
[EKS] EKS GPU 트러블슈팅: 1. 실습 사전 준비 - EC2 Service Quota 증설
정영준님의 AWS EKS Workshop Study(AEWS) 5주차 학습 내용을 기반으로 합니다.
TL;DR
- AWS는 EC2 On-Demand 인스턴스의 동시 실행 한도를 인스턴스 패밀리 그룹별로 관리한다
- 서울 리전 신규 계정에서 G/VT 쿼터 기본값은 0인 경우가 많다. 쿼터가 0이면 돈을 지불할 의사가 있어도 GPU 인스턴스를 띄울 수 없다
- 16 vCPU 요청 → 8 vCPU 부분 승인. Option B(g5.xlarge × 2 = 8 vCPU) 정상 실습은 가능하나 롤링 교체 등에서 여유가 없으므로, ASG 최대 노드 수를 2로 제한하는 것을 권장한다
EC2 Service Quota와 인스턴스 패밀리
AWS는 EC2 On-Demand 인스턴스의 동시 실행 한도를 인스턴스 패밀리 그룹별로 분리하여 관리한다. 주요 그룹은 다음과 같다.
| 쿼터 이름 | 대상 패밀리 | 용도 | 신규 계정 기본값 |
|---|---|---|---|
| Running On-Demand Standard (A,C,D,H,I,M,R,T,Z) | t3, m5, c5, r6i 등 범용/컴퓨팅/메모리 | 일반 워크로드 | 5~32 vCPU |
| Running On-Demand G and VT | g4dn, g5, g6, vt1 등 | GPU(추론/학습), 비디오 트랜스코딩 | 0 (신규 계정 다수) |
| Running On-Demand P | p3, p4d, p5 등 | 고성능 GPU(대규모 학습) | 0 |
| Running On-Demand F | f1 등 | FPGA | 0 |
- G 패밀리: NVIDIA GPU 탑재 인스턴스. g5는 A10G GPU, g4dn은 T4 GPU를 사용하며 ML 추론·학습·그래픽 렌더링 용도다
- VT 패밀리: 비디오 트랜스코딩 전용 인스턴스(Xilinx FPGA 기반). G와 묶여 같은 쿼터를 공유한다
G/VT 쿼터가 기본 0인 이유
Standard 계열(t3, m5 등)은 가격이 낮고 공급이 넉넉하여 신규 계정에도 기본 한도를 부여한다. 반면 G/VT, P, F 계열은 사정이 다르다.
- 인스턴스 단가가 높다 — g5.xlarge 시간당 ~$1.0 (서울). 결제 이력이 없는 계정에 열어두면 사기·남용 리스크가 있다
- GPU 물리 공급이 제한적이다 — 리전별로 GPU 서버 수량이 한정되어 있어 AWS가 보수적으로 할당한다
- 서울 리전 특성 — us-east-1/us-west-2 같은 대형 리전은 신규 계정에도 소량(4~8 vCPU)을 여는 경우가 있지만, 서울은 GPU 수요 대비 공급이 타이트하여 기본 0이 흔하다
쿼터가 0이면 돈을 지불할 의사가 있어도 API 레벨에서 인스턴스 생성이 거부된다. 프리 티어(Free Tier, 과금 면제 혜택)와는 별개로, “물리적으로 띄울 수 있느냐”의 문제다.
이 실습에서 증설이 필요한 이유
이 실습(AEWS 5주차)은 EKS 위에서 GPU 노드를 운용하며 트러블슈팅 시나리오를 재현하는 것이 목적이므로, g5.xlarge 인스턴스가 반드시 필요하다. 쿼터가 0인 채로는 Terraform이 GPU 노드 그룹의 ASG(Auto Scaling Group)를 생성해도 인스턴스가 런칭되지 않는다.
실전 팁: 신규 계정에서 G 계열 쿼터는 기본 0이다. 확인 후 계정 쿼터 상태가 0이라면, 실습 전에 미리 신청하는 것을 권장한다. 증설 신청이 비교적 빠르게 처리될 수 있다.
쿼터 확인
실습 환경을 구성하기 전에, 현재 계정의 쿼터 상태를 확인한다.
AWS 계정 확인
먼저 어떤 AWS 계정/사용자로 실습을 진행하는지 확정한다. 잘못된 프로필로 apply가 걸리는 것을 방지하기 위함이다.
aws sts get-caller-identity --output table
-----------------------------------------------------
| GetCallerIdentity |
+---------+-----------------------------------------+
| Account| 123456789012 |
| Arn | arn:aws:iam::123456789012:user/my-user |
| UserId | AIDAEXAMPLEUSERID1234 |
+---------+-----------------------------------------+
실습 대상 계정과 IAM 사용자가 맞는지 확인한다.
