
[EKS] EKS GPU 트러블슈팅: 2. 실습 환경 구성 - 2. 배포 결과
정영준님의 AWS EKS Workshop Study(AEWS) 5주차 학습 내용을 기반으로 합니다.
TL;DR
이전 글에서 분석한 Terraform 코드를 실제 배포하고 결과를 확인한다.
- 배포 결과: 84개 리소스, ~14분 소요. EKS 1.35, 시스템 노드 t3.medium × 2(AZ 2a/2c 분산), GPU 노드 0대
- 비용 가드 동작 확인: GPU 노드 0대, LoadBalancer 0개, Helm release 0개. 기반 인프라만으로 ~$6/일 수준
- vpc-cni
before_compute=true실측: aws-node DaemonSet이 나머지 addon보다 ~2분 먼저 Ready - 보안그룹 baseline: 노드 SG ingress 10개 + egress 1개. NCCL 실제 경로인 1025-65535/tcp self-reference 규칙 확인
- GPU Operator 렌더 프리뷰: Helm template으로 27개 리소스 미리 확인. device-plugin/dcgm/driver 등은 ClusterPolicy가 런타임에 생성
배포 실행
이전 글에서 분석한 Terraform 코드를 gpu_desired_size=0, enable_gpu_operator=false 기본값으로 배포한다. GPU 노드와 GPU Operator 없이 기반 인프라만 먼저 올리는 것이다.
terraform init
terraform init -no-color
Initializing the backend...
Initializing modules...
Initializing provider plugins...
- Reusing previous version of hashicorp/aws from the dependency lock file
- Reusing previous version of hashicorp/helm from the dependency lock file
- Reusing previous version of hashicorp/cloudinit from the dependency lock file
- Reusing previous version of hashicorp/null from the dependency lock file
- Reusing previous version of hashicorp/tls from the dependency lock file
- Reusing previous version of hashicorp/time from the dependency lock file
- Using previously-installed hashicorp/aws v6.41.0
- Using previously-installed hashicorp/helm v2.17.0
- Using previously-installed hashicorp/cloudinit v2.3.7
- Using previously-installed hashicorp/null v3.2.4
- Using previously-installed hashicorp/tls v4.2.1
- Using previously-installed hashicorp/time v0.13.1
Terraform has been successfully initialized!
1주차~4주차 대비 Helm Provider(v2.17.0)가 새로 추가된 것이 눈에 띈다. gpu_operator.tf에서 Helm으로 GPU Operator를 배포하기 때문이다. 4주차까지는 Helm Provider가 필요 없었다.
terraform validate
terraform validate -no-color
Success! The configuration is valid.
terraform plan
terraform plan -no-color -out=/tmp/bundle-apply.tfplan
Plan: 84 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ ami_al2023_nvidia = "ami-0abc1234def56789a"
+ ami_al2023_standard = "ami-0abc1234def56789b"
+ auxiliary_node_sg_id = (known after apply)
+ cluster_endpoint = (known after apply)
+ cluster_name = "myeks5w"
+ cluster_security_group_id = (known after apply)
+ configure_kubectl = "aws eks --region ap-northeast-2 update-kubeconfig --name myeks5w"
+ gpu_subnet_az = "ap-northeast-2a"
+ gpu_subnet_id = (known after apply)
+ node_security_group_id = (known after apply)
84개 리소스가 새로 생성될 예정이다. 1주차(52개)에서 시작해, 4주차에서 addon 7종 + cert-manager, 프라이빗 서브넷, NAT 등이 추가되었고, 이번에는 GPU 노드 그룹, CAS IAM 정책, 보안그룹 실험 토글이 더해져 84개까지 늘었다.
리소스 타입별 집계
plan에서 생성할 리소스를 타입별로 집계하면 다음과 같다.
| 리소스 타입 | 개수 | 비고 |
|---|---|---|
aws_security_group_rule |
14 | 노드 SG + 보조 SG + 클러스터 SG 규칙 |
aws_iam_role_policy_attachment |
13 | 클러스터/노드 IAM 정책 바인딩 |
aws_eks_addon_version (data) |
7 | most_recent=true 해석 |
aws_eks_addon |
7 | coredns, kube-proxy, vpc-cni 등 7종 |
aws_route_table_association |
6 | 퍼블릭 3 + 프라이빗 3 |
aws_subnet |
6 | 퍼블릭 3 + 프라이빗 3 |
aws_iam_policy |
4 | LB Controller, ExternalDNS, CAS, 클러스터 암호화 |
aws_security_group |
3 | 클러스터, 노드, 보조 |
aws_iam_role |
3 | 클러스터, 시스템 NG, GPU NG |
aws_eks_node_group |
2 | primary + gpu |
aws_launch_template |
2 | primary + gpu |
| 기타 | 27 | VPC, EKS 클러스터, KMS, NAT, OIDC 등 |
총 93개(managed 84 + data source 등 9)가 plan에 잡힌다. aws_security_group_rule 14개가 가장 많은 것은, EKS 모듈의 recommended rules(10개)에 보조 SG 규칙(ingress 1 + egress 1)과 클러스터 SG 규칙(ingress 1 + egress 1)이 더해진 결과다.
