, 지속적)
- kubelet이 Device Plugin 소켓을 통해 ListAndWatch RPC를 호출한다
- Device Plugin은 NVML(NVIDIA Management Library)로 GPU를 스캔하고, 발견한 GPU 개수를 gRPC stream으로 지속 보고한다
- Device Plugin Pod가 삭제되면 gRPC 연결이 끊기고, kubelet은 소켓 감시 메커니즘(
fsnotify)을 통해 이를 감지하여 해당 리소스의 광고를 중단한다
- Kubelet은 노드 상태에 GPU 자원을 지속적으로 반영하여 업데이트함
- GPU 상태 변경 시 즉시 업데이트
이렇게 보고된 GPU 자원을 노드 상태를 통해 확인할 수 있게 되는 것이다.
apiVersion: v1
kind: Node
metadata:
name: worker-1
status:
capacity:
nvidia.com/gpu: "8" # Device Plugin이 보고한 값
cpu: "16"
memory: "64Gi"
allocatable:
nvidia.com/gpu: "8"
스케줄링
그렇다면 사용자가 GPU 파드 생성을 요청했을 때는 어떤 일이 발생할까.
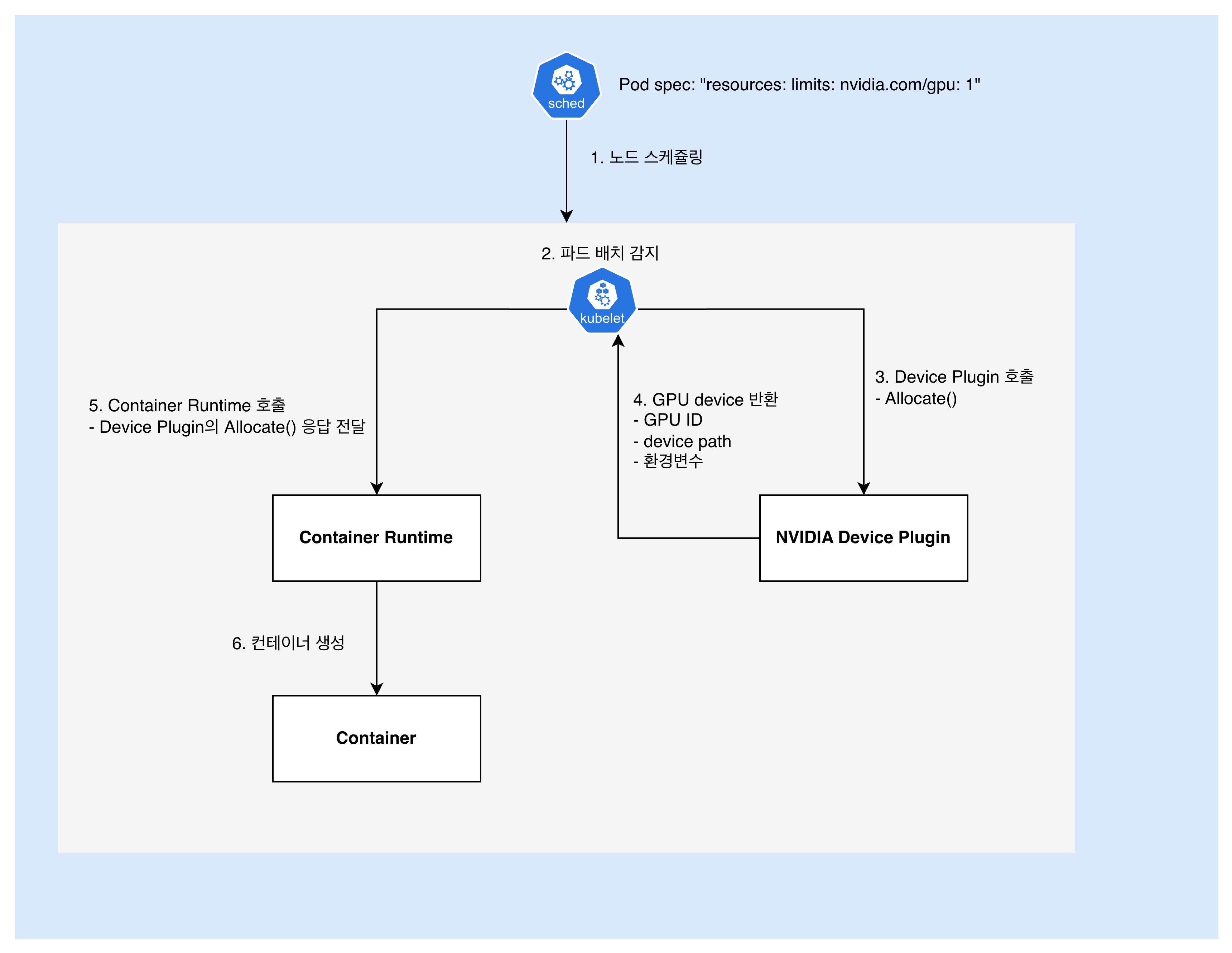
- 사용자:
nvidia.com/gpu: 1파드 생성 요청 - Scheduler: 노드 스케줄링
- 위 보고 단계에서 노드 상태가 계속해서 보고되고 있음
- 이렇게 보고된 노드 상태를 바탕으로, 가용
nvidia.com/gpu자원을 확인해 적절한 노드에 배치
- Kubelet: 파드 배치 감지
아, 내 노드에 파드가 배치되었구나. 컨테이너 생성을 시작해야지!