G/VT On-Demand vCPU 쿼터 확인
g5.xlarge × 2(총 8 vCPU)를 구동할 수 있는지 판단하기 위해 G/VT 쿼터를 확인한다. L-DB2E81BA는 “Running On-Demand G and VT instances” 쿼터 코드다.
aws service-quotas get-service-quota \
--service-code ec2 \
--quota-code L-DB2E81BA \
--region ap-northeast-2 \
--output table
전체 출력
------------------------------------------------------------------------------------------------------------
| GetServiceQuota |
+----------------------------------------------------------------------------------------------------------+
|| Quota ||
|+---------------------+----------------------------------------------------------------------------------+|
|| Adjustable | True ||
|| Description | Maximum number of vCPUs assigned to the Running On-Demand G and VT instances. ||
|| GlobalQuota | False ||
|| QuotaAppliedAtLevel| ACCOUNT ||
|| QuotaArn | arn:aws:servicequotas:ap-northeast-2:123456789012:ec2/L-DB2E81BA ||
|| QuotaCode | L-DB2E81BA ||
|| QuotaName | Running On-Demand G and VT instances ||
|| ServiceCode | ec2 ||
|| ServiceName | Amazon Elastic Compute Cloud (Amazon EC2) ||
|| Unit | None ||
|| Value | 0.0 ||
|+---------------------+----------------------------------------------------------------------------------+|
핵심 필드만 확인해 보자.
| 필드 | 값 | 의미 |
|---|---|---|
| Value | 0.0 | 현재 G/VT 계열 인스턴스를 하나도 띄울 수 없다 |
| Adjustable | True | Service Quotas 콘솔/CLI로 증설 신청 가능 |
결과는 0 vCPU로, 증설 신청이 필요하다는 것을 알 수 있다.
Standard On-Demand vCPU 쿼터 확인
비교를 위해 Standard 계열 쿼터도 확인한다. 시스템 노드(t3.medium × 2, 총 4 vCPU) 구동 가능 여부를 사이드로 확인하는 것이다.
aws service-quotas get-service-quota \
--service-code ec2 \
--quota-code L-1216C47A \
--region ap-northeast-2 \
--output table
전체 출력
----------------------------------------------------------------------------------------------------------------------------------------
| GetServiceQuota |
+--------------------------------------------------------------------------------------------------------------------------------------+
|| Quota ||
|+---------------------+--------------------------------------------------------------------------------------------------------------+|
|| Adjustable | True ||
|| Description | Maximum number of vCPUs assigned to the Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instances. ||
|| GlobalQuota | False ||
|| QuotaAppliedAtLevel| ACCOUNT ||
|| QuotaArn | arn:aws:servicequotas:ap-northeast-2:123456789012:ec2/L-1216C47A ||
|| QuotaCode | L-1216C47A ||
|| QuotaName | Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instances ||
|| ServiceCode | ec2 ||
|| ServiceName | Amazon Elastic Compute Cloud (Amazon EC2) ||
|| Unit | None ||
|| Value | 32.0 ||
|+---------------------+--------------------------------------------------------------------------------------------------------------+|
결과는 32 vCPU로, 시스템 노드 t3.medium × 2(= 4 vCPU)에는 충분한 여유가 있다
해석
| 쿼터 | 현재 값 | 의미 |
|---|---|---|
| G/VT On-Demand vCPU | 0 | g5.xlarge 불가 |
| Standard On-Demand vCPU | 32 | 시스템 노드 여유 충분 |
서울 리전 신규/미사용 계정에서 자주 발생하는 패턴이다. G/VT 계열은 위에서 설명한 이유로 기본 0으로 차단되어 있으며, Adjustable=True이므로 Service Quotas 콘솔/CLI로 증설 신청이 가능하다.
Option B(g5.xlarge × 2)를 기준으로 최소 8 vCPU, 실습 여유를 고려해 16 vCPU 요청을 권장한다.
쿼터 증설 요청
요청 목표: 16 vCPU
필요 vCPU 계산
Option B 구성에 필요한 vCPU를 계산하면 다음과 같다.
- g5.xlarge = 4 vCPU/인스턴스
- Option B = g5.xlarge × 2대 = 8 vCPU
- “Running On-Demand G and VT instances” 쿼터 = 해당 계정·리전에서 동시에 켜둘 수 있는 G/VT 계열 인스턴스의 총 vCPU 합산 상한
계산상 8이면 딱 맞지만, 실습 중 여유를 확보하기 위해 16 vCPU로 증설을 요청한다. 8로 딱 맞추면 막히는 상황들이 있기 때문이다.
8이 아니라 16인 이유
핵심은 인스턴스 lifecycle의 비원자성이다. AWS 쿼터는 요청 시점의 running 인스턴스 vCPU 합산으로 체크하는데, 인스턴스 lifecycle에는 pending → running → shutting-down → terminated 구간이 있어서 “하나 죽이고 하나 띄우는” 과정이 원자적(atomic)이지 않다. 기존 인스턴스가 아직 terminate되지 않은 상태에서 새 인스턴스가 running에 진입하면 순간적으로 vCPU가 중복 합산되고, 쿼터 초과로 VcpuLimitExceeded 또는 InsufficientInstanceCapacity 에러가 발생한다.
실습 중 이런 lifecycle 중복이 발생하는 상황은 다음과 같다.