노드 그룹 스펙
plan에서 추출한 두 노드 그룹의 스펙을 비교한다.
| 항목 | primary (시스템) | gpu |
|---|---|---|
| AMI | AL2023_x86_64_STANDARD | AL2023_x86_64_NVIDIA |
| 인스턴스 타입 | t3.medium | g5.xlarge |
| 용량 타입 | ON_DEMAND | ON_DEMAND |
| desired / max / min | 2 / 4 / 1 | 0 / 2 / 0 |
| 디스크 | 30GB (disk_size) |
100GB gp3 (block_device_mappings) |
| label | tier=primary |
tier=gpu, nvidia.com/gpu=true |
| taint | 없음 | nvidia.com/gpu=true:NoSchedule |
GPU 노드 그룹의 desired_size=0이 비용 가드의 핵심이다. plan 단계에서 subnet_ids가 None으로 표시되는 것은 known after apply 때문이며, apply 후 output으로 단일 AZ 고정을 확인한다.
terraform apply
terraform apply -no-color -auto-approve /tmp/bundle-apply.tfplan
리소스 생성 순서
apply 로그에서 리소스 생성 순서를 추적하면 다음과 같다.
1단계: VPC + IAM (병렬)
terraform_data.validate_inputs: Creation complete after 0s
aws_iam_policy.external_dns_policy: Creation complete after 1s
aws_iam_policy.aws_cas_autoscaler_policy: Creation complete after 1s
aws_iam_policy.aws_lb_controller_policy: Creation complete after 1s
module.vpc.aws_vpc.this[0]: Creation complete after 1s
module.eks.aws_iam_role.this[0]: Creation complete after 1s
입력 검증(validate_inputs)이 가장 먼저 통과한다. VPC와 IAM 정책/역할은 서로 의존성이 없으므로 병렬 생성된다.
2단계: 서브넷 + 보안그룹 + KMS
module.vpc.aws_subnet.private[0]: Creation complete after 3s
aws_security_group.node_group_sg: Creation complete after 2s
module.eks.aws_security_group.node[0]: Creation complete after 2s
module.eks.aws_security_group.cluster[0]: Creation complete after 2s
module.eks.module.kms.aws_kms_key.this[0]: Creation complete after 28s
VPC가 생성된 후 서브넷과 보안그룹이 병렬로 만들어진다.
3단계: EKS 클러스터 (~9분 24초)
module.eks.aws_eks_cluster.this[0]: Creating...
module.eks.aws_eks_cluster.this[0]: Still creating... [9m10s elapsed]
module.eks.aws_eks_cluster.this[0]: Creation complete after 9m24s
전체 14분 중 9분 24초가 EKS 컨트롤 플레인 생성에 소요된다. AWS가 API Server, etcd, 스케줄러 등을 프로비저닝하는 시간이다.
4단계: vpc-cni (before_compute)
module.eks.aws_eks_addon.before_compute["vpc-cni"]: Creating...
module.eks.aws_eks_addon.before_compute["vpc-cni"]: Creation complete after 35s
before_compute=true 설정 덕분에 vpc-cni가 노드 그룹보다 먼저 설치된다.
5단계: 노드 그룹 (병렬)
module.eks.module.eks_managed_node_group["primary"].aws_eks_node_group.this[0]: Creating...
module.eks.module.eks_managed_node_group["gpu"].aws_eks_node_group.this[0]: Creating...
module.eks.module.eks_managed_node_group["gpu"].aws_eks_node_group.this[0]: Creation complete after 58s
module.eks.module.eks_managed_node_group["primary"].aws_eks_node_group.this[0]: Creation complete after 1m48s
primary와 gpu 노드 그룹이 병렬로 생성된다. GPU 노드 그룹은 desired_size=0이라 EC2 인스턴스를 실제로 기동하지 않으므로 58초만에 완료된다. primary는 t3.medium 2대를 실제로 기동해야 하므로 1분 48초가 걸린다.
6단계: 나머지 addon (노드 그룹 이후)
module.eks.aws_eks_addon.this["coredns"]: Creation complete after 15s
module.eks.aws_eks_addon.this["eks-pod-identity-agent"]: Creation complete after 25s
module.eks.aws_eks_addon.this["kube-proxy"]: Creation complete after 25s
module.eks.aws_eks_addon.this["external-dns"]: Creation complete after 35s
module.eks.aws_eks_addon.this["cert-manager"]: Creation complete after 45s
module.eks.aws_eks_addon.this["metrics-server"]: Creation complete after 55s
최종 결과
Apply complete! Resources: 84 added, 0 changed, 0 destroyed.
terraform output
terraform output -json
{
"ami_al2023_nvidia": "ami-0abc1234def56789a",
"ami_al2023_standard": "ami-0abc1234def56789b",
"auxiliary_node_sg_id": "sg-0abc1234",
"cluster_endpoint": "https://ABCDEF1234567890.gr7.ap-northeast-2.eks.amazonaws.com",
"cluster_name": "myeks5w",
"cluster_security_group_id": "sg-0abc5678",
"configure_kubectl": "aws eks --region ap-northeast-2 update-kubeconfig --name myeks5w",
"gpu_subnet_az": "ap-northeast-2a",
"gpu_subnet_id": "subnet-0abc9012",
"node_security_group_id": "sg-0abc3456"
}
GPU 서브넷이 ap-northeast-2a 단일 AZ에 고정된 것을 확인할 수 있다. 이전 글에서 subnet_ids 속성명 문제를 지적했는데, output으로 단일 AZ 고정이 정상 반영되었음을 증명한다.
kubeconfig 업데이트
aws eks --region ap-northeast-2 update-kubeconfig --name myeks5w
Updated context arn:aws:eks:ap-northeast-2:123456789012:cluster/myeks5w in /Users/eraser/.kube/config
클러스터 기본 사항 확인
배포 직후 클러스터의 상태를 확인한다.