- Kubelet: NVIDIA GPU Device Plugin에게 GPU 할당 요청
이 pod에 nvidia.com/gpu 자원이 1개 필요해. 어떤 GPU를 사용하면 돼?
- NVIDIA Device Plugin: GPU 할당 결과 응답 반환
GPU-<uuid>를 할당해줄게. /dev/nvidia0 경로에 있어. 환경 변수는 이렇게 설정해- GPU ID: GPU-abc123…
- Device Path: /dev/nvidia0, /dev/nvidiactl, /dev/nvidia-uvm
- 환경변수: NVIDIA_VISIBLE_DEVICES=GPU-abc123
- 마운트: CUDA 라이브러리 경로들
- Kubelet: Container Runtime에
4에서 받은 응답과 함께 컨테이너 실행 요청- Kubelet은 NVIDIA Device Plugin의 응답을 신뢰. 받은 것을 그대로 전달
- Container Runtime에, 예컨대 아래와 같은 정보를 주입
{ "Devices": [ { "Path": "/dev/nvidia0", "Type": "c", "Major": 195, "Minor": 0 } ], "Mounts": [ "/usr/local/nvidia/lib64" ], "Env": [ "NVIDIA_VISIBLE_DEVICES=GPU-abc123..." ] }
- Container Runtime: 컨테이너 실행
참고:
NVIDIA_VISIBLE_DEVICES와CUDA_VISIBLE_DEVICES(OCI Hook 방식)OCI Runtime Hook 방식에서 이 두 환경 변수는 설정 주체와 동작 레벨이 다르다.
NVIDIA_VISIBLE_DEVICES: NVIDIA Device Plugin이AllocateRPC 응답에서 GPU UUID로 설정한다. 컨테이너 런타임 레벨에서 어떤 GPU를 컨테이너에 노출할지 결정하는 변수로, NVIDIA Container Runtime Hook(nvidia-container-runtime-hook)이 이 값을 읽고 실제 GPU 장치를 컨테이너에 마운트한다.CUDA_VISIBLE_DEVICES: Device Plugin이 아니라 NVIDIA Container Runtime Hook이 컨테이너 시작 시점에 설정한다. CUDA 런타임 레벨에서 애플리케이션이 볼 수 있는 GPU를 제어하는 변수다.즉, Device Plugin의
Allocate응답에는NVIDIA_VISIBLE_DEVICES만 포함되며,CUDA_VISIBLE_DEVICES는 컨테이너 실행 과정에서 NVIDIA Container Runtime이 자동으로 설정한다.
Container Runtime의 GPU 처리
이 섹션은 OCI Runtime Hook 방식 기준으로 설명한다. GPU Operator v25.10.0 이후부터는 CDI(Container Device Interface)가 기본값으로 전환되어, containerd가 CDI 스펙을 직접 읽어 디바이스를 주입하는 방식으로 동작한다. CDI 방식에서는 아래의
nvidia-container-runtime-hook흐름이 적용되지 않는다.
NVIDIA Container Runtime에 대해 알아본 결과를 바탕으로, OCI Hook 방식에서 위의 5와 6 사이에 어떤 일이 일어나는지 조금 더 자세히 살펴보자.