- 롤링 교체: EKS Managed Node Group이 노드를 교체할 때(AMI 업데이트, health check 실패 등) 새 노드를 먼저 띄우고 기존 노드를 drain한다. 순간적으로 3대(12 vCPU)가 동시에 running 상태가 된다
- 스케일 테스트: desired_size를 3으로 올려보거나 instance type 변경을 실험하는 경우
- 재시도/복구:
terraform apply실패 후 재시도할 때, ASG(Auto Scaling Group)가 이전 인스턴스를 아직 terminate하지 않은 상태에서 새 인스턴스를 요청하는 경우 - XID 에러 재현: GPU에 의도적 부하를 걸어 에러를 유발하는 실습에서 노드가 NotReady로 빠지면, ASG가 자동 교체를 시도하면서 순간 초과가 발생할 수 있다
16 vCPU는 g5.xlarge 4대 분량으로, 정상 운용(2대) + 교체/스케일 버퍼(2대)에 해당한다. 실습 중 어떤 상황에서도 쿼터에 걸리지 않는 안전선이다. 쿼터는 한도이지 과금이 아니므로, 인스턴스를 안 띄우면 비용은 발생하지 않는다.
증설 과정
Service Quotas 콘솔에서 증설을 요청한다.
AWS 서비스에서 ec2를 검색하여 Amazon Elastic Compute Cloud(Amazon EC2)를 선택한다.
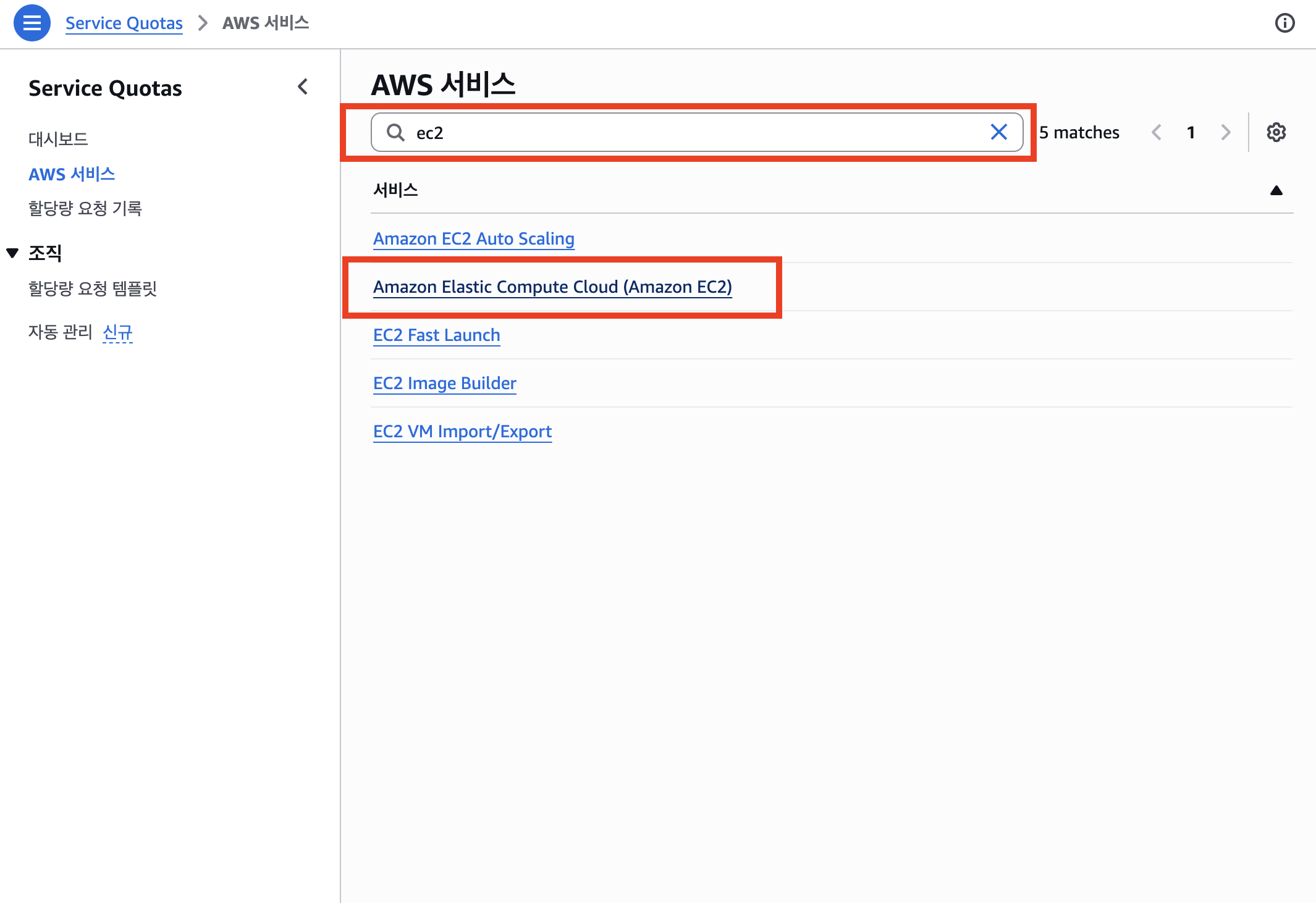
EC2 쿼터 목록에서 on-demand를 검색하면 Running On-Demand G and VT instances 항목이 보인다. 현재 값이 0이고, 조정 가능(Adjustable) 상태임을 확인한다.