콘솔 확인
EKS 콘솔에서 배포 결과를 확인한다.
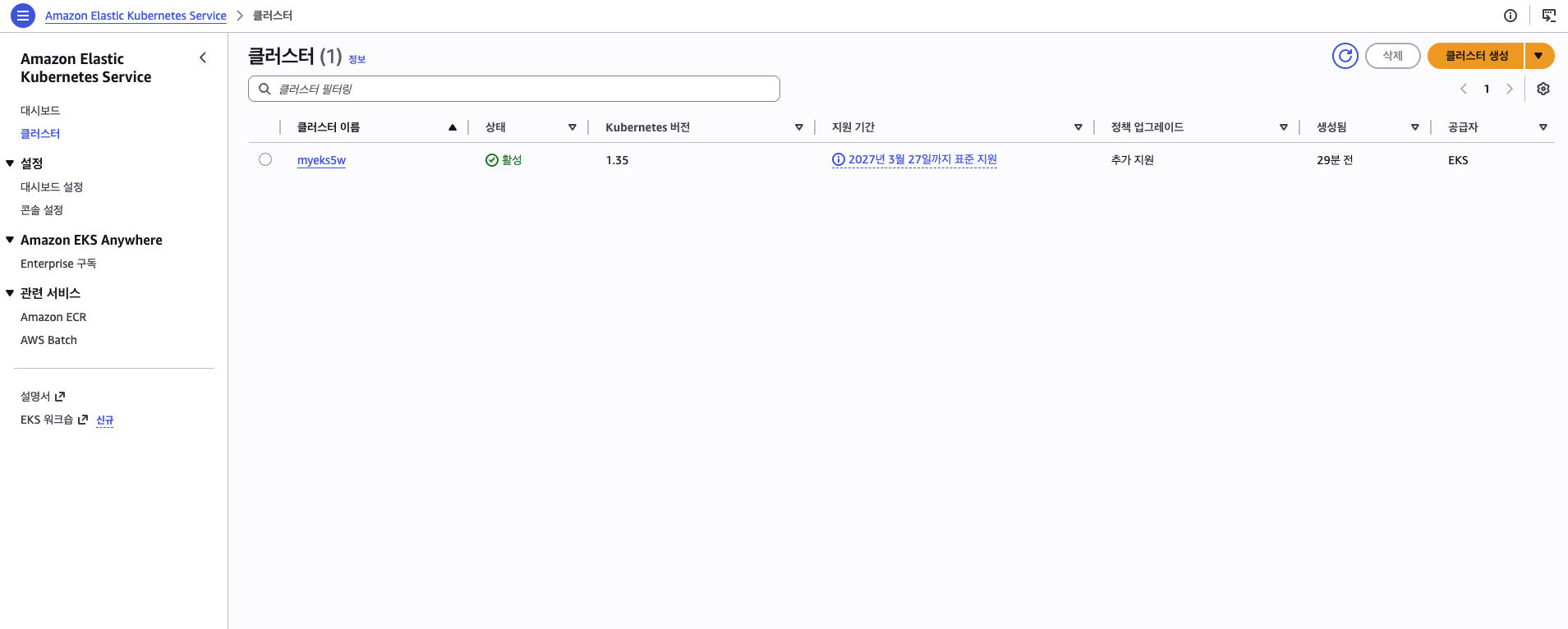
myeks5w가 K8s 1.35, 활성 상태로 생성됨
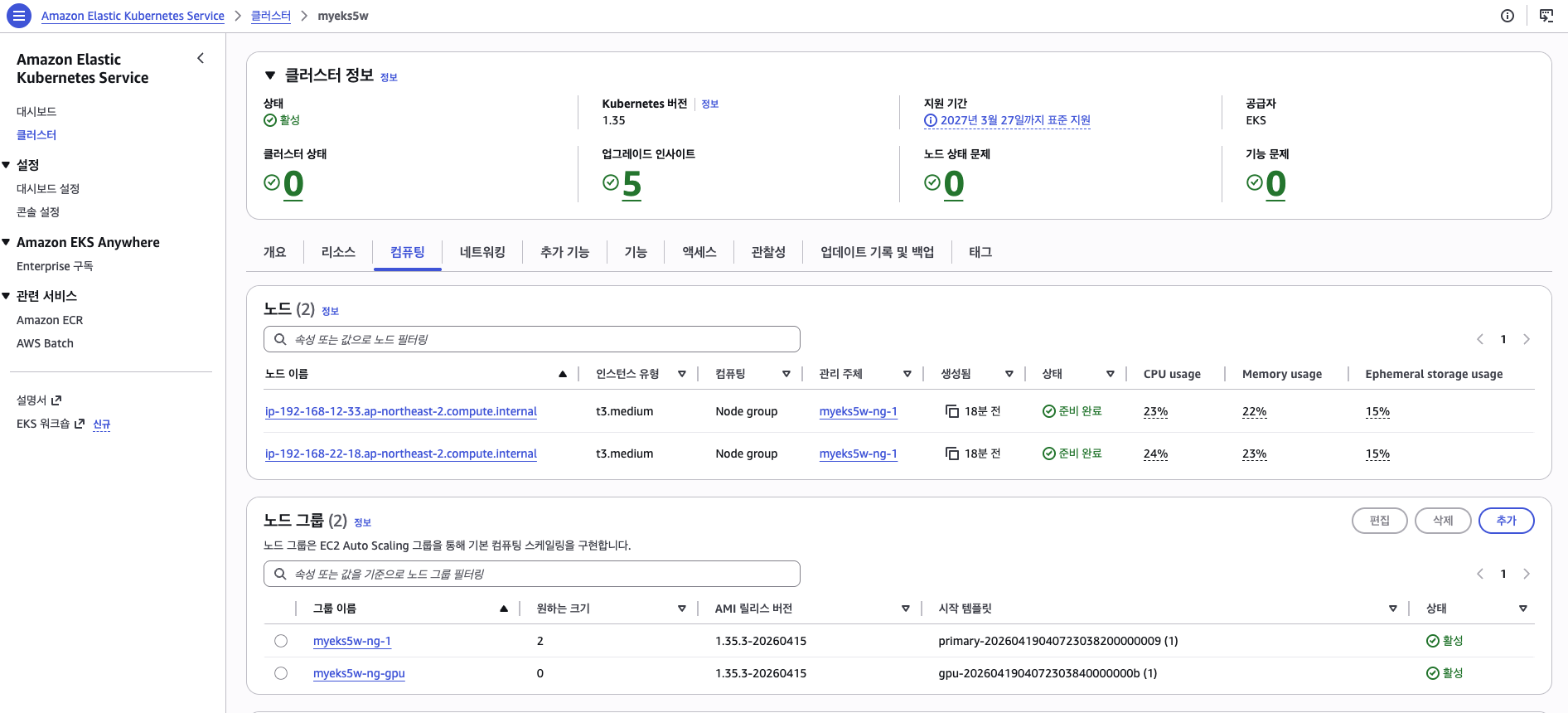