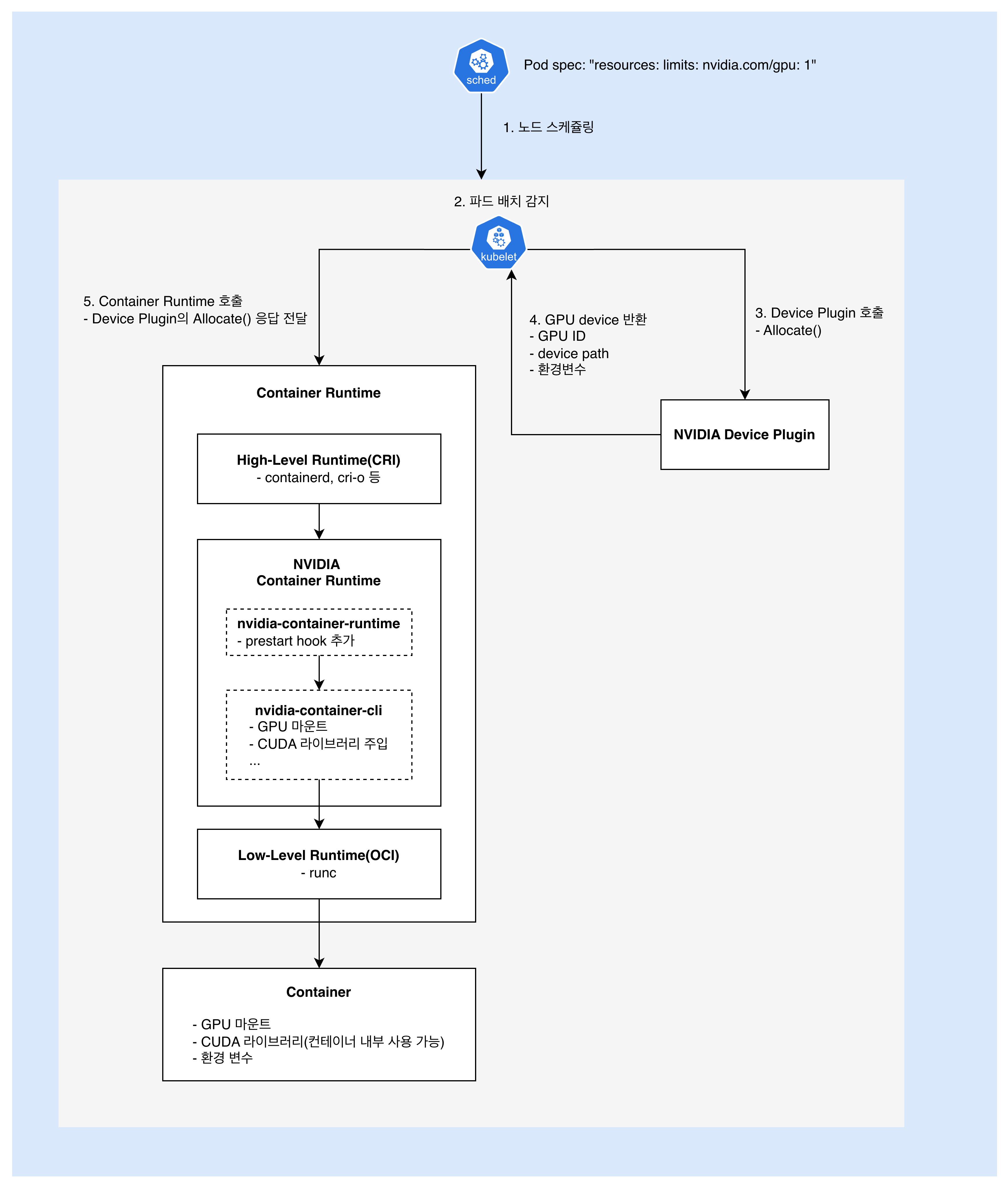
- Kubelet: CRI를 통해 High-Level Container Runtime(containerd 등)에 컨테이너 생성 요청
- High-Level Container Runtime: OCI Runtime으로 등록된 NVIDIA Container Runtime(
nvidia-container-runtime) 호출 - NVIDIA Container Runtime: OCI 스펙(
config.json)에 GPU 관련 정보 주입nvidia-container-runtime-hook(prestart hook) 실행- Device Plugin이 설정한
NVIDIA_VISIBLE_DEVICES값을 읽어 대상 GPU 결정 - GPU 장치 파일(
/dev/nvidia0,/dev/nvidiactl등) 추가 - CUDA 라이브러리, NVIDIA driver 파일 마운트 설정
CUDA_VISIBLE_DEVICES등 CUDA 런타임용 환경 변수 설정
- NVIDIA Container Runtime: 수정된 OCI 스펙으로
runc(Low-Level Container Runtime) 호출 runc: OCI 스펙을 읽고 Linux namespace, cgroup 등을 설정하여 실제 컨테이너 프로세스 생성
여기서 핵심은, NVIDIA Container Runtime과 runc의 역할이 명확히 분리되어 있다는 점이다.