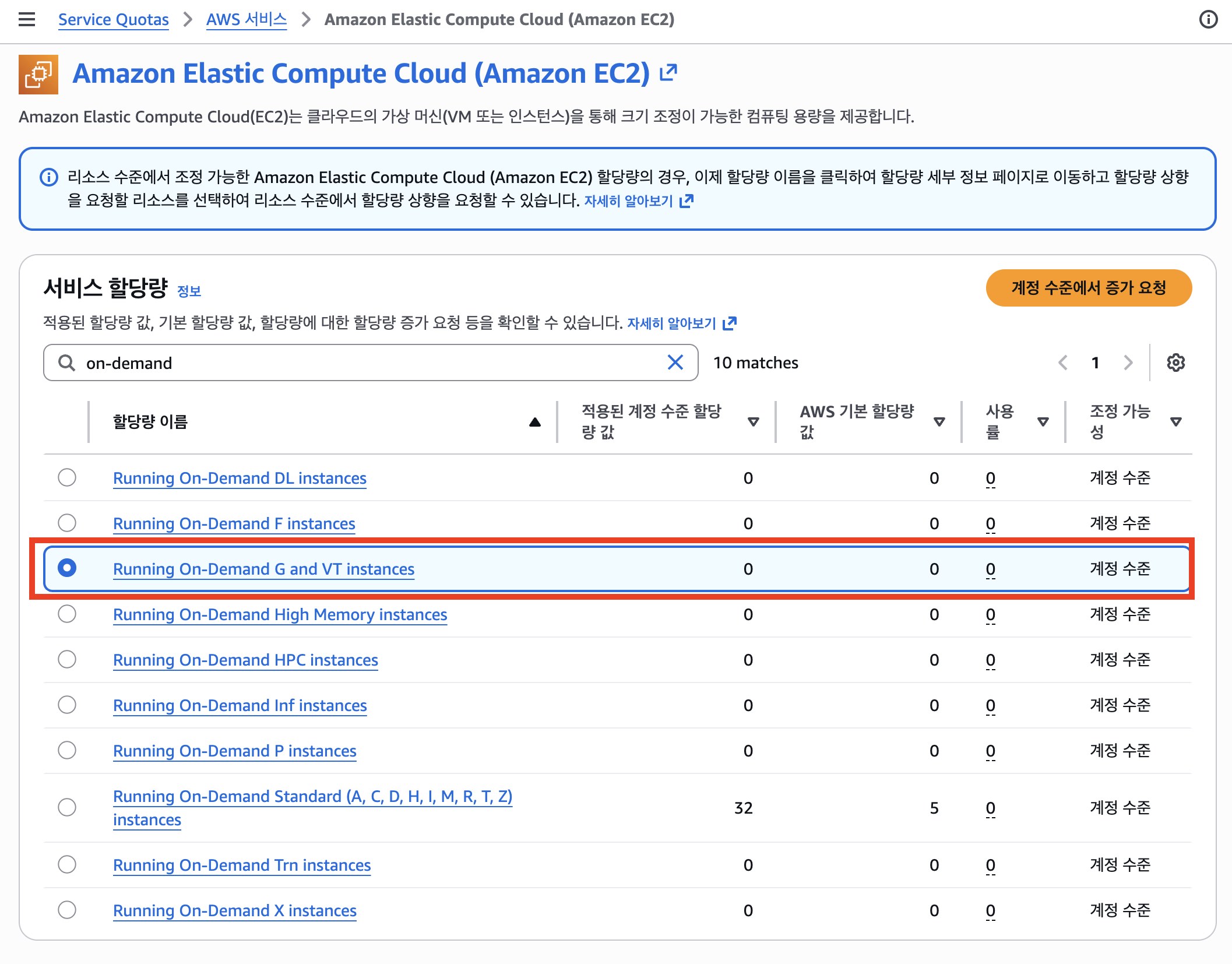
참고로 Standard 계열은 32로 여유가 충분하다.
G/VT 쿼터 증설 요청을 제출하면, 할당량 요청 기록 페이지에서 요청값 16, 상태 대기 중을 확인할 수 있다.