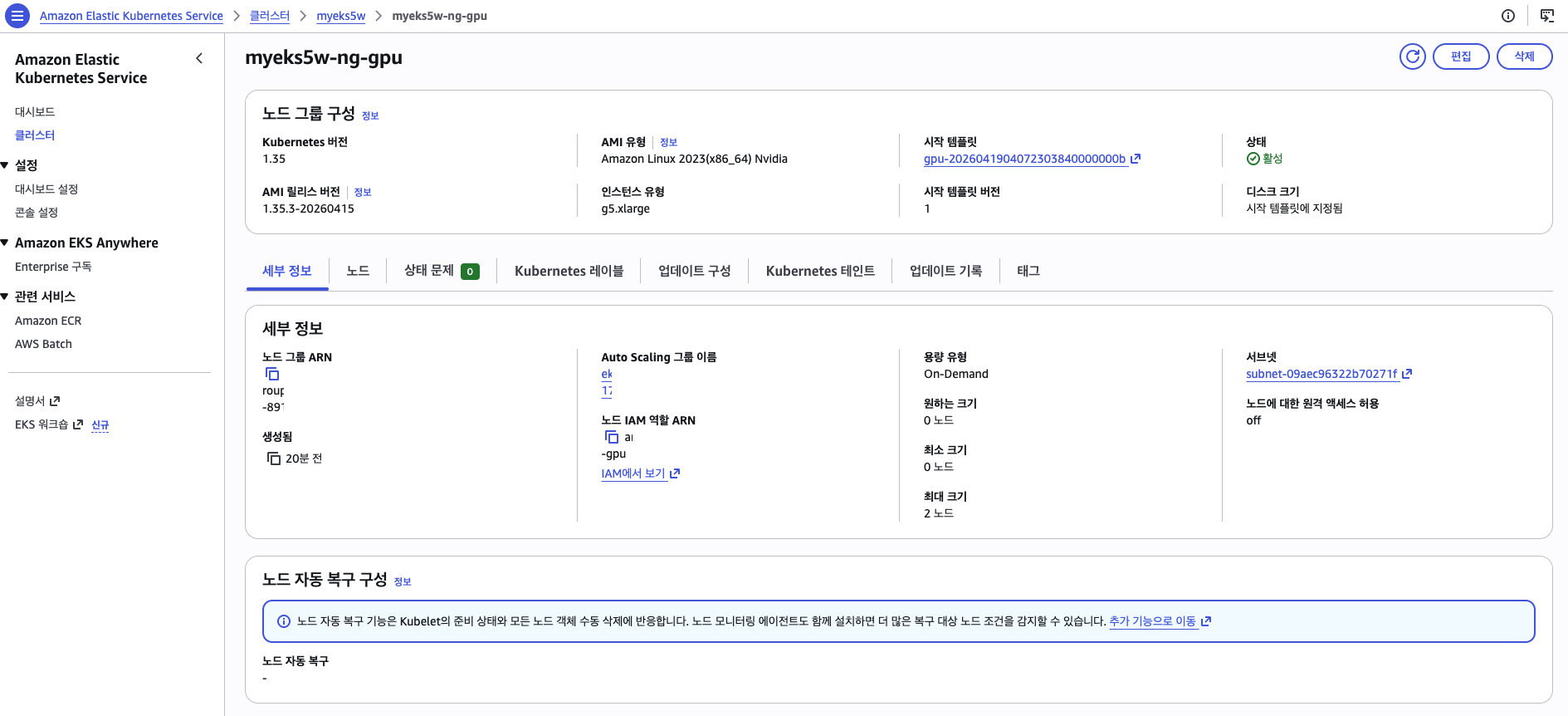
GPU 노드 그룹의 서브넷이 하나(subnet-0abc9012)만 연결되어 있고, 원하는 크기가 0인 것이 비용 가드의 동작을 보여준다.