- NVIDIA Container Runtime: runc의 wrapper로서, GPU를 컨테이너에서 사용할 수 있도록 OCI 스펙을 수정하는 역할. 컨테이너 자체를 생성하지는 않는다.
- runc: 수정된 OCI 스펙을 받아 Linux namespace, cgroup 등 저수준 격리 환경을 설정하고, 실제 컨테이너 프로세스를 생성하는 역할.
NVIDIA Container Runtime의 내부 동작 구조에 대한 상세한 내용은 NVIDIA Container Runtime 글을 참고하자.
Extended Resource로서의 GPU
지금까지 Device Plugin이 GPU를 보고하고, 스케줄러가 배치하고, kubelet이 할당하는 흐름을 살펴보았다. 이 흐름을 이해했다면, 한 가지 더 짚고 넘어갈 것이 있다. nvidia.com/gpu는 쿠버네티스 코어 리소스(cpu, memory)가 아니라, Device Plugin이 광고하는 Extended Resource다. Extended Resource에는 코어 리소스와 다른 강제 규칙이 있고, GPU를 다루려면 이 규칙을 알아야 한다.
코어 리소스와의 차이
cpu와 memory는 쿠버네티스가 태생적으로 알고 있는 리소스다. kubelet이 직접 노드의 CPU 코어 수와 메모리 용량을 측정하여 보고한다. 반면 nvidia.com/gpu 같은 Extended Resource는 kubernetes.io 도메인 바깥의 이름을 쓰며, Device Plugin(또는 API 패치)을 통해 외부에서 광고된다. 쿠버네티스 입장에서는 “이 노드에 nvidia.com/gpu라는 것이 몇 개 있다”만 알 뿐, 그것이 물리적으로 무엇인지는 모른다.
이 설계 차이 때문에 Extended Resource에는 코어 리소스에 없는 세 가지 강제 규칙이 적용된다.
규칙 1: 정수만 허용
Extended Resource는 정수 단위로만 요청할 수 있다. nvidia.com/gpu: 0.5 같은 소수 요청은 API 서버가 거부한다.
# 유효
resources:
limits:
nvidia.com/gpu: 1
# 무효 — API 서버가 거부
resources:
limits:
nvidia.com/gpu: 0.5
코어 리소스인 cpu는 밀리코어 단위(500m = 0.5 코어)까지 쪼갤 수 있지만, Extended Resource는 “N개의 이산적인 장치”를 나타내는 설계이므로 정수만 허용된다.
규칙 2: request == limit 강제 (overcommit 불가)
Extended Resource는 overcommit이 불가능하다. requests와 limits를 둘 다 명시하면 반드시 같아야 한다.
# 유효 — 둘 다 같은 값
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
# 무효 — API 서버가 거부
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 2
CPU의 경우 requests: 500m, limits: 2000m처럼 설정하여 여유가 있으면 burst할 수 있지만, GPU에서는 “1개 여유면 1개, 2개 여유면 2개” 같은 동적 할당이 존재하지 않는다. 왜 이런 차이가 나는지 — compressible/incompressible 리소스의 본질적 차이 — 는 GPU Sharing: Time Slicing - 1. 개념에서 더 자세히 다룬다.