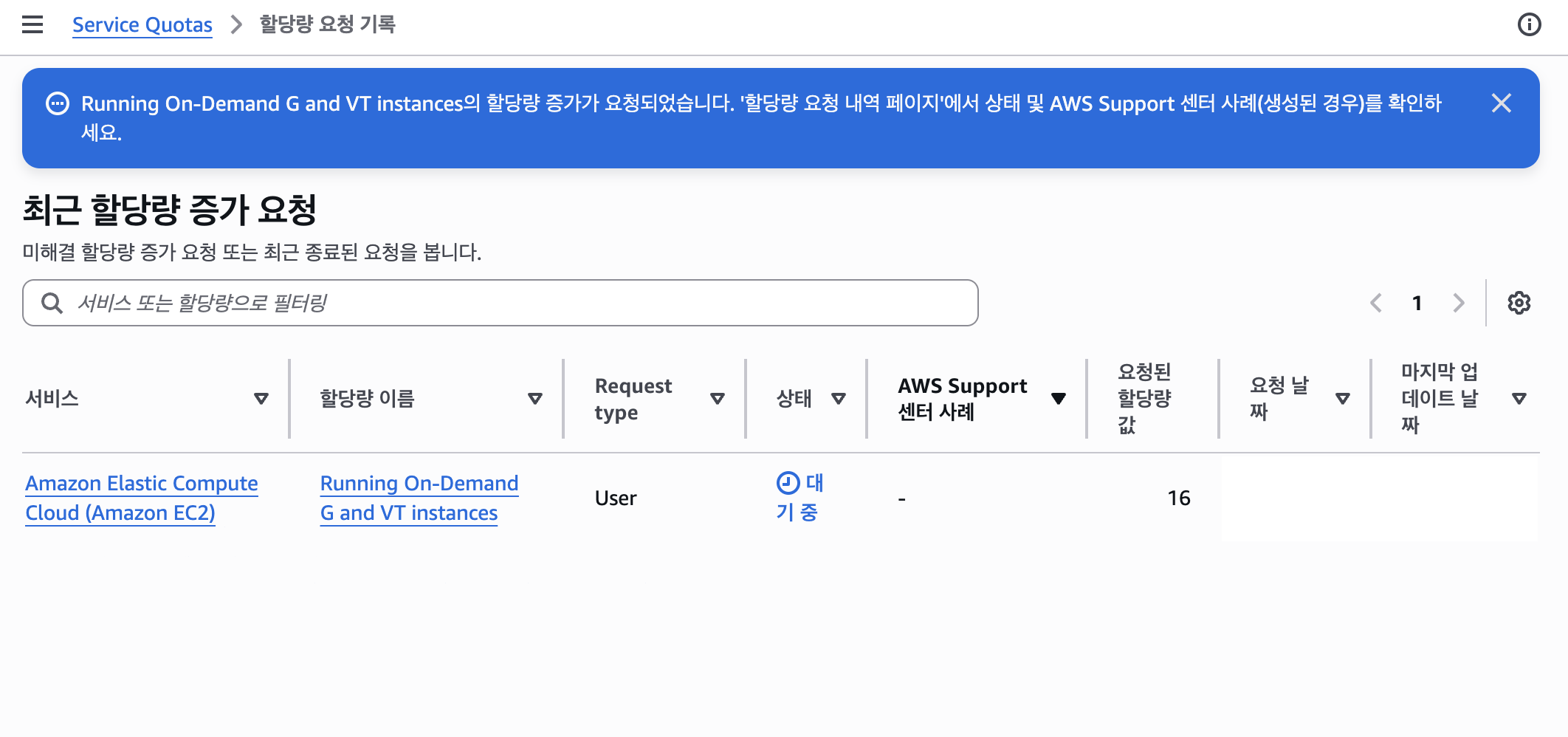
승인 결과
승인 후 할당량 요청 기록에서 케이스 번호가 노출된다.
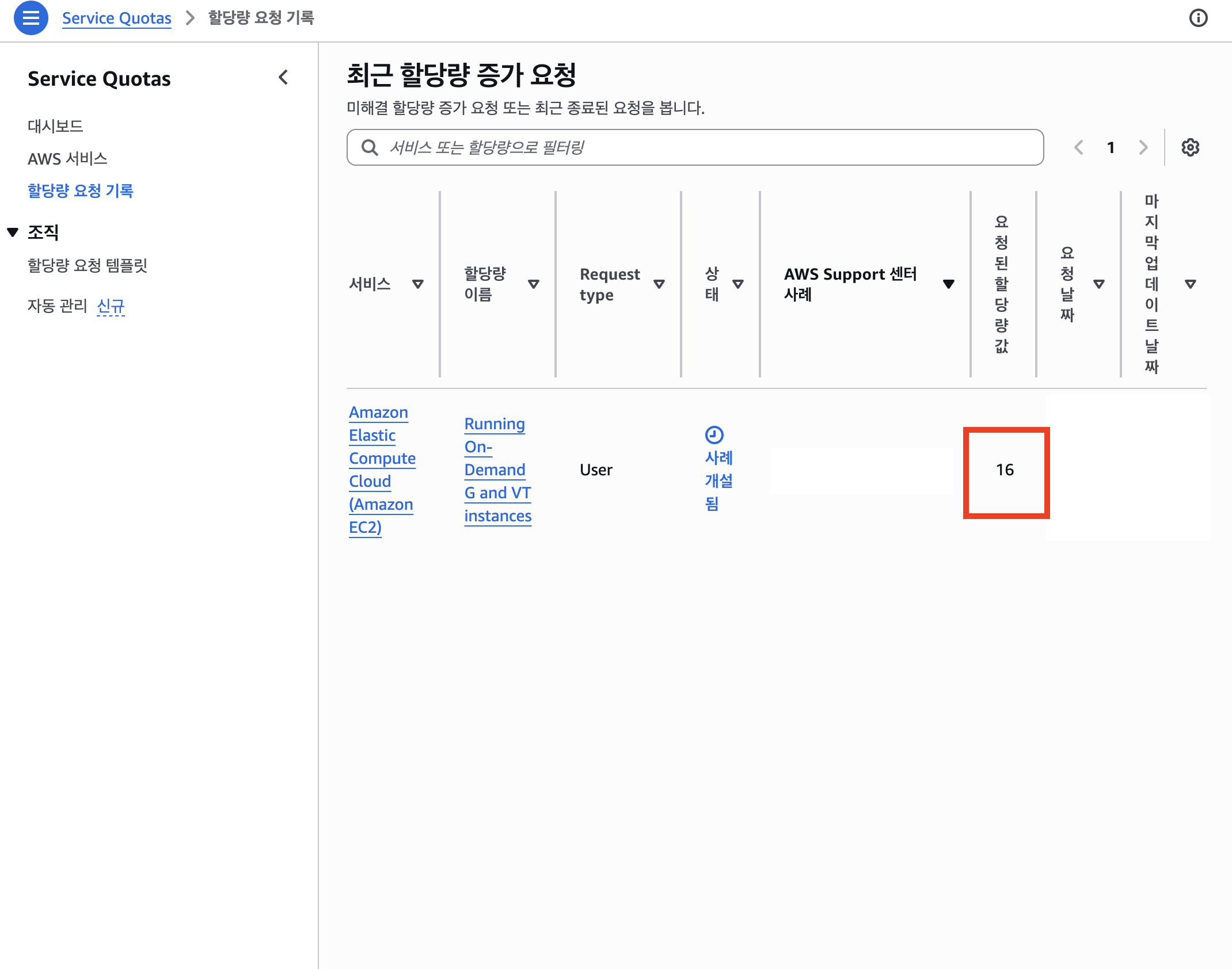
적용된 쿼터값을 세부 페이지에서 확인할 수 있다.