클러스터 정보
kubectl cluster-info
Kubernetes control plane is running at https://ABCDEF1234567890.gr7.ap-northeast-2.eks.amazonaws.com
CoreDNS is running at https://ABCDEF1234567890.gr7.ap-northeast-2.eks.amazonaws.com/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
kubectl version -o yaml
# 주요 부분 발췌
serverVersion:
gitVersion: v1.35.3-eks-bbe087e
major: "1"
minor: "35"
platform: linux/amd64
서버 버전이 v1.35.3-eks-bbe087e다. 이 글은 EKS 1.35 기준이다.
readyz 확인
kubectl get --raw='/readyz?verbose'
readyz 전체 출력
[+]ping ok
[+]log ok
[+]etcd ok
[+]etcd-readiness ok
[+]kms-providers ok
[+]informer-sync ok
[+]poststarthook/start-apiserver-admission-initializer ok
[+]poststarthook/generic-apiserver-start-informers ok
[+]poststarthook/priority-and-fairness-config-consumer ok
[+]poststarthook/priority-and-fairness-filter ok
[+]poststarthook/storage-object-count-tracker-hook ok
[+]poststarthook/start-apiextensions-informers ok
[+]poststarthook/start-apiextensions-controllers ok
[+]poststarthook/crd-informer-synced ok
[+]poststarthook/start-system-namespaces-controller ok
[+]poststarthook/start-cluster-authentication-info-controller ok
[+]poststarthook/start-kube-apiserver-identity-lease-controller ok
[+]poststarthook/start-kube-apiserver-identity-lease-garbage-collector ok
[+]poststarthook/start-legacy-token-tracking-controller ok
[+]poststarthook/start-service-ip-repair-controllers ok
[+]poststarthook/rbac/bootstrap-roles ok
[+]poststarthook/scheduling/bootstrap-system-priority-classes ok
[+]poststarthook/priority-and-fairness-config-producer ok
[+]poststarthook/bootstrap-controller ok
[+]poststarthook/start-kubernetes-service-cidr-controller ok
[+]poststarthook/aggregator-reload-proxy-client-cert ok
[+]poststarthook/start-kube-aggregator-informers ok
[+]poststarthook/apiservice-status-local-available-controller ok
[+]poststarthook/apiservice-status-remote-available-controller ok
[+]poststarthook/apiservice-registration-controller ok
[+]poststarthook/apiservice-discovery-controller ok
[+]poststarthook/kube-apiserver-autoregistration ok
[+]autoregister-completion ok
[+]poststarthook/apiservice-openapi-controller ok
[+]poststarthook/apiservice-openapiv3-controller ok
[+]shutdown ok
readyz check passed
etcd, kms-providers, scheduler 등 관리형 컨트롤 플레인의 전 서브시스템이 ok 상태다.
노드 확인
kubectl get nodes -o wide --show-labels
NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE LABELS
ip-192-168-xx-xx.ap-northeast-2.compute.internal Ready <none> 87s v1.35.3-eks-bbe087e 192.168.xx.xx ... ...,tier=primary,topology.kubernetes.io/zone=ap-northeast-2a,...
ip-192-168-yy-yy.ap-northeast-2.compute.internal Ready <none> 86s v1.35.3-eks-bbe087e 192.168.yy.yy ... ...,tier=primary,topology.kubernetes.io/zone=ap-northeast-2c,...
시스템 노드 2대가 ap-northeast-2a와 ap-northeast-2c에 분산 배치되어 있다. tier=primary TF label이 정상 적용되었다.