규칙 3: limits 필수
Extended Resource는 반드시 limits에 지정해야 한다. requests만 단독으로 지정하는 것은 허용되지 않는다.
| 지정 방식 | 유효 여부 | 동작 |
|---|---|---|
limits만 지정 |
O | requests가 limits와 동일값으로 자동 채워짐 |
limits + requests (동일값) |
O | 명시적으로 같은 값 |
requests만 지정 |
X | API 서버 거부 |
실무에서는 첫 번째 패턴이 가장 일반적이다. limits만 쓰면 requests는 자동으로 같은 값이 된다.
resources:
limits:
nvidia.com/gpu: 1 # requests도 자동으로 1
세 규칙의 배경
세 규칙을 관통하는 설계 의도는 명확하다. GPU 디바이스는 커널 스케줄러가 매 순간 시간을 잘게 쪼개 나눠줄 수 있는 CPU와 달리, Device Plugin이 “N개의 이산적인 장치”로 광고하고, kubelet이 특정 디바이스 ID를 컨테이너에 핀(NVIDIA_VISIBLE_DEVICES)으로 박아넣어 Pod 수명 동안 독점시키는 구조다. 기본적으로 커널 레벨의 선점형 시분할이 없으므로, 소수 요청·overcommit·burst 같은 개념이 성립할 자리가 없다.
그래서 “분수 GPU”가 필요하면, request/limit 의미론을 바꾸는 것이 아니라, GPU 공유 메커니즘(Time Slicing, MPS, MIG)을 통해 Device Plugin이 광고하는 단위 자체를 바꾸는 별개 메커니즘을 사용해야 한다.
API 서버의 검증 로직: non-overcommitable resource
위 규칙들은 NVIDIA Device Plugin이 아니라 kube-apiserver의 Pod spec validation 코드 자체에 하드코딩되어 있다. pkg/apis/core/validation/validation.go의 ValidateContainerResourceRequirements 함수가 Pod 생성/수정 시 검증한다.
overcommit 가능 여부를 결정하는 것은 helper.IsOvercommitAllowed 함수다.
func IsOvercommitAllowed(name core.ResourceName) bool {
return IsNativeResource(name) && !IsHugePageResourceName(name)
}
overcommit이 허용되는 건 native resource(kubernetes.io 도메인 또는 도메인 없는 리소스)이면서 hugepages가 아닌 것뿐이다. 즉 GPU만이 아니라, kubernetes.io 도메인 바깥의 모든 extended resource와 hugepages가 non-overcommitable이다. 목록이 미리 정의된 것이 아니라, “native이면서 hugepages가 아닌 것만 허용”이라는 배제 로직이다.
| 분류 | 예시 | overcommit |
|---|---|---|
| native, hugepages 아님 | cpu, memory, ephemeral-storage |
허용 |
| native, hugepages | hugepages-2Mi, hugepages-1Gi |
불가 |
| extended resource (전부) | nvidia.com/gpu, amd.com/gpu, FPGA, 커스텀 NIC 등 |
불가 |
이 함수를 호출하는 검증 로직은 두 곳이다.
// request != limit이면 거부
if quantity.Cmp(limitQuantity) != 0 && !helper.IsOvercommitAllowed(resourceName) {
allErrs = append(allErrs, field.Invalid(reqPath, quantity.String(),
fmt.Sprintf("must be equal to %s limit of %s", resourceName, limitQuantity.String())))
}
// requests만 있고 limits가 없으면 거부
} else if !helper.IsOvercommitAllowed(resourceName) {
allErrs = append(allErrs, field.Required(limPath,
"Limit must be set for non overcommitable resources"))
}
NVIDIA든 AMD든 커스텀 FPGA든, kubernetes.io 도메인 바깥의 리소스 이름을 쓰는 순간 이 검증에 걸린다. Device Plugin이나 벤더와 무관한, K8s 코어의 extended resource 공통 규칙이다.
결론
위와 같은 단계를 거쳐, 최종적으로 쿠버네티스 환경에서 컨테이너가 GPU를 사용할 수 있게 된다. 알고 보면, 그 속에 숨어 있는 추상화 레벨과 책임 분리가, 놀라운 수준이다.
또한, 이 글에서 다룬 Device Plugin의 Allocate 방식 외에도, CDI(Container Device Interface)라는 표준화된 장치 주입 방식이 등장하고 있다. 최신 NVIDIA Device Plugin(v0.14+)은 CDI를 지원하며, 컨테이너 런타임이 CDI 스펙을 직접 읽어 디바이스를 주입하는 방식으로 기존 OCI Runtime Hook 방식을 대체할 수 있다.


댓글남기기