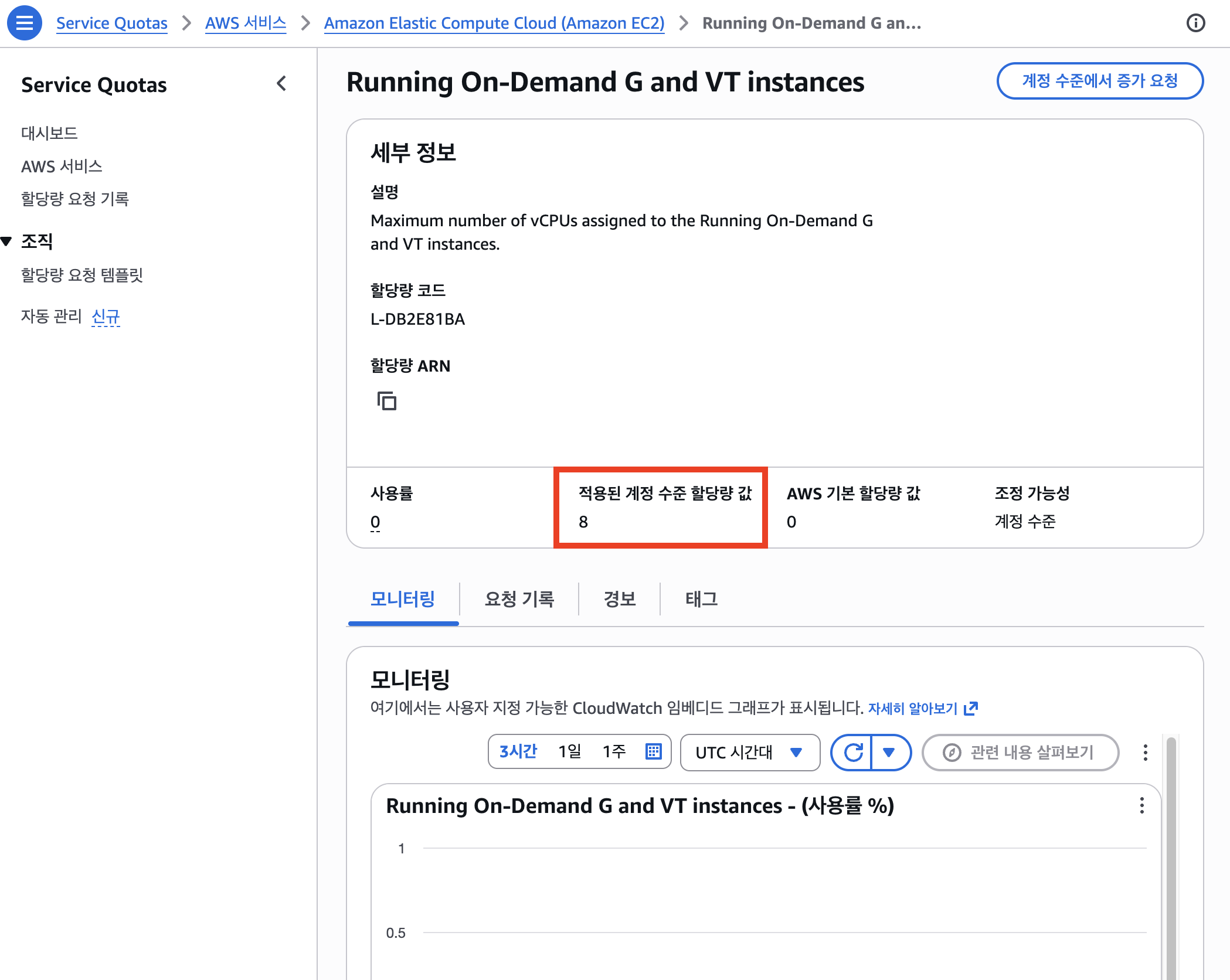
AWS Support 회신 이메일에서 일부분 승인임을 확인했다. 요청값 16에 대해 새 할당량은 8이다.