주요 EKS 자동 라벨을 정리하면 다음과 같다.
| 라벨 | 값(예시) | 설명 |
|---|---|---|
topology.kubernetes.io/zone |
ap-northeast-2a |
K8s 표준 AZ 라벨 |
topology.k8s.aws/zone-id |
apne2-az1 |
AWS 고유 AZ ID — 계정 간 물리적 매핑이 다를 수 있는 AZ name과 달리, 물리 위치가 고정 |
eks.amazonaws.com/nodegroup |
myeks5w-ng-1 |
소속 노드 그룹 |
eks.amazonaws.com/capacityType |
ON_DEMAND |
용량 타입 |
node.kubernetes.io/instance-type |
t3.medium |
인스턴스 타입 |
tier |
primary |
Terraform에서 직접 지정한 커스텀 라벨 |
노드 describe에서 확인한 Capacity/Allocatable 정보도 눈여겨볼 만하다.
| 항목 | Capacity | Allocatable |
|---|---|---|
| CPU | 2 | 1930m |
| Memory | 3926444Ki (~3.7Gi) | 3371436Ki (~3.2Gi) |
| Pods | 50 | 50 |
Pods가 50인 것은 이전 글에서 NodeConfig로 maxPods: 50을 설정한 결과다.
kube-system 워크로드
kubectl -n kube-system get ds,deploy -o wide
| 종류 | 이름 | Ready | 버전 | AGE |
|---|---|---|---|---|
| DaemonSet | aws-node | 2/2 | v1.21.1-eksbuild.7 | 3m |
| DaemonSet | eks-pod-identity-agent | 2/2 | v0.1.37 | 56s |
| DaemonSet | kube-proxy | 2/2 | v1.35.3-eksbuild.2 | 56s |
| Deployment | coredns | 2/2 | v1.13.2-eksbuild.4 | 55s |
| Deployment | metrics-server | 2/2 | v0.8.1-eksbuild.6 | 54s |
aws-node(vpc-cni)의 AGE가 3m인 반면 나머지는 56s 이하다. 이것이 before_compute=true의 효과다. vpc-cni가 노드 그룹보다 ~2분 먼저 설치되었기 때문에 노드가 Ready되기 전에 이미 CNI가 동작 중이었고, 첫 system pod들이 IP 미할당 Pending 상태를 거치지 않았다.
vpc-cni / kube-proxy 설정
kubectl -n kube-system get cm amazon-vpc-cni -o yaml
# 주요 필드 발췌
data:
enable-network-policy-controller: "false"
minimum-ip-target: "3"
warm-ip-target: "1"
warm-prefix-target: "0"
kubectl -n kube-system get cm kube-proxy-config -o yaml
kube-proxy 모드는 iptables다. EKS의 기본 모드이며, 2주차 실습에서 확인한 것과 동일하다.
애드온 버전
most_recent=true로 설치된 7개 애드온의 실제 버전을 정리한다.
| 애드온 | 설치 버전 | K8s 1.35 호환 |
|---|---|---|
| coredns | v1.13.2-eksbuild.4 | O |
| kube-proxy | v1.35.3-eksbuild.2 | O |
| vpc-cni | v1.21.1-eksbuild.7 | O |
| metrics-server | v0.8.1-eksbuild.6 | O |
| external-dns | (최신) | O |
| eks-pod-identity-agent | v0.1.37 | O |
| cert-manager | (최신) | O |
모두 K8s 1.35 호환 최신 버전이 설치되었다.
OIDC Provider
# OIDC URL 조회
OIDC_URL=$(aws eks describe-cluster --name myeks5w \
--query 'cluster.identity.oidc.issuer' --output text)
# OIDC Provider ARN 조회
OIDC_ARN=$(aws iam list-open-id-connect-providers \
--query "OpenIDConnectProviderList[?contains(Arn, '${OIDC_URL#https://}')].Arn" \
--output text)
# Provider 상세 확인
aws iam get-open-id-connect-provider \
--open-id-connect-provider-arn "$OIDC_ARN"
{
"Url": "oidc.eks.ap-northeast-2.amazonaws.com/id/ABCDEF1234567890",
"ClientIDList": [
"sts.amazonaws.com"
],
"ThumbprintList": [
"06b25927c42a721631c1efd9431e648fa62e1e39"
]
}
OIDC Provider가 IAM에 등록되어 있다. IRSA(IAM Roles for Service Accounts)의 전제 조건이다. ClientIDList에 sts.amazonaws.com이 포함되어 있어, Service Account가 STS를 통해 IAM Role을 assume할 수 있다.
CloudWatch 로그 그룹
aws logs describe-log-groups \
--log-group-name-prefix /aws/eks/myeks5w/
{
"logGroups": [
{
"logGroupName": "/aws/eks/myeks5w/cluster",
"retentionInDays": 90,
"storedBytes": 0,
"logGroupClass": "STANDARD"
}
]
}
컨트롤 플레인 로그 그룹 1개가 생성되었다. retention 90일, 생성 직후라 storedBytes=0이다. 이전 글에서 api와 scheduler 2종만 활성화했으므로 이 로그 그룹에 해당 로그가 수집된다.
네트워크/보안그룹 baseline
NCCL 보안그룹 차단 실험의 기준점이 되는 네트워크 구성을 확인한다.
노드 보안그룹
aws ec2 describe-security-groups \
--group-ids "$(terraform output -raw node_security_group_id)"
EKS 모듈이 생성한 노드 보안그룹의 규칙을 정리하면 다음과 같다.
| # | 방향 | 프로토콜 | 포트 | 소스/대상 | 역할 |
|---|---|---|---|---|---|
| 1 | ingress | tcp | 443 | cluster SG | API server → node |
| 2 | ingress | tcp | 4443 | cluster SG | webhook |
| 3 | ingress | tcp | 6443 | cluster SG | webhook |
| 4 | ingress | tcp | 8443 | cluster SG | webhook |
| 5 | ingress | tcp | 9443 | cluster SG | webhook |
| 6 | ingress | tcp | 10250 | cluster SG | kubelet |
| 7 | ingress | tcp | 10251 | cluster SG | metrics-server |
| 8 | ingress | tcp | 53 | self | CoreDNS |
| 9 | ingress | udp | 53 | self | CoreDNS |
| 10 | ingress | tcp | 1025-65535 | self | non-privileged 전체 (NCCL 포함) |
| - | egress | all | all | 0.0.0.0/0 | 아웃바운드 전체 허용 |
10번 규칙이 핵심이다. 1025-65535는 비특권(non-privileged) 포트 전체에 해당한다. OS의 ephemeral 범위(Linux 기본 32768-60999)보다 넓게 잡은 이유는, NodePort 서비스(30000-32767)나 애플리케이션이 명시적으로 바인드하는 포트 등 ephemeral 범위 바깥의 노드 간 통신까지 커버하기 위해서다. self-reference이므로 같은 SG 내 노드끼리만 허용되어 외부 노출 위험은 없다.
NCCL 맥락에서 보면, NCCL은 소켓 모드에서 일반 TCP 연결로 GPU 간 집합 통신(AllReduce, AllGather 등)을 수행한다. 이때 양쪽 노드의 OS가 ephemeral 범위에서 임의로 포트를 할당하므로, 특정 포트 하나만 열어서는 통신이 성립하지 않는다. 이 규칙이 비특권 포트 전체를 허용하고 있기 때문에 NCCL이 어떤 포트를 잡든 통과한다.
이전 글에서 node_security_group_enable_recommended_rules=false로 이 규칙을 내리면 NCCL 차단을 재현할 수 있다고 설명했다. 이 baseline이 원복 기준점이 된다.
보조 보안그룹 + 클러스터 보안그룹
aws ec2 describe-security-groups --group-ids \
"$(terraform output -raw auxiliary_node_sg_id)" \
"$(terraform output -raw cluster_security_group_id)"
| 보안그룹 | ingress | egress |
|---|---|---|
보조 SG (myeks5w-node-group-sg) |
VPC 대역(192.168.0.0/16) all traffic |
all 0.0.0.0/0 |
| 클러스터 SG | node SG → 443 (node → API server) | all 0.0.0.0/0 |
보조 SG의 VPC 대역 all-traffic ingress가 enable_aux_sg_vpc_allow=true(기본값)로 열려 있다. 이 규칙도 NCCL 차단 실험 시 false로 내리는 대상이다. 보조 SG의 egress all은 node_sg_enable_recommended_rules=false 시 노드 SG의 egress_all이 함께 빠지는 부작용에 대한 안전망이다.
VPC 토폴로지
aws ec2 describe-subnets --filters "Name=vpc-id,Values=$(terraform output -raw vpc_id)"
| 서브넷 | CIDR | AZ | 유형 |
|---|---|---|---|
| Public-1 | 192.168.0.0/22 | ap-northeast-2a | 퍼블릭 |
| Public-2 | 192.168.4.0/22 | ap-northeast-2b | 퍼블릭 |
| Public-3 | 192.168.8.0/22 | ap-northeast-2c | 퍼블릭 |
| Private-1 | 192.168.12.0/22 | ap-northeast-2a | 프라이빗 |
| Private-2 | 192.168.16.0/22 | ap-northeast-2b | 프라이빗 |
| Private-3 | 192.168.20.0/22 | ap-northeast-2c | 프라이빗 |
VPC 192.168.0.0/16, 퍼블릭 3 + 프라이빗 3, NAT Gateway 1개 구성이다. GPU 노드가 배치될 서브넷은 Private-1(192.168.12.0/22, ap-northeast-2a)이다. terraform output gpu_subnet_az가 ap-northeast-2a인 것과 일치한다.
CoreDNS 분산
kubectl -n kube-system get pods -l k8s-app=kube-dns -o wide
NAME READY STATUS AGE IP NODE
coredns-7b7dc46964-xxxxx 1/1 Running 11m 192.168.23.xxx ip-192-168-yy-yy... # AZ 2c
coredns-7b7dc46964-yyyyy 1/1 Running 11m 192.168.12.xxx ip-192-168-xx-xx... # AZ 2a
CoreDNS 2 pod가 서로 다른 AZ(2a, 2c)의 프라이빗 서브넷에 분산 배치되어 있다. 한쪽 AZ에 장애가 발생해도 DNS 서비스가 유지된다.
GPU Operator 렌더 프리뷰
enable_gpu_operator=false이므로 실제 설치는 하지 않는다. Helm chart 정보만 미리 확인한다.