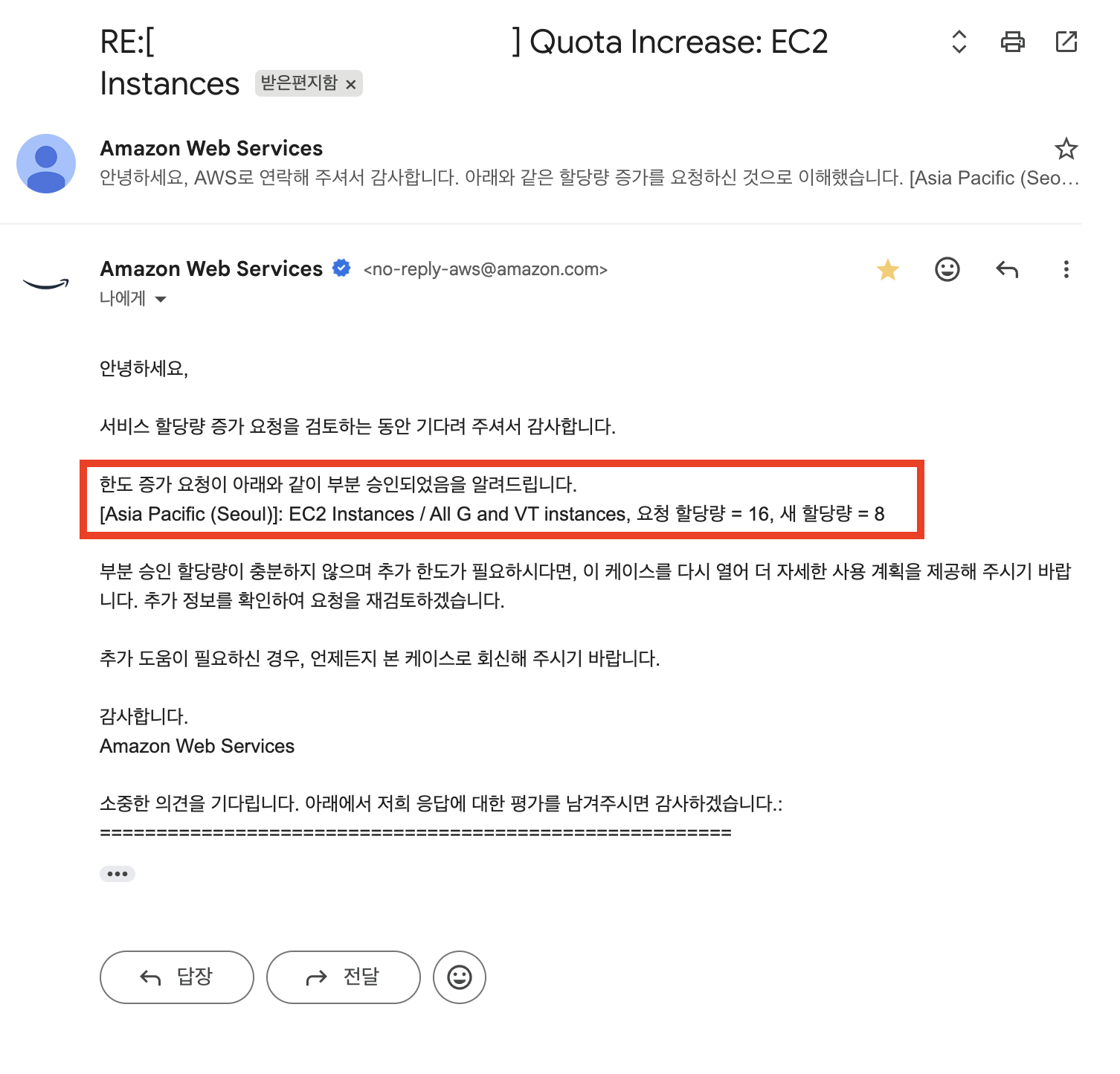
CLI로 변경된 값을 확인한다.
aws service-quotas get-service-quota \
--service-code ec2 \
--quota-code L-DB2E81BA \
--region ap-northeast-2 \
--output json
{
"Quota": {
"ServiceCode": "ec2",
"ServiceName": "Amazon Elastic Compute Cloud (Amazon EC2)",
"QuotaArn": "arn:aws:servicequotas:ap-northeast-2:123456789012:ec2/L-DB2E81BA",
"QuotaCode": "L-DB2E81BA",
"QuotaName": "Running On-Demand G and VT instances",
"Value": 8.0,
"Unit": "None",
"Adjustable": true,
"GlobalQuota": false
}
}
승인 결과 요약
| 항목 | 값 |
|---|---|
| 요청값 | 16 vCPU |
| 승인값 | 8 vCPU (일부분 승인) |
| 본 계정 적용 확인 | aws service-quotas get-service-quota → "Value": 8.0 |
| 비고 | 추가 필요 시 케이스 재오픈하여 상세 사용 계획 제공 후 추가 승인 가능 |
부분 승인(8 vCPU) 영향 분석
16을 요청한 이유는 “GPU 인스턴스 2대 띄우려고”가 아니다. 2대(= 8 vCPU)는 8만으로도 충분하다. 16은 롤링/재시도 여유였다. 즉, 이번 부분 승인(8)으로도 실습 본 목적(g5.xlarge × 2 정상 구동)은 그대로 가능하다.
영향 범위
| 구간 | 필요 vCPU | 8 vCPU 한도에서 가능? |
|---|---|---|
| 정상 실습 (GPU 노드 2대) | 8 | 가능 (여유 0) |
| Managed NG 롤링 교체 (신규+기존 3~4대 동시) | 12~16 | 불가 — 교체 중 쿼터 초과 실패 위험 |
| 장애 대응용 수동 scale-up 테스트 | >8 | 불가 |
| Terraform 재apply 중 인스턴스 겹침 | 일시적 12 | 불가 |
대응: ASG 최대 노드 수 제한
EKS 컴퓨팅 그룹에서도 살펴봤듯이, ASG(Auto Scaling Group)는 동일한 설정의 EC2 인스턴스를 하나의 그룹으로 묶고 min/max/desired 개수를 지정하여 자동으로 인스턴스를 관리하는 단위다. EKS Managed Node Group은 내부적으로 ASG를 사용하며, 여기서 max_size는 해당 노드 그룹에서 동시에 실행할 수 있는 노드 수의 상한을 의미한다.
GPU 노드 그룹의 ASG 최대 노드 수(max_size)를 2로 제한한다.
- 이유: max_size가 4인 상태에서 롤링 이벤트가 발생하면 쿼터 초과로 실패한다. 2로 낮추면 ASG 차원에서 애초에 8 vCPU를 넘지 않도록 강제할 수 있다
- 트레이드오프: 롤링 replace 전략 실습(예: XID 에러 재현 후 자동 교체)을 할 때 “새 노드 1대 띄우고 기존 1대 drain” 패턴이 막힌다(2 → 3 확장 불가). LaunchTemplate 변경(디스크 크기 수정 등)에 의한 EKS 자동 rolling update도 동일하게 실패한다 — EKS managed NG는 LT 버전이 바뀌면 surge 방식(신규 노드 먼저 추가 → 기존 drain → 기존 종료)으로 교체를 시도하는데, 3번째 노드를 띄우려는 순간
VcpuLimitExceeded로 5회 retry 후 abort된다. 이 경우 기존 노드 2대는 이전 LT 버전으로 그대로 유지된다. 우회 경로는 scale-down(0) → apply(LT 반영) → scale-up(2)으로, 새 노드가 처음부터 새 LT로 생성되게 하는 것이다
재증설이 필요한 시점
아래와 같이 재증설이 필요한 시점에만 케이스를 재오픈하여 16으로 증설할 수 있다. 이 경우 케이스 재오픈 시 AWS가 요구하는 “상세 사용 계획”(어떤 노드를 언제 몇 대까지 띄우는지)을 제공하면 잔여 8 추가 승인 가능성이 있다.
- LaunchTemplate 변경을 rolling으로 적용해야 하는 경우 (scale-down 우회가 불가한 상황)
- 스케일/롤링 시나리오를 단독 세션으로 돌릴 때
다만, 해당 실습 시나리오를 반드시 진행해야 하는 경우에만 재증설 요청을 할 예정이다.
정리
결과 요약
| 항목 | 값 | 평가 |
|---|---|---|
| G/VT On-Demand vCPU (신청 전) | 0 | 차단 요인 — g5.xlarge 불가 |
| G/VT On-Demand vCPU (승인 후) | 8 (요청 16, 부분 승인) | Option B(g5.xlarge × 2 = 8 vCPU) 정확히 수용. 여유 0 |
| Standard On-Demand vCPU | 32 | 시스템 노드 t3.medium × 2(= 4 vCPU) 여유 충분 |
차단 요인
- 현재 남은 제약: G/VT 8 vCPU 상한. Option B 정상 실습(g5.xlarge × 2)은 가능하나 롤링 교체·스케일 테스트는 불가. ASG max_size를 2로 제한하여 초과를 방지한다
- 더 많은 한도가 필요하면 기존 케이스를 재오픈하여 상세 사용 계획을 제공한다. 또는 다른 리전(us-east-1, us-west-2)으로 이전할 수 있으나, 스터디 일관성상 서울 유지를 권장한다
참고: 승인 소요 시간
이번 G/VT 쿼터 증설(16 vCPU 요청)은 약 4시간 만에 회신이 왔다.
- “수시간~1일”이라는 일반 가이드 대비 빠른 편이다. 다만 이 회신 결과는 서울 리전/오후 시간대/Standard 지원 플랜 기준 데이터 포인트 1건으로만 해석해야 한다.
- 일부분 승인(8/16)이긴 하지만, Option B 실습의 코어 요구(8 vCPU)는 즉시 충족되어 실습 착수에 지연은 없었다
다음 단계
쿼터가 확보되었으므로, 다음 포스트에서는 Terraform으로 EKS 클러스터를 실제로 배포한다. GPU 노드는 비용을 고려하여 처음에는 0대로 시작하고, 시스템 노드와 EKS 애드온 기반을 먼저 구축한다. 이후 GPU 트러블슈팅 실습에 진입할 때 GPU 노드를 기동하여 g5.xlarge 2대를 프로비저닝하는 방식으로 진행한다. ASG 최대 노드 수는 위의 부분 승인 영향 분석에서 다룬 대로 2로 제한하여 쿼터 초과를 방지한다.

댓글남기기