차트 검색
helm search repo nvidia/gpu-operator --versions | head
NAME CHART VERSION APP VERSION DESCRIPTION
nvidia/gpu-operator v26.3.1 v26.3.1 NVIDIA GPU Operator creates/configures/manages ...
nvidia/gpu-operator v26.3.0 v26.3.0 NVIDIA GPU Operator creates/configures/manages ...
nvidia/gpu-operator v25.10.1 v25.10.1 NVIDIA GPU Operator creates/configures/manages ...
nvidia/gpu-operator v25.10.0 v25.10.0 NVIDIA GPU Operator creates/configures/manages ...
이전 글에서 선택한 v26.3.1이 최신 stable이다.
차트 메타데이터
helm show chart nvidia/gpu-operator --version v26.3.1
apiVersion: v2
appVersion: v26.3.1
dependencies:
- condition: nfd.enabled
name: node-feature-discovery
repository: oci://registry.k8s.io/nfd/charts
version: 0.18.3
name: gpu-operator
version: v26.3.1
NFD(Node Feature Discovery) 0.18.3이 subchart으로 의존된다. nfd.enabled=true(기본값)이면 GPU Operator와 함께 설치된다.
렌더 프리뷰
helm template gpu-operator nvidia/gpu-operator --version v26.3.1 \
-n gpu-operator --create-namespace \
--set driver.enabled=false \
--set toolkit.enabled=false
실제 설치 없이 생성될 K8s 리소스를 미리 확인한다. 렌더 결과를 리소스 타입별로 정리하면 다음과 같다.
| 출처 | 리소스 종류 | 개수 |
|---|---|---|
| GPU Operator | ServiceAccount, ClusterRole, ClusterRoleBinding, Role, RoleBinding, Deployment(operator), ClusterPolicy | 7 |
| GPU Operator | Job (CRD upgrade) | 4 |
| NFD subchart | ServiceAccount, ClusterRole(×2), ClusterRoleBinding(×2), Role, RoleBinding, ConfigMap(×2), DaemonSet(worker), Deployment(master, gc) | 13 |
| NFD subchart | Job (post-delete) | 4 |
총 27개 리소스가 Helm에서 직접 생성된다. 여기서 핵심은 ClusterPolicy 1개다. GPU Operator는 이 ClusterPolicy CRD를 watch하고, 런타임에 다음 컴포넌트를 자동 생성한다.
- NVIDIA Device Plugin DaemonSet
- DCGM Exporter DaemonSet
- GPU Feature Discovery DaemonSet
- Validator DaemonSet
- MIG Manager DaemonSet
즉, Helm chart이 직접 생성하는 27개 리소스에는 device-plugin, dcgm, driver 등이 포함되어 있지 않다. 이들은 Operator 컨트롤러가 ClusterPolicy를 reconcile하면서 런타임에 만드는 것이다.
현재 Helm release 확인
helm list -A
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
enable_gpu_operator=false이므로 release가 0개다. 의도대로다.
정리
배포 결과 요약
| 항목 | 값 |
|---|---|
| EKS 클러스터 | myeks5w, v1.35.3-eks-bbe087e, ACTIVE |
| 생성 리소스 | 84개, ~14분 소요 |
| 시스템 노드 | t3.medium × 2 (AZ 2a, 2c 분산) |
| GPU 노드 | g5.xlarge × 0 (desired=0) |
| 애드온 | 7종 ACTIVE (coredns, kube-proxy, vpc-cni, metrics-server, external-dns, pod-identity-agent, cert-manager) |
| 보안그룹 | 클러스터 SG + 노드 SG(ingress 10, egress 1) + 보조 SG |
| VPC | 192.168.0.0/16, Public×3 + Private×3, NAT 1개 |
| OIDC Provider | 등록 완료 (IRSA 준비) |
| Helm release | 0개 (GPU Operator 미설치) |
| LoadBalancer | 0개 |
비용 가드 동작 확인
gpu_desired_size=0, enable_gpu_operator=false, LB 0개, NAT 1개 상태에서의 예상 일 기반 비용이다.
| 항목 | 예상 비용 |
|---|---|
| EKS 컨트롤 플레인 | ~$2.4/일 |
| NAT Gateway | ~$1.6/일 |
| t3.medium × 2 | ~$2.0/일 |
| 합계 | ~$6/일 |
시리즈 개요에서 추정한 기반 소계(~$6.5/일)와 대략 일치한다. GPU 노드가 0대이므로 실습 유휴 시간에 최소 비용으로 클러스터를 유지할 수 있다.
다음 단계
이 기반 인프라 위에서 다음 순서로 GPU 실습을 진행한다.
- GPU 노드 기동:
aws eks update-nodegroup-config --scaling-config desiredSize=2 - GPU Operator 설치:
terraform apply -var enable_gpu_operator=true - NCCL 통신 확인: GPU 노드 간 멀티노드 통신 테스트
- 보안그룹 차단 실험:
enable_aux_sg_vpc_allow=false,node_sg_enable_recommended_rules=false로 NCCL 차단 재현 - 실습 종료:
aws eks update-nodegroup-config --scaling-config desiredSize=0으로 GPU 노드 종료
GPU 노드 스케일 up/down(Step 1, 5)이 Terraform이 아닌 AWS CLI인 이유는 이전 글을 참고한다.

댓글남기기